
What is the Role of Mathematics in Modern Machine Learning?
The past decade has witnessed a shift in how progress is made in machine learning. Research involving carefully designed and mathematically principled architectures result in only marginal improvements while compute-intensive and engineering-first efforts that scale to ever larger training sets and model parameter counts result in remarkable new capabilities unpredicted by existing theory. Mathematics and statistics, once the primary guides of machine learning research, now struggle to provide immediate insight into the latest breakthroughs. This is not the first time that empirical progress in machine learning has outpaced more theory-motivated approaches, yet the magnitude of recent advances has forced us to swallow the bitter pill of the “Bitter Lesson” yet again [1].
This shift has prompted speculation about mathematics’ diminished role in machine learning research moving forward. It is already evident that mathematics will have to share the stage with a broader range of perspectives (for instance, biology which has deep experience drawing conclusions about irreducibly complex systems or the social sciences as AI is integrated ever more deeply into society). The increasingly interdisciplinary nature of machine learning should be welcomed as a positive development by all researchers.
However, we argue that mathematics remains as relevant as ever; its role is simply evolving. For example, whereas mathematics might once have primarily provided theoretical guarantees on model performance, it may soon be more commonly used for post-hoc explanations of empirical phenomena observed in model training and performance–a role analogous to one that it plays in physics. Similarly, while mathematical intuition might once have guided the design of handcrafted features or architectural details at a granular level, its use may shift to higher-level design choices such as matching architecture to underlying task structure or data symmetries.
None of this is completely new. Mathematics has always served multiple purposes in machine learning. After all, the translation equivariant convolutional neural network, which exemplifies the idea of architecture matching data symmetries mentioned above is now over 40 years old. What’s changing are the kinds of problems where mathematics will have the greatest impact and the ways it will most commonly be applied.
An intriguing consequence of the shift towards scale is that it has broadened the scope of the fields of mathematics applicable to machine learning. “Pure” mathematical domains such as topology, algebra, and geometry, are now joining the more traditionally applied fields of probability theory, analysis, and linear algebra. These pure fields have grown and developed over the last century to handle high levels of abstraction and complexity, helping mathematicians make discoveries about spaces, algebraic objects, and combinatorial processes that at first glance seem beyond human intuition. These capabilities promise to address many of the biggest challenges in modern deep learning.
In this article we will explore several areas of current research that demonstrate the enduring ability of mathematics to guide the process of discovery and understanding in machine learning.

Figure 1: Mathematics can illuminate the ways that ReLU-based neural networks shatter input space into countless polygonal regions, in each of which the model behaves like a linear map [2, 3, 4]. These decompositions create beautiful patterns. (Figure made with SplineCam [5]).
Describing an Elephant from a Pin Prick
Suppose you are given a 7 billion parameter neural network with 50 layers and are asked to analyze it; how would you begin? The standard procedure would be to calculate relevant performance statistics. For instance, the accuracy on a suite of evaluation benchmarks. In certain situations, this may be sufficient. However, deep learning models are complex and multifaceted. Two computer vision models with the same accuracy may have very different generalization properties to out-of-distribution data, calibration, adversarial robustness, and other “secondary statistics” that are critical in many real-world applications. Beyond this, all evidence suggests that to build a complete scientific understanding of deep learning, we will need to venture beyond evaluation scores. Indeed, just as it is impossible to capture all the dimensions of humanity with a single numerical quantity (e.g., IQ, height), trying to understand a model by one or even several statistics alone is fundamentally limiting.
One difference between understanding a human and understanding a model is that we have easy access to all model parameters and all the individual computations that occur in a model. Indeed, by extracting a model’s hidden activations we can directly trace the process by which a model converts raw input into a prediction. Unfortunately, the world of hidden activations is far less hospitable than that of simple model performance statistics. Like the initial input, hidden activations are usually high dimensional, but unlike input data they are not structured in a form that humans can understand. If we venture into even higher dimensions, we can try to understand a model through its weights directly. Here, in the space of model weights, we have the freedom to move in millions to billions of orthogonal directions from a single starting point. How do we even begin to make sense of these worlds?
There is a well-known fable in which three blind men each feel a different part of an elephant. The description that each gives of the animal is completely different, reflecting only the body part that that man felt. We argue that unlike the blind men who can at least use their hand to feel a substantial part of one of the elephant’s body parts, current methods of analyzing the hidden activations and weights of a model are akin to trying to describe the elephant from the touch of a single pin.
Tools to Characterize What We Cannot Visualize
Despite the popular perception that mathematicians exclusively focus on solving problems, much of research mathematics involves understanding the right questions to ask in the first place. This is natural since many of the objects that mathematicians study are so far removed from everyday experience that we start with very limited intuition for what we can hope to actually understand. Substantial effort is often required to build up tools that will enable us to leverage our existing intuition and achieve tractable results that increase our understanding. The concept of a rotation provides a nice example of this situation since these are very familiar in 2- and 3-dimensions, but become less and less accessible to everyday intuition as their dimension grows larger. In this latter case, the differing perspectives provided by pure mathematics become more and more important to gaining a more holistic perspective on what these actually are.
Those who know a little linear algebra will remember that rotations generalize to higher dimensions and that in $n$-dimensions they can be realized by $n \times n$ orthogonal matrices with determinant $1$. The set of these are commonly written as $SO(n)$ and called the special orthogonal group. Suppose we want to understand the set of all $n$-dimensional rotations. There are many complementary approaches to doing this. We can explore the linear algebraic structure of all matrices in $SO(n)$ or study $SO(n)$ based on how each element behaves as an operator acting on $\mathbb{R}^n$.
Alternatively, we can also try to use our innate spatial intuition to understand $SO(n)$. This turns out to be a powerful perspective in math. In any dimension $n$, $SO(n)$ is a geometric object called a manifold. Very roughly, a space that locally looks like Euclidean space, but which may have twists, holes, and other non-Euclidean features when we zoom out. Indeed, whether we make it precise or not, we all have a sense of whether two rotations are “close” to each other. For example, the reader would probably agree that $2$-dimensional rotations of $90^\circ$ and $91^\circ$ “feel” closer than rotations of $90^\circ$ and $180^\circ$. When $n=2$, one can show that the set of all rotations is geometrically “equivalent” to a $1$-dimensional circle. So, much of what we know about the circle can be translated to $SO(2)$.
