
A mystery
Large Language Models (LLM) are on fire, capturing public attention by their ability to provide seemingly impressive completions to user prompts (NYT coverage). They are a delicate combination of a radically simplistic algorithm with massive amounts of data and computing power. They are trained by playing a guess-the-next-word game with itself over and over again. Each time, the model looks at a partial sentence and guesses the following word. If it makes it correctly, it will update its parameters to reinforce its confidence; otherwise, it will learn from the error and give a better guess next time.
While the underpinning training algorithm remains roughly the same, the recent increase in model and data size has brought about qualitatively new behaviors such as writing basic code or solving logic puzzles.
How do these models achieve this kind of performance? Do they merely memorize training data and reread it out loud, or are they picking up the rules of English grammar and the syntax of C language? Are they building something like an internal world model—an understandable model of the process producing the sequences?
From various philosophical [1] and mathematical [2] perspectives, some researchers argue that it is fundamentally impossible for models trained with guess-the-next-word to learn the “meanings'' of language and their performance is merely the result of memorizing “surface statistics”, i.e., a long list of correlations that do not reflect a causal model of the process generating the sequence. Without knowing if this is the case, it becomes difficult to align the model to human values and purge spurious correlations picked up by the model [3,4]. This issue is of practical concern since relying on spurious correlations may lead to problems on out-of-distribution data.
The goal of our paper [5] is to explore this question in a carefully controlled setting. As we will discuss, we find interesting evidence that simple sequence prediction can lead to the formation of a world model. But before we dive into technical details, we start with a parable.
A thought experiment
Consider the following thought experiment. Imagine you have a friend who enjoys the board game Othello, and often comes to your house to play. The two of you take the competition seriously and are silent during the game except to call out each move as you make it, using standard Othello notation. Now imagine that there is a crow perching outside of an open window, out of view of the Othello board. After many visits from your friend, the crow starts calling out moves of its own—and to your surprise, those moves are almost always legal given the current board.
You naturally wonder how the crow does this. Is it producing legal moves by "haphazardly stitching together” [3] superficial statistics, such as which openings are common or the fact that the names of corner squares will be called out later in the game? Or is it somehow tracking and using the state of play, even though it has never seen the board? It seems like there's no way to tell.
But one day, while cleaning the windowsill where the crow sits, you notice a grid-like arrangement of two kinds of birdseed--and it looks remarkably like the configuration of the last Othello game you played. The next time your friend comes over, the two of you look at the windowsill during a game. Sure enough, the seeds show your current position, and the crow is nudging one more seed with its beak to reflect the move you just made. Then it starts looking over the seeds, paying special attention to parts of the grid that might determine the legality of the next move. Your friend, a prankster, decides to try a trick: distracting the crow and rearranging some of the seeds to a new position. When the crow looks back at the board, it cocks its head and announces a move, one that is only legal in the new, rearranged position.
At this point, it seems fair to conclude the crow is relying on more than surface statistics. It evidently has formed a model of the game it has been hearing about, one that humans can understand and even use to steer the crow's behavior. Of course, there's a lot the crow may be missing: what makes a good move, what it means to play a game, that winning makes you happy, that you once made bad moves on purpose to cheer up your friend, and so on. We make no comment on whether the crow “understands” what it hears or is in any sense “intelligent”. We can say, however, that it has developed an interpretable (compared to in the crow’s head) and controllable (can be changed with purpose) representation of the game state.
Othello-GPT: a synthetic testbed
As a clever reader might have already guessed, the crow is our subject under debate, a large language model.
We are looking into the debate by training a GPT model only on Othello game scripts, termed Othello-GPT. Othello is played by two players (black and white), who alternatively place discs on an 8x8 board. Every move must flip more than one opponent's discs by outflanking/sandwiching them in a straight line. Game ends when no moves could be made and the player with more discs on the board wins.
