
Recent advances in neural networks have generated considerable excitement about AI. But AI is not all about neural networks. Other avenues in AI research tackle problems such as building effective models of the world or logical reasoning and are especially useful for dealing with the limitations of neural networks. In this post, we examine one specific problem in AI: planning.
What is AI planning? One simple definition is that planning is an exploration to decide what actions need to be taken to achieve a given goal.

The result of a planning process (i.e., the plan) is a collection of actions that would take us from the current (also known as the initial) state to a goal state.
AI planning is about how to teach a machine to plan ahead. We traditionally assume that it is easy to specify the goal / problem to the planning system. However, in the real world, problems are often specified informally using natural language which may be difficult for the planning system to understand.
Boosting the ability to understand problems is key in the ambitious journey towards making AI planning part of everyone's life. For instance, imagine a virtuoso personal assistant, capable of tasks like optimizing our daily routine, planning a vacation, project planning or even something as large as planning our professional career. This would require the ability to understand our desires in a very diverse range of situations. It would require, among other capabilities, the capability of building planning models automatically either from example solutions or from problem descriptions in natural language. Technologies such as machine learning, natural language processing, and AI planning need to work together to achieve such complex functionality.
In this blog post we will explore the following questions:
- How learning and planning complement each other
- What advantages do humans have over artificial intelligence?
- When should planning be used for AI?
- How can we get an agent to work well in many different domains?
Learning and Planning
There is no question that both learning and reasoning are two key components of human intelligence. Learning allows us to leverage past experiences in novel everyday activities. Planning, as a form of reasoning, allows us to plan a sequence of future actions to achieve a specific goal. Thus, in a sense, planning is complementary to learning, as one is an exploration into the future, and the other is about absorbing lessons from past experience.
As humans, we plan a lot, both in our personal lives and at work. Note that plans are solutions that typically involve many steps (or actions, or decisions). For example, planning a vacation includes taking care of all travel details, the hotel, the attractions to visit, the activities to perform etc. In contrast, some machine learning problems, such as image classification, can be seen as having one-decision solutions.
Humans plan so often precisely because new problems require solutions that are not perfectly identical to past experiences. AI may benefit similarly. The literature reports many contributions where learning is used with the purpose of making AI planning more efficient, in the sense of solving problems faster and scaling to larger problems. This is just one example about how planning and learning can be combined together. In this vein, learning can generate macro-operators to be used for a faster and more scalable problem solving process (e.g., [1]). Learning has been leveraged to decide what planner to use to attack a given problem, from a portfolio of available planners (where the portfolio could also include several variants of one planning system, for example with different running settings).[2] Learning can tune internal planning heuristics,[3] and can be used to complete the definition of domain knowledge that can speed up planning, such as hierarchical task networks.[4] The International Conference on Automated Planning and Scheduling (ICAPS), the top scientific conference focused on AI planning and scheduling, has a permanent track on planning and learning, which has a far more comprehensive range of topics than we can cover in this short blog post.
Human vs Artificial Intelligence
Comparing AI approaches and capabilities of human intelligence is a useful exercise, since we can use human intelligence as a point of reference for evaluating a given AI technique. Of course, this is not to say that human intelligence is necessarily the ground truth and that AI should necessarily aim at mirroring human intelligence. Rather, the comparison may give us some useful insights about what parts of AI are more developed and what parts need a stronger level of attention in the future.
Take for example the subarea of learning. One fairly popular view is that AI learning appears to be fundamentally different from human learning. Humans learn from very few examples. Humans can generalize very well from one or a few concrete examples to more abstract patterns, and they can take into account the mechanics of the world around us, with dynamic changes, causes and effects.
In contrast, current AI learning has been called greedy, brittle and shallow. It is greedy because most deep learning methods require large volumes of training data. It is brittle because of limited generalization power. It is shallow because neural networks have a far narrower knowledge of commonsense compared to most humans.[5] Thus, knowing the differences can help define long-term objectives for AI, where achieving human (or superhuman) performance is often seen as a holy grail milestone.