What happens when we want to study the geometry of rotations in $n$-dimensions for $n > 3$? If $n = 512$ (a latent space for instance), this amounts to studying a manifold in $512^2$-dimensional space. Our visual intuition is seemingly useless here since it is not clear how concepts that are familiar in 2- and 3-dimensions can be utilized in $512^2$-dimensions. Mathematicians have been confronting the problem of understanding the un-visualizable for hundreds of years. One strategy is to find generalizations of familiar spatial concepts from $2$ and $3$-dimensions to $n$-dimensions that connect with our intuition.
This approach is already being used to better understand and characterize experimental observations about the space of model weights, hidden activations, and input data of deep learning models. We provide a taste of such tools and applications here:
- Intrinsic Dimension: Dimension is a concept that is familiar not only from our experience in the spatial dimensions that we can readily access, 1-, 2-, and 3-dimensions, but also from more informal notions of “degrees of freedom” in everyday systems such as driving a car (forward/back, turning the steering wheel either left or right). The notion of dimension arises naturally in the context of machine learning where we may want to capture the number of independent ways in which a dataset, learned representation, or collection of weight matrices actually vary.
In formal mathematics, the definitions of dimension depend on the kind of space one is studying but they all capture some aspect of this everyday intuition. As a simple example, if I walk along the perimeter of a circle, I am only able to move forward and backward, and thus the dimension of this space is $1$. For spaces like the circle which are manifolds, dimension can be formally defined by the fact that a sufficiently small neighborhood around each point looks like a subset of some Euclidean space $\mathbb{R}^k$. We then say that the manifold is $k$-dimensional. If we zoom in on a small segment of the circle, it almost looks like a segment of $\mathbb{R} = \mathbb{R}^1$, and hence the circle is $1$-dimensional.
The manifold hypothesis posits that many types of data (at least approximately) live on a low-dimensional manifold even though they are embedded in a high-dimensional space. If we assume that this is true, it makes sense that the dimension of this underlying manifold, called the intrinsic dimension of the data, is one way to describe the complexity of the dataset. Researchers have estimated intrinsic dimension for common benchmark datasets, showing that intrinsic dimension appears to be correlated to the ease with which models generalize from training to test sets [6], and can explain differences in model performance and robustness in different domains such as medical images [7]. Intrinsic dimension is also a fundamental ingredient in some proposed explanations of data scaling laws [8, 9], which underlie the race to build ever bigger generative models.
Researchers have also noted that the intrinsic dimension of hidden activations tend to change in a characteristic way as information passes through the model [10, 11] or over the course of the diffusion process [12]. These and other insights have led to the use of intrinsic dimension in detection of adversarial examples [13], AI-generated content [14], layers where hidden activations contain the richest semantic content [11], and hallucinations in generative models [15].
- Curvature: While segments of the circle may look “straight” when we zoom up close enough, their curvature means that they will never be exactly linear as a straight line is. The notion of curvature is a familiar one and once formalized, it offers a way of rigorously measuring the extent to which the area around a point deviates from being linear. Care must be taken, however. Much of our everyday intuition about curvature assumes a single dimension. On manifolds with dimension $2$ or greater, there are multiple, linearly independent directions that we can travel away from a point and each of these may have a different curvature (in the $1$-dimensional sense). As a result, there are a range of different generalizations of curvature for higher-dimensional spaces, each with slightly different properties.
The notion of curvature has played a central role in deep learning, especially with respect to the loss landscape where changes in curvature have been used to analyze training trajectories [16]. Curvature is also central to an intriguing phenomenon known as the ‘edge of stability’, wherein the curvature of the loss landscape over the course of training increases as a function of learning rate until it hovers around the point where the training run is close to becoming unstable [17]. In another direction, curvature has been used to calculate the extent that model predictions change as input changes. For instance, [18] provided evidence that higher curvature in decision boundaries correlates with higher vulnerability to adversarial examples and suggested a new regularization term to reduce this. Finally, motivated by work in neuroscience, [19] presented a method that uses curvature to highlight interesting differences in representation between the raw training data and a neural network’s internal representation. A network may stretch and expand parts of the input space, generating regions of high curvature as it magnifies the representation of training examples that have a higher impact on the loss function.
- Topology: Both dimension and curvature capture local properties of a space that can be measured by looking at the neighborhood around a single point. On the other hand, the most notable feature of our running example, the circle, is neither its dimension nor its curvature, but rather the fact that it is circular. We can only see this aspect by analyzing the whole space at once. Topology is the field of mathematics that focuses on such “global” properties.
Topological tools such as homology, which counts the number of holes in a space, has been used to illuminate the way that neural networks process data, with [20] showing that deep learning models “untangle” data distributions, reducing their complexity layer by layer. Versions of homology have also been applied to the weights of networks to better understand their structural features, with [21] showing that such topological statistics can reliably predict optimal early-stopping times. Finally, since topology provides frameworks that capture the global aspects of a space, it has proved a rich source of ideas for how to design networks that capture higher order relationships within data, leading to a range of generalizations of graph neural networks built on top of topological constructions [22, 23, 24, 25].
While the examples above have each been useful for gaining insight into phenomena related to deep learning, they were all developed to address challenges in other fields. We believe that a bigger payoff will come when the community uses the geometric paradigm described here to build new tools specifically designed to address the challenges that deep learning poses. Progress in this direction has already begun. Think for instance of linear mode connectivity which has helped us to better understand the loss landscape of neural networks [26] or work around the linear representation hypothesis which has helped to illuminate the way that concepts are encoded in the latent space of large language models [27]. One of the most exciting occurrences in mathematics is when the tools from one domain provide unexpected insight in another. Think of the discovery that Riemannian geometry provides some of the mathematical language needed for general relativity. We hope that a similar story will eventually be told for geometry and topology’s role in deep learning.
Symmetries in data, symmetries in models
Symmetry is a central theme in mathematics, allowing us to break a problem into simpler components that are easier to solve. Symmetry has long played an important role in machine learning, particularly computer vision. In the classic dog vs. cat classification task for instance, an image that contains a dog continues to contain a dog regardless of whether we move the dog from one part of the image to another, whether we rotate the dog, or whether we reflect it. We say that the task is invariant to image translation, rotation, and reflection.
The notion of symmetry is mathematically encoded in the concept of a group, which is a set $G$ equipped with a binary operation $\star$ that takes two elements of $G$, $g_1$, $g_2$ as input and produces a third $g_1\star g_2$ as output. You can think of the integers $\mathbb{Z}$ with the binary operation of addition ($\star = +$) or the non-zero real numbers with the binary operation of multiplication ($\star = \times$). The set of $n$-dimensional rotations, $SO(n)$, also forms a group. The binary operation takes two rotations and returns a third rotation that is defined by simply applying the first rotation and then applying the second.