We choose the game Othello, which is simpler than chess but maintains a sufficiently large game tree to avoid memorization. Our strategy is to see what, if anything, a GPT variant learns simply by observing game transcripts without any a priori knowledge of rules or board structure.
It’s worth pointing out a key difference between our model and Reinforcement Learning models like AlphaGo: to AlphaGo, game scripts are the history used to predict the optimal best next move leading to a win, so the game rule and board structures are baked into it as much as possible; in contrast, game scripts is no different from sequences with a unique generation process to Othello-GPT and to what extent the generation process can be discovered by a large language model is exactly what we are interested in. Therefore, unlike AlphaGo, no knowledge of board structure or game rules is given. The model is rather trained to learn to make legal moves only from lists of moves like: E3, D3, C4… Each of the tiles is tokenized as a single word. The Othello-GPT is then trained to predict the next move given the preceding partial game to capture the distribution of games (sentences) in game datasets.
We found that the trained Othello-GPT usually makes legal moves. The error rate is 0.01%; and for comparison, the untrained Othello-GPT has an error rate of 93.29%. This is much like the observation in our parable that the crow was announcing the next moves.
Probes
To test this hypothesis, we first introduce probing, an established technique in NLP [6] to test for internal representations of information inside neural networks. We will use this technique to identify world models in a synthetic language model if they exist.
The heuristic is simple: for a classifier with constrained capacity, the more informative its input is for a certain target, the higher accuracy it can achieve when trained to predict the target. In this case, the simple classifiers are called probes, which take different activations in the model as input and are trained to predict certain properties of the input sentence, e.g., the part-of-speech tags and parse tree depth. It’s believed that the higher accuracy these classifiers can get, the better the activations have learned about these real-world properties, i.e., the existence of these concepts in the model.
One early work [7] probed sentence embeddings with 10 linguistic properties like tense, parsing tree depth, and top constituency. Later people found that syntax trees are embedded in the contextualized word embeddings of BERT models [8].
Back to the mystery on whether large language models are learning surface statistics or world models, there have been some tantalizing clues suggesting language models may build interpretable “world models” with probing techniques. They suggest language models can develop world models for very simple concepts in their internal representations (layer-wise activations), such as color [9], direction [10], or track boolean states during synthetic tasks [11]. They found that the representations for different classes of these concepts are easier to separate compared to those from randomly-initialized models. By comparing probe accuracies from trained language models with the probe accuracies from randomly-initialized baseline, they conclude that the language models are at least picking up something about these properties.
Probing Othello-GPT
As a first step of looking into it, we apply probes to our trained Othello-GPT. For each internal representation in the model, we have a ground truth board state that it corresponds to. We then train 64 independent two-layer MLP classifiers to classify each of the 64 tiles on Othello board into three states, black, blank, and white, by taking the internal representations from Othello-GPT as input. It turns out that the error rates of these probes are reduced from 26.2% on a randomly-initialized Othello-GPT to only 1.7% on a trained Othello-GPT. This suggests that there exists a world model in the internal representation of a trained Othello-GPT. Now, what is its shape? Do these concepts organize themselves in the high-dimensional space with a geometry similar to their corresponding tiles on an Othello board?
Since the probe we trained for each tile essentially keeps its knowledge about the board with a prototype vector for that tile, we interpret it as the concept vector for that tile. For the 64 concept vectors at hand, we apply PCA to reduce the dimensionality to 3 to plot the 64 dots below, each corresponding to one tile on the Othello board. We connect two dots if the two tiles they correspond to are direct neighbors. If the connection is horizontal on board, we color it with an orange gradient palette, changing along with the vertical position of the two tiles. Similarly, we use a blue gradient palette for vertical connections. Dots for the upper left corner ([0, 0]) and lower right corner ([7, 7]) are labeled.
By contrasting with the geometry of probes trained on a randomly-initialized GPT model (left), we can confirm that the training of Othello-GPT gives rise to an emergent geometry of “draped cloth on a ball” (right), resembling the Othello board.