Just like learning, planning is a defining capability of human intelligence and a decades-old subject in AI. A comparison of AI planning vs human planning is therefore equally important and insightful. To dive into this topic, we split the human planning task into two parts: formulating the problem and solving the problem.
Forming the Problem
Humans have an astonishing ability to formulate planning problems effectively. As humans we know how to choose an appropriate abstraction level, what details of the reality around us to keep as relevant, and what details to ignore at a given abstraction level. This is something that proves difficult for machines. In such cases, the ability to recognize the problem and express it is a key advantage that humans have.

However, there will be problem instances where even skillful abstractions leave the problem hard to solve to a human. Examples include computing an optimal itinerary for a road trip, optimizing the movements of a team of mobile robots sharing a navigation environment, testing vulnerabilities in a computer network etc. Games and puzzles are excellent examples of domains where finding a solution (i.e., solving the puzzle or playing the game well) can be difficult. Many hard planning problems are combinatorial. They are inherently difficult for humans, as they may require enumerating many possible combinations, especially when the focus is on constructing optimal or nearly-optimal solutions.
A similar pattern can be painted in the case of using automated planning. The way the problem is formulated can go a long way towards helping the planning system compute solutions faster and scale to larger problems. Yet, many planning domains have a high computational complexity (for example, solving the sliding-tile puzzle optimally, with a shortest number of moves, boils down to an NP-hard problem.[6]) As such, regardless of the quality of the problem formulation and the planning system, in planning we can experience computationally difficult instances.
In the comparison between defining the planning problem and solving the planning problem, it looks like the science is more advanced in terms of solving a (well formulated) problem, as compared to formulating the problem in the first place. For the problem formulation, we still rely heavily on human expertise, despite good steps taken towards automatically formulating planning problems, including the few examples given below.
The capability of building planning models automatically either from example solutions or from problem descriptions in natural language would be key to dynamically adapt to new situations. Existing contributions along these lines include the automated extraction of parts of the formal planning problem from natural language (e.g., [7][8]). Other related work has focused on learning action models from traces of actions[9] and examples,[10] and on understanding plans and models from images representing states before and after an action is applied[11]. Overall, we would like to stress the importance of automatically understanding and formulating problems as a direction for future research.
Thinking Fast And Slow
Some have compared machine learning to Daniel Kahneman's system one, the fast, intuitive part of the brain that responds to inputs. In AI, patterns created as a result of learning can be used to trigger fast reactions to a given input.[12] On the other hand, AI planning could be key to supporting the system two function which is the slow, deliberate and more logical thinking involved in longer term decision making.

How visible the AI system one (i.e., learning) and the AI system two (reasoning) are in the eyes of the general public? Examine recent advances in learning in domains like vision, speech recognition and natural language understanding. It is now possible to speak to our voice activated smartphone and call a friend or to use Google's translation tool to order food from a restaurant menu in a different language.
A system such as AlphaGo, that has achieved an impressive breakthrough in playing the game of Go at a superhuman strength, is an excellent example of a combination of system one and system two. Both appear to be crucially important. However, arguably, the learning component is more prominent in the general perception. After all, AlphaGo is described as a reinforcement learning technique. To a non-expert audience exposed only to such a succinct description, the learning part is explicitly mentioned, whereas the exploration ahead is not. This suggests that perhaps the AI research community should work on better promoting the importance of system two technologies as well.
When Should We Plan?
To use AI planning a practitioner first needs to decide whether their problem requires planning at all! Detailed guidelines about making this decision is beyond the scope of this post, but the properties discussed in this section appear to be fairly widely brought up when characterizing planning problems.
First, check if the task is about achieving a goal or an objective. Current learning technologies often need to receive the goal in their training phase, because they attempt to accumulate experiences to achieve the goal. If the goal in the solving phase is different from that in the training phase, the model learned in the training phase will not be an effective guide in the testing phrase.