Groups satisfy axioms that ensure that they capture familiar properties of symmetries. For example, for any symmetry transformation, there should be an inverse operation that undoes the symmetry. If I rotate a circle by $90^{\circ}$, then I can rotate it back by $-90^{\circ}$ and return to where I started. Notice that not all transformations satisfy this property. For instance, there isn’t a well-defined inverse for downsampling an image. Many different images downsample to the same (smaller) image.
In the previous section we gave two definitions of $SO(n)$: the first was the geometric definition, as rotations of $\mathbb{R}^n$, and the second was as a specific subset of $n \times n$ matrices. While the former definition may be convenient for our intuition, the latter has the benefit that linear algebra is something that we understand quite well at a computational level. The realization of an abstract group as a set of matrices is called a linear representation and it has proven to be one of the most fruitful methods of studying symmetry. It is also the way that symmetries are usually leveraged when performing computations (for example, in machine learning).
We saw a few examples of symmetries that can be found in the data of a machine learning task, such as the translation, rotation, and reflection symmetries in computer vision problems. Consider the case of a segmentation model. If one rotates an input image by $45^{\circ}$ and then puts it through the model, we will hope that we get a $45^{\circ}$ rotation of the segmentation prediction for the un-rotated image (this is illustrated in 1). After all, we haven’t changed the content of the image.
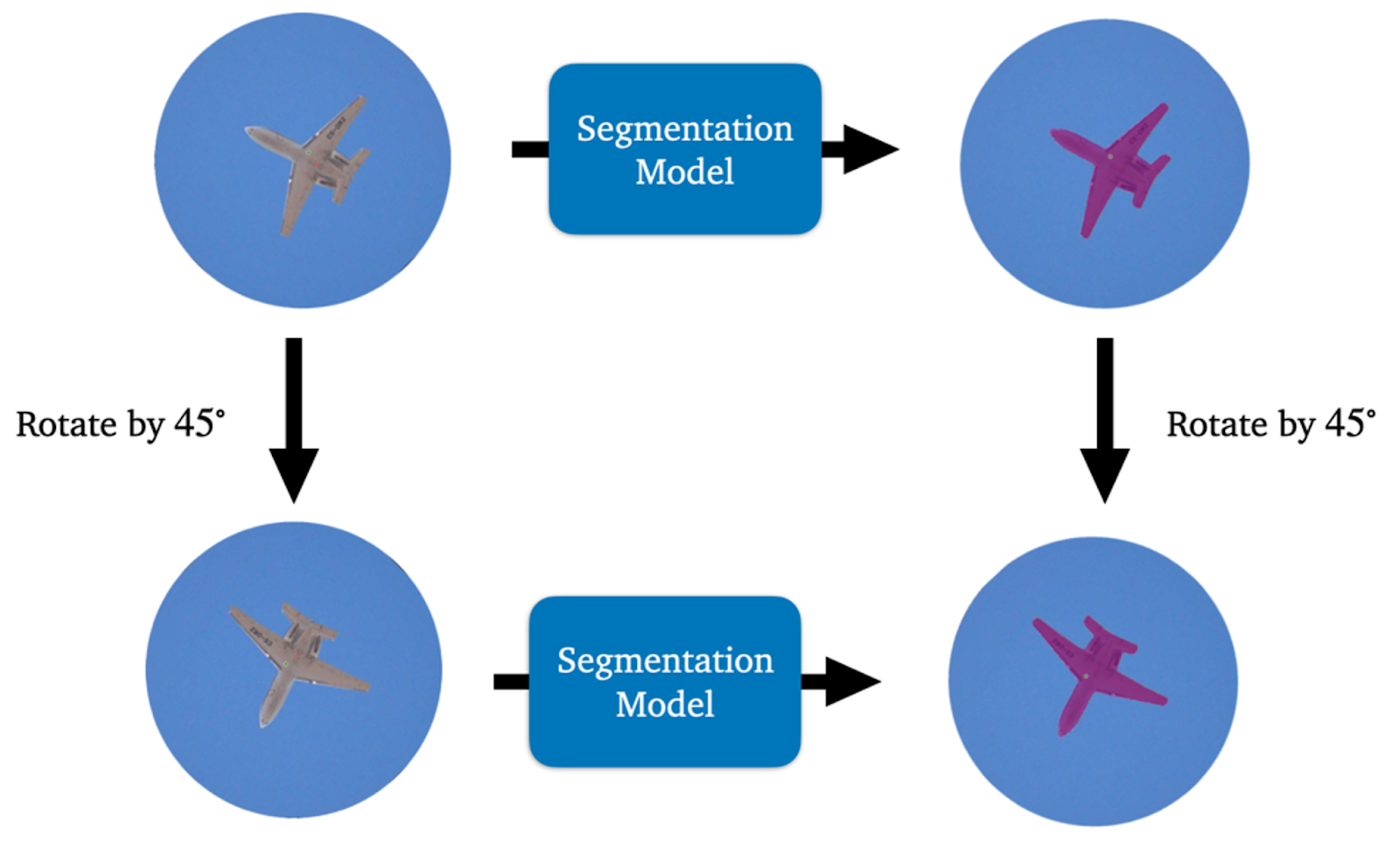
Figure 2: The concept of rotation equivariance illustrated for a segmentation model. One gets the same output regardless of whether one rotates first and then applies the network or applies the network and then rotates.