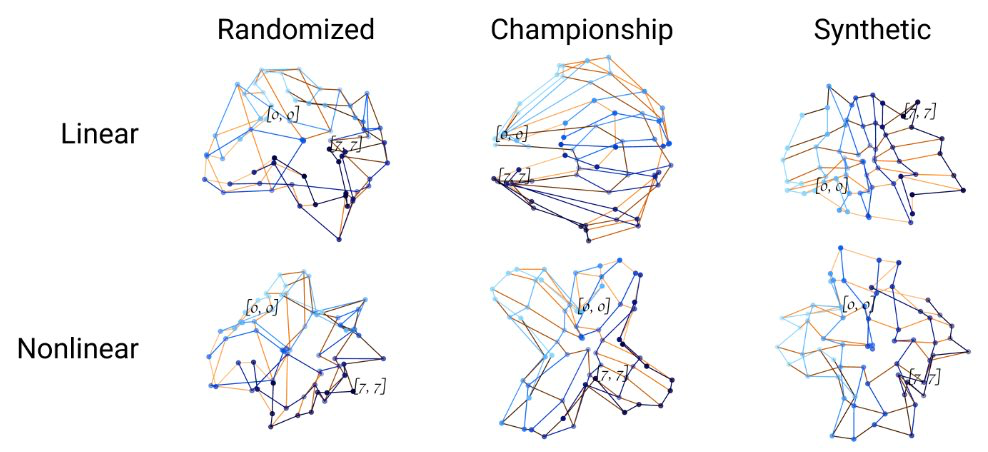
Finding these probes is like discovering the board made of seeds on the crow's windowsill. Their existence excites us but we are not yet sure if the crow is relying on them to announce the next moves.
Controlling model predictions via uncovered world models
Remember the prank in the thought experiment? We devise a method to change the world representation of Othello-GPT by changing its intermediate activations as the neural network computes layer by layer, on the fly, in the hope that the next-step predictions of the model can be changed accordingly as if made from this new world representation. This addresses some potential criticisms that these world representations are not actually contributing to the final prediction of Othello-GPT.
The following picture shows one such intervention case: on the bottom left is the world state in the model’s mind before the intervention, and to its right is the post-intervention world state we chose and the consequent post-intervention made by the model. What we are thinking of doing is flipping E6 from black to white and hope the model will make different next-step predictions based on the changed world state. This change in the world state will cause a change in the set of legal next moves according to the rule of Othello. If the intervention is successful, the model will change its prediction accordingly.
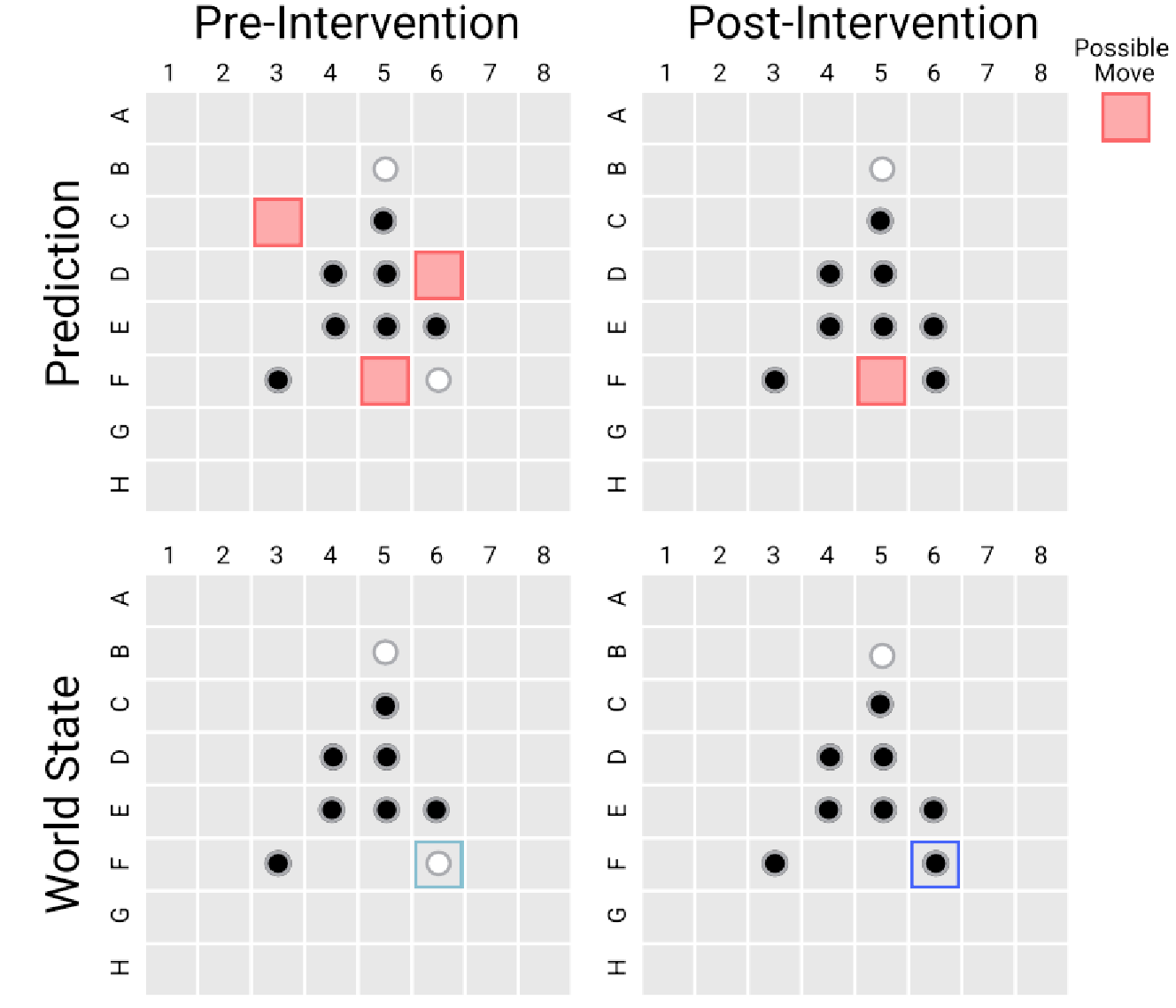
We evaluate this by comparing the ground-truth post-intervention legal moves returned by the Othello engine and those returned by the model. It turns out that it achieves an average error of only 0.12 tiles. It shows that the world representations are more than probable from the internal activations of the language model, but are also directly used for prediction. This ties back to the prank in the parable where moving the seeds around can change how the crow thinks about the game and makes the next move prediction.