Secondly, ask whether the solution to the problem at hand requires multiple steps. An image classification problem would be an example of a one step problem. The classifier takes as input one image, and it outputs a label such as bird. Planning is only useful when a single step is not sufficient to achieve the goal.
A plan typically contains many actions, as a subset of the contained actions would be insufficient on their own to achieve the goal. This is not to say that AI planning is the only technology capable of creating multi-action solutions. Reinforcement learning can chain actions, thanks to its exploration part. A policy in a Markov Decision Process includes a collection of actions. Optimization modeling can represent multiple actions as one Boolean decision variable each, and variables set to true in a solution would correspond to actions to perform.
Thirdly, ask whether training data is available. Planning does not require training, or the availability of training data. Of course, training can help, in which case we talk about a combination of learning and planning ahead (AlphaGo and AlphaZero[13] are prominent examples where learning and lookahead exploration work together. A few examples about combining learning and planning have been presented earlier in our post.) The bottom line, however, is that in planning a definition of the problem expressed in a given language, is sufficient to get us started with solving the problem. This is very handy when no (good) training data can be found or when data does not lead to successfully learning a good model of the problem.
Fourthly, ask whether the input size of the task is static or arbitrary. Planning supports an arbitrary input size that is specific to each problem instance (or task). On the other hand, many learning methods require a fixed-size input, which needs to be consistent between the training and the solving phases. For example, AlphaZero would need to be trained separately for different Go board sizes, such as 9x9 and 19x19.
One Planner, Many Problems?
In AI planning research, the so-called domain-independent planning is particularly fascinating. Domain independence means that the same solver can be used to tackle many types of problems which might be very different from each other. A domain-independent planner requires only that we express the problem in a standard input language that the planner understands (the AI planning community primarily uses variants of a language called PDDL). No domain-specific expertise needs to be programmed or otherwise provided to a domain-independent planner.
Domain-independent planning is based on a so-called symbolic problem representation. Put simply, we describe the universe of a problem with facts that, at a given point in time, can be either true or false. For instance, a fact such as have flour would be relevant to a planning problem where we want to bake a cake. In some states of the problem the fact have flour can be true (e.g., after performing the action buy flour), and in some other states the fact can be false. A state of the planning problem is characterized by a true/false assignment to all facts defined in our problem at hand. (As presented here, states are defined with binary variables, namely the facts. A popular approach generalizes the state representation from binary facts to variables with multi-valued domains, which is beyond our focus here.)
We start from an initial state, given in the input, and want to reach a state where the goal holds. We can apply one action at a time, and the state changes as a result, by changing the true/false value of a (small) subset of facts. Such changes are called the effects of the action.
Not all actions are applicable in all states. Actions have preconditions (Boolean formulas based on a subset of facts), and an action is applicable in a given state if and only if its precondition holds in the state at hand. E.g., an action such as mix flour and milk would require a precondition such as have flour and have milk.
In the previous example, we have full knowledge about the state of the problem (i.e., we know the true/false value of all facts). Furthermore, actions have deterministic effects, which means that performing an action in a given state always has the same effect (e.g., we always have flour after applying action buy flour). Such properties, and a few others skipped for simplicity, characterize a planning setting called classical planning.
Quite a few extensions to classical planning have been studied in the literature, to cover broader scenarios, such as incomplete knowledge about the state of the problem, or the fact that actions can have nondeterministic effects (see an example later in this section). Other extensions revolve around numerical planning (where we can reason about numerical values, in addition to symbolic reasoning); temporal planning (where actions can have a duration, and actions can occur in parallel); multi-agent planning and planning under uncertainty.