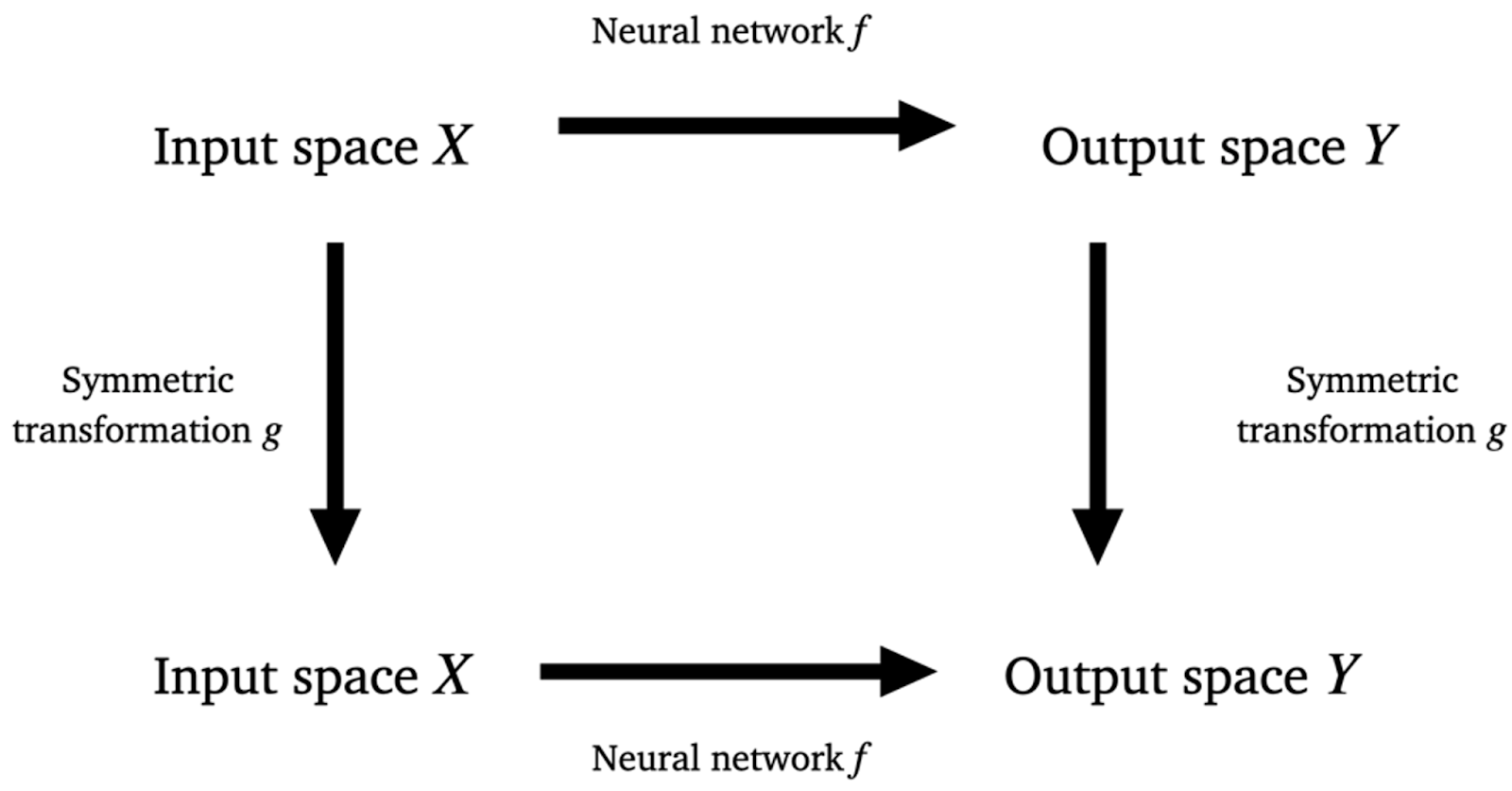
Figure 3: Equivariance holds when taking the top path (applying the network first and then the symmetry action) gives the same result as taking the bottom path (applying the symmetry transformation and then the network).
This property of a function (including neural networks), that applying a symmetry transformation before the function yields the same result as applying the symmetry transformation after the function is called equivariance and can be captured by the diagram in Figure 3. The key point is that we get the same result whether we follow the upper path (applying the network first and then applying the group action) as when we follow the lower path (applying the group first and then applying the network). Conveniently, the concept of invariance, where applying a symmetry operation to input has no effect on the output of the function is a special case of equivariance where the action on the output space is defined to be trivial (applying symmetry actions does nothing).
Invariance and equivariance in deep learning models can be beneficial for a few reasons. Firstly, such a model will yield more predictable and consistent results across symmetry transformations. Secondly, through equivariance we can sometimes simplify the learning process with fewer parameters (compare the number of parameters in a convolutional neural network and an MLP of similar performance) and fewer modes of variation to learn in the data (a rotation invariant image classifier only needs to learn one orientation of each object rather than all possible orientations).
But how do we ensure that our model is equivariant? One way is to build our network with layers that are equivariant by design. By far the most well-known example of this is the convolutional neural network, whose layers are (approximately) equivariant to image translation. This is one reason why using a convolutional neural network for dog vs cat classification doesn’t require learning to recognize a dog at every location in an image as it might with an MLP. With a little thought, one can often come up with layers which are equivariant to a specific group. Unfortunately, being constrained to equivariant layers that we find in an ad-hoc manner often leaves us with a network with built-in equivariance but limited expressivity.
Fortunately, for most symmetry groups arising in machine learning, representation theory offers a comprehensive description of all possible linear equivariant maps. Indeed, it is a beautiful mathematical fact that all such maps are built from atomic building blocks called irreducible representations. Happily, in many cases, the number of these irreducible representations is finite. Understanding the irreducible representations of a group can be quite powerful. Those familiar with the ubiquitous discrete Fourier transform (DFT) of a sequence of length $n$ are already familiar with the irreducible representations of one group, the cyclic group generated by a rotation by $360 ^{\circ}/n$ (though we note that moving between the description we give here and the description of the DFT found in the signal processing literature takes a little thought).
There is now a rich field of research in deep learning that uses group representations to systematically build expressive equivariant architectures. Some examples of symmetries that have been particularly well-studied include: rotation and reflection of images [28, 29, 30, 31], 3-dimensional rotation and translation of molecular structures [32] or point clouds [33], and permutations for learning on sets [34] or nodes of a graph [35]. Encoding equivariance to more exotic symmetries has also proven useful for areas such as theoretical physics [36] and data-driven optimization [37].
Equivariant layers and other architectural approaches to symmetry awareness are a prime example of using mathematics to inject high-level priors into a model. Do these approaches represent the future of learning in the face of data symmetries? Anecdotally, the most common approach to learning on data with symmetries continues to be using enough training data and enough data augmentation for the model to learn to handle the symmetries on its own. Two years ago, the author would have speculated that these latter approaches only work for simple cases, such as symmetries in 2-dimensions, and will be outperformed by models which are equivariant by design when symmetries become more complex. Yet, we continue to be surprised by the power of scale. After all, AlphaFold3 [38] uses a non-equivariant architecture despite learning on data with several basic symmetries. We speculate that there may be a threshold on the ratio of symmetry complexity on the one hand and the amount of training data on the other, that determines whether built-in equivariance will outperform learned equivariance [39, 40].