A more stringent test is done by intervening the board state in the model’s mind into ones that are unreachable from any input sequences, e.g., boards with two disconnected blocks of discs. The idea is similar to Fischer random chess—players’ abilities are tested by playing under impossible board states in normal chess. The systematic evaluation result is equally good, which provides evidence that further disentangles the world model from sequence statistics.
An application for interpretability
Let’s take a step back and think about what such a reliable intervention technique brings to us. It allows us to ask the counterfactual question: what would the model predict if F6 were white, even no input sequence can ever lead to such a board state? It allows us to imaginarily go down the untaken path in the garden of forking paths.
Among many other newly-opened possibilities, we introduce the Attribution via Intervention method to attribute a valid next-step move to each tile on the current board and create “latent saliency maps” by coloring each tile with the the attribution score. It’s done by simply comparing the predicted probabilities between factual and counterfactual predictions (each counterfactual prediction is made by the model from the world state where one of the occupied tiles is flipped).
For instance, how do we get the saliency value for square D4 in the upper-left plot below? We first run the model normally to get the next-step probability predicted for D6 (the square we attribute); then we run the model again but intervene a white D4 to a black D4 during the run, and save the probability for D6 again; by taking the difference between the two probability values, we know how the current state of D4 is contributing to the prediction of D6. And the same process holds for other occupied squares.