Professor Hector Geffner's keynote speech at IJCAI-ECAI-18[14] (two major AI scientific conferences that were held together in 2018) pointed out that while reinforcement learning has successfully addressed very challenging domains, such as Go and Chess, it faces difficulties in domains much simpler to a human, such as Blocksworld. In Blocksworld, an agent has to rearrange a few cubes from one configuration to another configuration. Blocksworld is often used as a testbed domain in AI planning, and domain-independent planning systems are effective at solving this problem. This is a demonstration of the complementary strengths of RL and model-based planning.
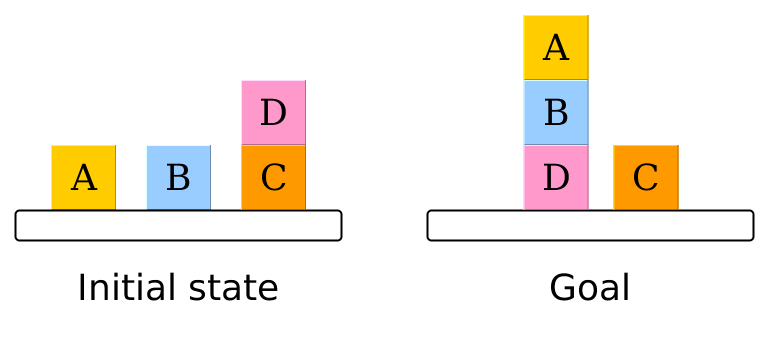
In domain-independent planning, the ability to solve a diverse range of problems with domain-independent planning comes at a price. Solving a problem in a domain-independent manner is more challenging than using knowledge specific to the problem in the solving process. The good news is that practitioners can resort to readily available solving tools. An active and sizeable research community contributes to progress in domain-independent planning. Domain-independent planning systems require both models and general, scalable algorithms. An ongoing research quest focuses on more efficient search algorithms that could scale to larger and larger problems.
In nondeterministic planning, an established area, actions (i.e., steps in a plan) can have nondeterministic effects. For instance, attempting to catch a connection (bus) in a public transport network can either succeed or fail, depending on the arrival time of the user at the stop, and the departure time of the bus from the stop. In a journey planning problem, this is an example of a nondeterministic action. More than one outcome are possible (in this example two potential outcomes exist: success and failure). Plans with nondeterministic actions allow us to be prepared for contingencies. Thus, nondeterministic planning is useful for solving problems where we do not have total certainty about what will happen in real life when we execute the actions of a given plan.
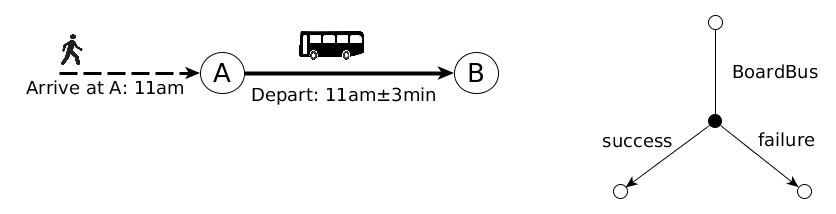
Recent contributions from our group are concentrated on heuristic search algorithms that compute optimal plans to nondeterministic problems and operate efficiently within restricted memory requirements.[15]
Our system has been used for career coach mentoring, where a sequential career plan is generated based on user profiles, and to compute a plan for a dialogue between a user and a chatbot.[16] To see a more comprehensive picture of AI planning work at IBM Research, visit
our AI planning website.

Conclusion
In this post, we give a high-level introduction to AI planning, a technology useful when the task is to achieve a goal, and one single step (or action, or decision) is not sufficient. Planning does not require training, or the availability of training data, but combining planning and learning can be beneficial. Both the goal and the size of the input can change from one problem instance to another, and the planning system does not require any adaptation (e.g., training) to attack a new problem instance. Further progress with automatically understanding planning problems (e.g., from natural language descriptions) would facilitate a stronger adoption of AI planning among users. After all, intelligence is not only about solving problems. It is also about understanding what the problems are, and how important a problem is.