If this is true, we can expect to see models move away from bespoke equivariant architectures as larger datasets become available for a specific application. At the same time, since compute will always be finite, we predict that there will be some applications with exceptionally complex symmetries that will always require some built-in priors (for example, AI for math or algorithmic problems). Regardless of where we land on this spectrum, mathematicians can look forward to an interesting comparison of the ways humans inject symmetry into models vs the way that models learn symmetries on their own [41, 42].

Figure 4: A cartoon illustrating why adding a permutation and its inverse before and after a pointwise nonlinearity produces an equivalent model (even though the weights will be different). Since permutations can be realized by permutation matrices, the crossed arrows on the right can be merged into the fully-connected layer.
Of course, symmetry is not only present in data but also in the models themselves. For instance, the activations of hidden layers of a network are invariant to permutation. We can permute activations before entering the non-linearity and if we un-permute them afterward, the model (as a function) does not change (Figure 4). This means that we have an easy recipe for generating an exponentially large number of networks that have different weights but behave identically on data.
While simple, this observation produces some unexpected results. There is evidence, for instance, that while the loss landscape of neural networks is highly non-convex, it may be much less non-convex when we consider all networks that can be produced through this permutation operation as equivalent [43, 44]. This means that your network and my network may not be connected by a linear path of low loss, but such a path may exist between your network and a permutation of my network. Other research has looked at whether it may be possible to use symmetries to accelerate optimization by ‘teleporting’ a model to a more favorable location in the loss landscape [45, 46]. Finally, permutation symmetries also provide one type of justification for an empirical phenomenon where individual neurons in a network tend to encode more semantically meaningful information than arbitrary linear combinations of such neurons [47].
Taming Complexity with Abstraction
When discussing symmetry, we used the diagram in Figure 3 to define equivariance. One of the virtues of this approach is that we never had to specify details about the input data or architecture that we used. The spaces could be vector spaces and the maps linear transformations, they could be neural networks of a specific architecture, or they could just be sets and arbitrary functions between them–the definition is valid for each. This diagrammatic point of view, which looks at mathematical constructions in terms of the composition of maps between objects rather than the objects themselves, has been very fruitful in mathematics and is one gateway to the subject known as category theory. Category theory is now the lingua franca in many areas of mathematics since it allows mathematicians to translate definitions and results across a wide range of contexts.
Of course, deep learning is at its core all about function composition, so it is no great leap to try and connect it to the diagrammatic tradition in mathematics. The focus of function composition in the two disciplines is different, however. In deep learning we take simple layers that alone lack expressivity and compose them together to build a model capable of capturing the complexity of real-world data. With this comes the tongue-in-cheek demand to “stack more layers!”. Category theory instead tries to find a universal framework that captures the essence of structures appearing throughout mathematics. This allows mathematicians to uncover connections between things that look very different at first glance. For instance, category theory gives us the language to describe how the topological structure of a manifold can be encoded in groups via homology or homotopy theory.
It can be an interesting exercise to try to find a diagrammatic description of familiar constructions like the product of two sets $X$ and $Y$. Focusing our attention on maps rather than objects we find that what characterizes $X \times Y$ is the existence of the two canonical projections $\pi_1$ and $\pi_2$, the former sending $(x,y) \mapsto x$ and $(x,y) \mapsto y$ (at least in more familiar settings where $X$ and $Y$ are, for example, sets). Indeed, the product $X \times Y$ (regardless of whether $X$ and $Y$ are sets, vectors spaces, etc.) is the unique object such that for any $Z$ with maps $f_1: Z \rightarrow X$ and $f_2: Z \rightarrow Y$, there is a map $h: Z \rightarrow X \times Y$ that satisfies the commutative diagram in Figure 5.