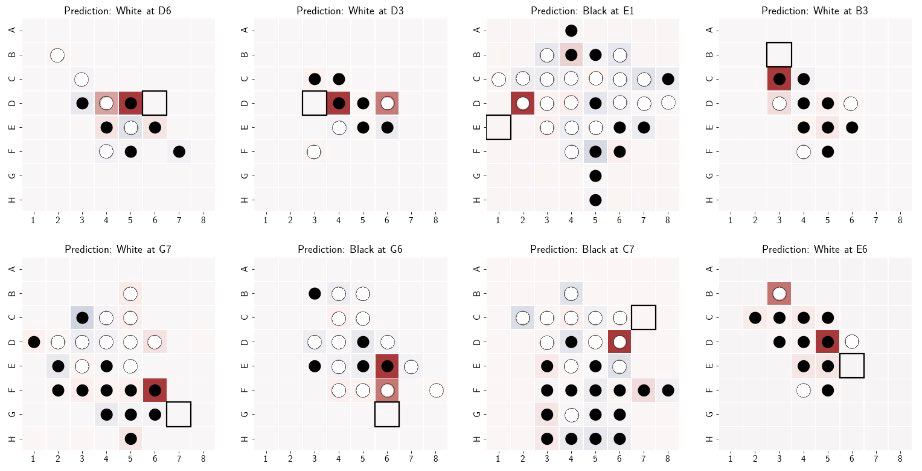
The figure below shows 8 such “latent saliency maps” made from Othello-GPT. These maps show that the method precisely attributes the prediction to tiles that make the prediction legal—the same-color at the other end of the straight-line “sandwich” and the tiles in between that are occupied by the opponent discs. From these saliency maps, an Othello player can understand Othello-GPT’s goal, to make legal moves; and a person who does not know Othello could perhaps induce the rule. Different from most existing interpretability methods, the heatmap created is not based on the input to the model but rather the model’s latent space. Thus we call it a “latent saliency map”.
Discussion: where are we?
Back to the question we have at the beginning: do language models learn world models or just surface statistics? Our experiment provides evidence supporting that these language models are developing world models and relying on the world model to generate sequences. Let’s zoom back and see how we get there.
Initially, in the set-up of Othello-GPT, we find that the trained Othello-GPT usually makes legal moves. I’d like to visualize where we are as follow:

, where two unrelated processes—(1) a human-understandable World Model and (2) a black-box neural network—reach highly consistent next-move predictions. This is not a totally surprising fact given we have witnessed so many abilities of large language models, but it’s a solid question to ask about the interplay between the mid-stage products from the two processes: the human-understandable world representations and the incomprehensible high-dimensional space in an LLM.
We first study the direction from internal activations to world representations. By training probes, we are able to predict world representations from the internal activations of Othello-GPT.

How is the other way around? We devised the intervention technique to change the internal activation so that it can represent a different world representation given by us. And we found this works concordantly with the higher layers of the language model—these layers can make next-move predictions solely based on the intervened internal activations without unwanted influence from the original input sequence. In this sense, we established a bidirectional mapping and opened the possibility of many applications, like the latent saliency map.

Putting these two links into the first flow chart, we’ve arrived at a deeply satisfying picture: two systems—a powerful yet black-box neural network and a human-understandable world model—not only predict consistently, but also share a unified mid-stage representation.

Still, many exciting open questions remain unanswered. In our work, the form of world representation (64 tiles, each with 3 possible states) and the game engine (game rule) are known. Can we reverse-engineer them rather than assuming knowing them? It’s also worth noting that the world representation (board state) serves as a “sufficient statistic” of the input sequence for next-move prediction. Whereas for real LLMs, we are at our best only know a small fraction of the world model behind. How to control LLMs in a minimally invasive (maintaining other world representations) yet effective way remains an important question for future research.