Adi Botea, Akihiro Kishimoto, Radu Marinescu and Elizabeth Daly
IBM Research, Ireland
Interactive AI Research Group
Special thanks to Andrey Kurenkov, Simone Totaro, Mirantha Jayathilaka, and Hugh Zhang for their feedback, suggestions, and insights.
Cover image source
Citation
For attribution in academic contexts or books, please cite this work as
Adi Botea, Akihiro Kishimoto, Radu Marinescu and Elizabeth Daly, "When AI Plans Ahead", The Gradient, 2019.
BibTeX citation:
@article{IBMAIahead2019,
author = {IBM Research}
title = {When AI Plans Ahead},
journal = {The Gradient},
year = {2019},
howpublished = {\url{https://thegradient.pub/when-ai-plans-ahead/ } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.
A. Botea, M. Enzenberger, M. Mueller, J. Schaeffer. Macro-FF: Improving AI Planning with Automatically Learned Macro-Operators. Journal of AI Research. 2005. ↩︎
M. Katz, S. Sohrabi, H. Samulowitz, S. Sievers. Delfi: Online planner selection for cost-optimal planning. In Ninth International Planning Competition (IPC-9). 2008. ↩︎
S. Yoon, A. Fern, R. Givan. Learning Heuristic Functions from Relaxed Plans. In Proceedings of the International Conference on Automated Planning and Scheduling. 2006. ↩︎
C. Hogg, U. Kuter, H. Munoz-Avila. Learning Hierarchical Task Networks for Nondeterministic Planning Domains. In Proceedings of the International Joint Conference on AI. 2009. ↩︎
J. Pontin. Greedy, Brittle, Opaque, and Shallow: The Downsides to Deep Learning ↩︎
D. Ratner, M. Warrnuth. Finding a Shortest Solution for the NxN Extension of the 15-Puzzle is Intractable. In Proceedings of AAAI. 1986. ↩︎
A. Lindsay, J. Read, J. F. Ferreira, T. Hayton, J. Porteous, P. Gregory. Framer: Planning Models from Natural Language Action Descriptions. In Proceedings of the International Conference on Automated Planning and Scheduling. 2017. ↩︎
L. Manikonda, S. Sohrabi, K. Talamadupula, B. Srivastava, S. Kambhampati. Extracting Incomplete Planning Action Models from Unstructured Social Media Data to Support Decision Making. Workshop on Knowledge Engineering for Planning and Scheduling KEPS-17. 2017. ↩︎
S. Cresswell, T. McCluskey, M. West. Acquisition of Object-Centred Domain Models from Planning Examples. In Proceedings of the International Conference on Automated Planning and Scheduling. 2009. ↩︎
D. Aineto, S. Jimenez, E. Onaindia. Learning STRIPS Action Models with Classical Planning. In Proceedings of the International Conference on Automated Planning and Scheduling. 2018. ↩︎
M. Asai, A. Fukunaga. Classical Planning in Deep Latent Space: Bridging the Subsymbolic-Symbolic Boundary. In Proceedings or AAAI. 2018. ↩︎
I. Gurari. Machines Thinking Fast And Slow ↩︎
H. Gaffner. IJCAI-ECAI-18 ↩︎
A. Kishimoto, A. Botea, R. Marinescu. Depth-First Memory-Limited AND/OR Search and Unsolvability in Cyclic Search Spaces. In Proceedings of the International Joint Conference on Artificial Intelligence, IJCAI. 2019 ↩︎
A. Botea, C. Muise, S. Agarwal, O. Alkan, O. Bajgar, E. Daly, A. Kishimoto, L. Lastras, R. Marinescu, J. Ondrej, P. Pedemonte and M. Vodolan, Generating Dialogue Agents via Automated Planning. In Proceedings of the AAAI-19 Workshop DeepDial-19. https://arxiv.org/abs/1902.00771. 2019 ↩︎



{kind=link}
{kind=link}
{kind=link}
{kind=link}