While this construction is a little involved for something as familiar as a product it has the remarkable property that it allows us to define a “product” even when there is no underlying set structure (that is, those settings where we cannot resort to defining $X \times Y$ as the set of pairs of $(x,y)$ for $x \in X$ and $y \in Y$).

Figure 5: The commutative diagram that describes a product $X \times Y$. For any $Z$ with maps $f_1: Z \rightarrow X$ and $f_2: Z \rightarrow Y$, there exists a unique map $h: Z \rightarrow X \times Y$ such that $f_1 = \pi_1 \circ h$ and $f_2 = \pi_2 \circ h$ where $\pi_1$ and $\pi_2$ are the usual projection maps from $X \times Y$ to $X$ and $X \times Y$ to $Y$ respectively.
One can reasonably argue that diagrammatic descriptions of well-known constructions, like products, are not useful for the machine learning researcher. After all, we already know how to form products in all of the spaces that come up in machine learning. On the other hand, there are more complicated examples where diagrammatics mesh well with the way we build neural network architectures in practice.
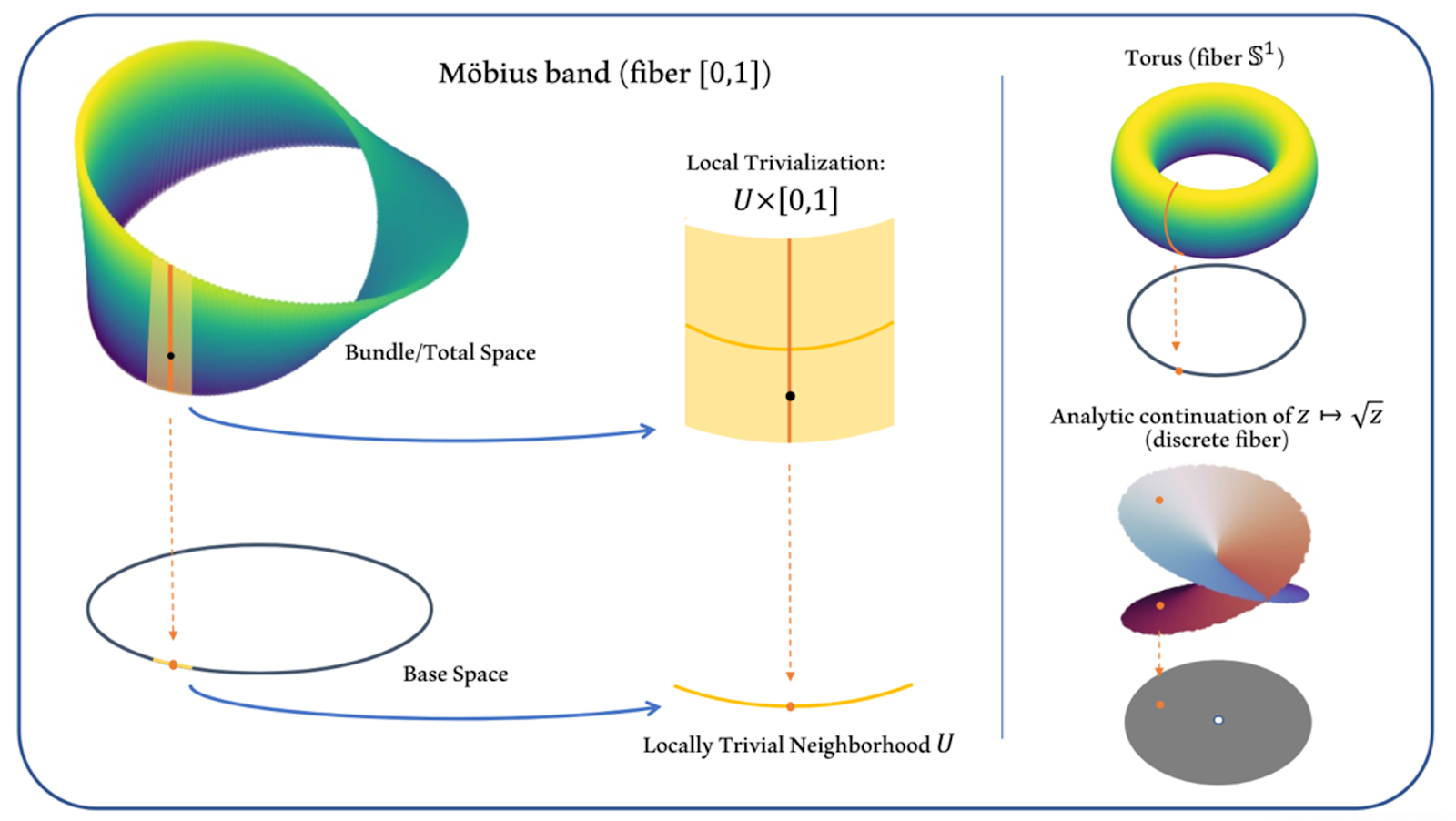
Figure 6: Fiber bundles capture the notion that a space might locally look like a product but globally have twists in it.
Fiber bundles are a central construction in geometry and topology that capture the notion that a space may locally look like a product but may have twists that break this product structure globally. Compare the cylinder with the Möbius band. We can build both of these by starting with a circle and taking a product with the line segment $(0,1)$. In the case of the cylinder, this really is just (topologically) the product of the circle and the segment $(0,1)$, but to form the Möbius band we must add an additional twist that breaks the product structure. In these examples, the circle is called the base space and $(0,1)$ is called the fiber. While only the cylinder is a true product, both the cylinder and the Möbius band are fiber bundles. Here is another way of thinking about a fiber bundle. A fiber bundle is a union of many copies of the fiber parametrized by the base space. In the Möbius band/cylinder example, each point on the circle carries its own copy of $(0,1)$.
We drew inspiration from this latter description of fiber bundles when we were considering a conditional generation task in the context of a problem in materials science. Since the materials background is somewhat involved, we’ll illustrate the construction via a more pedestrian, animal-classification analogue. Let $M$ be the manifold of all possible images containing a single animal. We can propose to decompose the variation in elements of $M$ into two parts, the species of animal in the image and everything else, where the latter could mean differences in background, lighting, pose, image quality, etc. One might want to explore the distribution of one of these factors of variation while fixing the other. For instance, we might want to fix the animal species and explore the variation we get in background, pose, etc. For example, comparing the variation in background for two different species of insect may tell the entomologist about the preferred habitat for different types of beetles.

Figure 7: A cartoon visualizing how the set of all animal images could be decomposed into a local product of animal species and other types of variation.
One might hope to solve this problem by learning an encoding of $M$ into a product space $X_1 \times X_2$ where $X_1$ is a discrete set of points corresponding to animal species and $X_2$ is a space underlying the distribution of all other possible types of variation for a fixed species of animal. Fixing the species would then amount to choosing a specific element $x_1$ from $X_1$ and sampling from the distribution on $X_2$. The product structure of $X_1 \times X_2$ allows us to perform such independent manipulations of $X_1$ and $X_2$. On the other hand, products are rigid structures that impose strong, global topological assumptions on the real data distribution. We found that even on toy problems, it was hard to learn a good map from the raw data distribution to the product-structured latent space defined above. Given that fiber bundles are more flexible and still give us the properties we wanted from our latent space, we designed a neural network architecture to learn a fiber bundle structure on a data distribution [48].
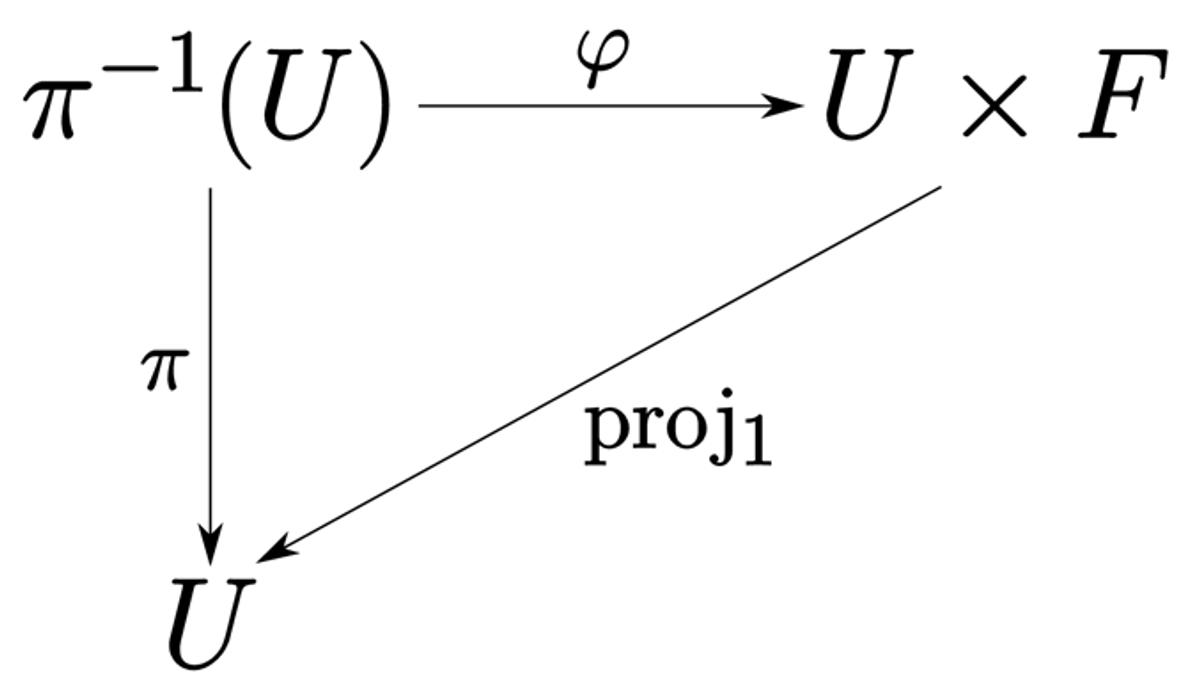
Figure 8: The commutative diagram describing a fiber bundle. The map $\pi$ projects from neighborhoods of the total space to the base space, $U$ is a local neighborhood of the base space, and $F$ is the fiber. The diagram says that each point in the base space has a neighborhood $U$ such that when we lift this to the bundle, we get something that is homeomorphic (informally, equivalent) to the product of the neighborhood and the fiber. But this product structure may not hold globally over the whole space.