01/31/2023: Updated with the last paragraph in Section "Controlling model predictions via uncovered world models" to introduce the the more stringent intervention experiment in Section 4.2 of the paper but not in the original blog.
Acknowledgment
The author is grateful to Aspen Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister and Martin Wattenberg for providing suggestions and editing the text. Special thanks to Martin for the crow parable.
Citation
For attribution of this in academic contexts or books, please cite this work as:
Kenneth Li, "Do Large Language Models learn world models or just surface statistics?", The Gradient, 2023.
BibTeX citation (this blog):
author = {Li, Kenneth},
title = {Do Large Language Models learn world models or just surface statistics?},
journal = {The Gradient},
year = {2023},
howpublished = {\url{https://thegradient.pub/othello}},
}
BibTeX citation (the ICLR 23 paper that this blog is based on, code can be found here):
author={Li, Kenneth and Hopkins, Aspen K and Bau, David and Vi{\'e}gas, Fernanda and Pfister, Hanspeter and Wattenberg, Martin},
title={Emergent world representations: Exploring a sequence model trained on a synthetic task},
journal={arXiv preprint arXiv:2210.13382},
year = {2022},
}
References
[1] E. M. Bender and A. Koller, “Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, Jul. 2020, pp. 5185–5198. doi: 10.18653/v1/2020.acl-main.463.
[2] W. Merrill, Y. Goldberg, R. Schwartz, and N. A. Smith, “Provable Limitations of Acquiring Meaning from Ungrounded Form: What Will Future Language Models Understand?” arXiv, Jun. 22, 2021. Accessed: Dec. 04, 2022. [Online]. Available: http://arxiv.org/abs/2104.10809
[3] E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell, “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜,” in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, New York, NY, USA, Mar. 2021, pp. 610–623. doi: 10.1145/3442188.3445922.
[4] L. Floridi and M. Chiriatti, “GPT-3: Its Nature, Scope, Limits, and Consequences,” Minds & Machines, vol. 30, no. 4, pp. 681–694, Dec. 2020, doi: 10.1007/s11023-020-09548-1.
[5] K. Li, A. K. Hopkins, D. Bau, F. Viégas, H. Pfister, and M. Wattenberg, “Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task.” arXiv, Oct. 25, 2022. doi: 10.48550/arXiv.2210.13382.
[6] Y. Belinkov, “Probing Classifiers: Promises, Shortcomings, and Advances,” arXiv:2102.12452 [cs], Sep. 2021, Accessed: Mar. 31, 2022. [Online]. Available: http://arxiv.org/abs/2102.12452
[7] A. Conneau, G. Kruszewski, G. Lample, L. Barrault, and M. Baroni, “What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, Jul. 2018, pp. 2126–2136. doi: 10.18653/v1/P18-1198.
[8] J. Hewitt and C. D. Manning, “A Structural Probe for Finding Syntax in Word Representations,” p. 10.
[9] M. Abdou, A. Kulmizev, D. Hershcovich, S. Frank, E. Pavlick, and A. Søgaard, “Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color.” arXiv, Sep. 14, 2021. doi: 10.48550/arXiv.2109.06129.
[10] R. Patel and E. Pavlick, “MAPPING LANGUAGE MODELS TO GROUNDED CON- CEPTUAL SPACES,” p. 21, 2022.[10] B. Z. Li, M. Nye, and J. Andreas, “Implicit Representations of Meaning in Neural Language Models,” arXiv:2106.00737 [cs], Jun. 2021, Accessed: Dec. 09, 2021. [Online]. Available: http://arxiv.org/abs/2106.00737
[11] B. Z. Li, M. Nye, and J. Andreas, “Implicit Representations of Meaning in Neural Language Models,” arXiv:2106.00737 [cs], Jun. 2021, Accessed: Dec. 09, 2021. [Online]. Available: http://arxiv.org/abs/2106.00737

{kind=link}