But how do we go from the abstract definition of a fiber bundle above to a neural network architecture that we can code up on a computer. It turns out there is a succinct diagrammatic definition of a fiber bundle (Figure 8) that can serve as a convenient template to build up an architecture from. We were able to proceed in a relatively naïve fashion, taking each of the maps in the diagram and building a corresponding stack of layers. The diagram itself then told us how to compose each of these components together. The commutativity of the diagram was engineered through a term in the loss function that ensures that $\pi = \text{proj}_1 \circ \varphi$. There were also some conditions on $\varphi$ and $\pi$ (such as the bijectivity of $\phi$) that needed to be engineered. Beyond this, we were surprised at the amount of flexibility we had. This is useful since it means this process is largely agnostic to data modality.
This is an elementary example of how the diagrammatic tradition in mathematics can provide us with a broader perspective on the design of neural networks, allowing us to connect deep structural principles with large-scale network design without having to specify small-scale details that might be problem dependent. Of course, all this fails to draw from anything beyond the surface of what the categorical perspective has to offer. Indeed, category theory holds promise as a unified framework to connect much of what appears and is done in machine learning [49].
Conclusion
In the mid-twentieth century, Eugene Wigner marveled at the “the unreasonable effectiveness of mathematics” as a framework for not only describing existing physics but also anticipating new results in the field [50]. A mantra more applicable to recent progress in machine learning is “the unreasonable effectiveness of data” [51] and compute. This could appear to be a disappointing situation for mathematicians who might have hoped that machine learning would be as closely intertwined to advanced mathematics as physics is. However, as we’ve demonstrated, while mathematics may not maintain the same role in machine learning research that it has held in the past, the success of scale actually opens new paths for mathematics to support progress in machine learning research. These include:
- Providing powerful tools for deciphering the inner workings of complex models
- Offering a framework for high-level architectural decisions that leave the details to the learning algorithm
- Bridging traditionally isolated domains of mathematics like topology, abstract algebra, and geometry with ML and data science applications.
Should the way things have turned out surprise us? Perhaps not, given that machine learning models ultimately reflect the data they are trained on and in most cases this data comes from fields (such as natural language or imagery) which have long resisted parsimonious mathematical models.
Yet, this situation is also an opportunity for mathematics. Performant machine learning models may provide a gateway for mathematical analysis of a range of fields that were previously inaccessible. It’s remarkable for instance that trained word embeddings transform semantic relationships into algebraic operations on vectors in Euclidean space (for instance, ‘Italian’ - ‘Italy’ + ‘France’ = ‘French’). Examples like this hint at the potential for mathematics to gain a foothold in complex, real-world settings by studying the machine learning models that have trained on data from these settings.
As more and more of the data in the world is consumed and mathematicised by machine learning models, it will be an increasingly interesting time to be a mathematician. The challenge now lies in adapting our mathematical toolkit to this new landscape, where empirical breakthroughs often precede theoretical understanding. By embracing this shift, mathematics can continue to play a crucial, albeit evolving, role in shaping the future of machine learning.
The author would like to thank Darryl Hannan for help with figures, Davis Brown, Charles Godfrey, and Scott Mahan for useful feedback on drafts, as well as the staff of the Gradient for useful conversations and help editing this article. For resources and events around the growing community of mathematicians and computer scientists using topology, algebra, and geometry (TAG) to better understand and build more robust machine learning systems, please visit us at https://www.tagds.com.
References
[1] Richard Sutton. "The bitter lesson". In: Incomplete Ideas (blog) 13.1 (2019), p. 38.
[2] Guido F Montufar et al. "On the number of linear regions of deep neural networks". In: Advances in Neural Information Processing Systems 27 (2014).
[3] Boris Hanin and David Rolnick. "Complexity of linear regions in deep networks". In: International Conference on Machine Learning. PMLR. 2019, pp. 2596–2604.
[4] J Elisenda Grigsby and Kathryn Lindsey. "On transversality of bent hyperplane arrangements and the topological expressiveness of ReLU neural networks". In: SIAM Journal on Applied Algebra and Geometry 6.2 (2022), pp. 216–242.
[5] Ahmed Imtiaz Humayun et al. "Splinecam: Exact visualization and characterization of deep network geometry and decision boundaries". In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023, pp. 3789–3798.
[6] Phillip Pope et al. "The intrinsic dimension of images and its impact on learning". In: arXiv preprint arXiv:2104.08894 (2021).
[7] Nicholas Konz and Maciej A Mazurowski. "The Effect of Intrinsic Dataset Properties on Generalization: Unraveling Learning Differences Between Natural and Medical Images". In: arXiv preprint arXiv:2401.08865 (2024).
[8] Yasaman Bahri et al. "Explaining neural scaling laws". In: arXiv preprint arXiv:2102.06701 (2021).
[9] Utkarsh Sharma and Jared Kaplan. "A neural scaling law from the dimension of the data manifold". In: arXiv preprint arXiv:2004.10802 (2020).
[10] Alessio Ansuini et al. "Intrinsic dimension of data representations in deep neural networks". In: Advances in Neural Information Processing Systems 32 (2019).
[11] Lucrezia Valeriani et al. "The geometry of hidden representations of large transformer models". In: Advances in Neural Information Processing Systems 36 (2024).
[12] Henry Kvinge, Davis Brown, and Charles Godfrey. "Exploring the Representation Manifolds of Stable Diffusion Through the Lens of Intrinsic Dimension". In: ICLR 2023 Workshop on Mathematical and Empirical Understanding of Foundation Models.
[13] Xingjun Ma et al. "Characterizing adversarial subspaces using local intrinsic dimensionality". In: arXiv preprint arXiv:1801.02613 (2018).
[14] Peter Lorenz, Ricard L Durall, and Janis Keuper. "Detecting images generated by deep diffusion models using their local intrinsic dimensionality". In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023, pp. 448–459.
[15] Fan Yin, Jayanth Srinivasa, and Kai-Wei Chang. "Characterizing truthfulness in large language model generations with local intrinsic dimension". In: arXiv preprint arXiv:2402.18048 (2024).
[16] Justin Gilmer et al. "A loss curvature perspective on training instabilities of deep learning models". In: International Conference on Learning Representations. 2021.
[17] Jeremy Cohen et al. "Gradient descent on neural networks typically occurs at the edge of stability". In: International Conference on Learning Representations. 2020.
[18] Seyed-Mohsen Moosavi-Dezfooli et al. "Robustness via curvature regularization, and vice versa". In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019, pp. 9078–9086.
[19] Francisco Acosta et al. "Quantifying extrinsic curvature in neural manifolds". In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023, pp. 610–619.
[20] Gregory Naitzat, Andrey Zhitnikov, and Lek-Heng Lim. "Topology of deep neural networks". In: Journal of Machine Learning Research 21.184 (2020), pp. 1–40.
[21] Bastian Rieck et al. "Neural persistence: A complexity measure for deep neural networks using algebraic topology". In: arXiv preprint arXiv:1812.09764 (2018).
[22] Mustafa Hajij, Kyle Istvan, and Ghada Zamzmi. "Cell complex neural networks". In: arXiv preprint arXiv:2010.00743 (2020).
[23] Cristian Bodnar. "Topological deep learning: graphs, complexes, sheaves". PhD thesis. 2023.
[24] Jakob Hansen and Robert Ghrist. "Toward a spectral theory of cellular sheaves". In: Journal of Applied and Computational Topology 3.4 (2019), pp. 315–358.
[25] Yifan Feng et al. "Hypergraph neural networks". In: Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. 01. 2019, pp. 3558–3565.
[26] Felix Draxler et al. "Essentially no barriers in neural network energy landscape". In: International Conference on Machine Learning. PMLR. 2018, pp. 1309–1318.
[27] Kiho Park, Yo Joong Choe, and Victor Veitch. "The linear representation hypothesis and the geometry of large language models". In: arXiv preprint arXiv:2311.03658 (2023).
[28] Taco Cohen and Max Welling. "Group equivariant convolutional networks". In: International Conference on Machine Learning. PMLR. 2016, pp. 2990–2999.
[29] Maurice Weiler, Fred A Hamprecht, and Martin Storath. "Learning steerable filters for rotation equivariant cnns". In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018, pp. 849–858.
[30] Daniel E Worrall et al. "Harmonic networks: Deep translation and rotation equivariance". In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017, pp. 5028–5037.
[31] Diego Marcos et al. "Rotation equivariant vector field networks". In: Proceedings of the IEEE International Conference on Computer Vision. 2017, pp. 5048–5057.
[32] Alexandre Duval et al. "A Hitchhiker's Guide to Geometric GNNs for 3D Atomic Systems". In: arXiv preprint arXiv:2312.07511 (2023).
[33] Nathaniel Thomas et al. "Tensor field networks: Rotation-and translation-equivariant neural networks for 3d point clouds". In: arXiv preprint arXiv:1802.08219 (2018).
[34] Manzil Zaheer et al. "Deep sets". In: Advances in Neural Information Processing Systems 30 (2017).
[35] Vıctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. "E (n) equivariant graph neural networks". In: International Conference on Machine Learning. PMLR. 2021, pp. 9323–9332.
[36] Denis Boyda et al. "Sampling using SU (N) gauge equivariant flows". In: Physical Review D 103.7 (2021), p. 074504.
[37] Hannah Lawrence and Mitchell Tong Harris. "Learning Polynomial Problems with SL(2,\mathbb {R}) −Equivariance". In: The Twelfth International Conference on Learning Representations. 2023.
[38] Josh Abramson et al. "Accurate structure prediction of biomolecular interactions with AlphaFold 3". In: Nature (2024), pp. 1–3.
[39] Scott Mahan et al. "What Makes a Machine Learning Task a Good Candidate for an Equivariant Network?" In: ICML 2024 Workshop on Geometry-grounded Representation Learning and Generative Modeling.
[40] Johann Brehmer et al. "Does equivariance matter at scale?" In: arXiv preprint arXiv:2410.23179 (2024).
[41] Chris Olah et al. "Naturally Occurring Equivariance in Neural Networks". In: Distill (2020). https://distill.pub/2020/circuits/equivariance. doi: 10.23915/distill.00024.004.
[42] Giovanni Luca Marchetti et al. "Harmonics of Learning: Universal Fourier Features Emerge in Invariant Networks". In: arXiv preprint arXiv:2312.08550 (2023).
[43] Rahim Entezari et al. "The role of permutation invariance in linear mode connectivity of neural networks". In: arXiv preprint arXiv:2110.06296 (2021).
[44] Samuel K Ainsworth, Jonathan Hayase, and Siddhartha Srinivasa. "Git re-basin: Merging models modulo permutation symmetries". In: arXiv preprint arXiv:2209.04836 (2022).
[45] Bo Zhao et al. "Symmetry teleportation for accelerated optimization". In: Advances in Neural Information Processing Systems 35 (2022), pp. 16679–16690.
[46] Bo Zhao et al. "Improving Convergence and Generalization Using Parameter Symmetries". In: arXiv preprint arXiv:2305.13404 (2023).
[47] Charles Godfrey et al. "On the symmetries of deep learning models and their internal representations". In: Advances in Neural Information Processing Systems 35 (2022), pp. 11893–11905.
[48] Nico Courts and Henry Kvinge. "Bundle Networks: Fiber Bundles, Local Trivializations, and a Generative Approach to Exploring Many-to-one Maps". In: International Conference on Learning Representations. 2021.
[49] Bruno Gavranović et al. "Position: Categorical Deep Learning is an Algebraic Theory of All Architectures". In: Forty-first International Conference on Machine Learning.
[50] Eugene P Wigner. "The unreasonable effectiveness of mathematics in the natural sciences". In: Mathematics and Science. World Scientific, 1990, pp. 291–306.
[51] Alon Halevy, Peter Norvig, and Fernando Pereira. "The unreasonable effectiveness of data". In: IEEE Intelligent Systems 24.2 (2009), pp. 8–12.

{kind=link}