
This piece was a finalist for the inaugural Gradient Prize.
In the first year of my PhD, I started trauma recovery therapy to heal from domestic violence. It mostly consisted of something called “reprocessing sessions''; using a technique called EMDR we would revisit traumatic memories in my life, and try to figure out what beliefs I had that were linked to those events. All of us move through the world with beliefs about what will happen and who we are. Beliefs like “I can’t trust anyone” might come from negative experiences in relationships. “I’m not good enough” might come from years of putting yourself down and comparing yourself to others. “Everything sucks” likely comes from a long history of everything, well… sucking.
The point of trauma recovery therapy was so that I could rewrite my story moving forwards, instead of being debilitated by my past experiences.
While our past experiences certainly inform our beliefs about the world, sometimes they are unhelpful. If we saw unhealthy models of relationships, or were bullied in school, or had to grow up too fast, or lost someone too early, or never saw ourselves represented in the media: all of these are forms of trauma that affect our beliefs later down the line. Imagine you could collect every experience you’ve ever had; everything you’ve ever said to yourself in the mirror, everything you’ve ever been told was the “right” way to live your life.
That is the training data given to your mind.
As machine learning scientists, we know that training data can make or break your model. Where you got the data from, how biased it is, when it was sampled, how it was categorized. We think about each of these questions when trying to make a generalizable model of the world. So why don’t we apply the same concerns to our personal histories? So often we give disproportionate weight to the voice in our head that says we aren’t good enough. We do this unconsciously, without ever investigating where the data came from, or bothering to update the database.
As we take in data throughout our lives, we build models and heuristics on top of our massive collection of experiences in order to inform us of what to do next. While we certainly have learned basic models like to not touch a hot stove, it’s less clear if we have learned how to empower ourselves; how to cope with life’s stresses; how to communicate with others; how to discover who we really are.
As I worked through painful experiences of domestic violence and abuse, I was beginning my PhD research on improving Machine Learning education. The thoughts that kept inspiring me were that we learn best when we are included in the data; when we have something to relate back to ourselves. When we are an active participant in the data generating process, we might understand the algorithms more. So I began research on the topic of using personal data for machine learning education. When we explore our own connections to data, our own experiences within algorithmic systems, we automatically engage in a process of self-reflection. As I worked with others to teach them about how algorithms affect us, I was working on retraining my own models of the world through trauma recovery; Abuse was not love. I deserved better. I am safe now. And I am allowed to reclaim my own power.
I’m currently working on a book called Life Lessons from Algorithms , a personal history of resilience demonstrated through different machine learning algorithms. Each machine learning concept can teach us something about our own healing. “Garbage in, garbage out” teaches us that unhealthy relationships affect how we expect to be treated in the future. “No free lunch” teaches us that everyone’s journey is different, and what works for one person won’t work for everyone. The tendency to overfit teaches us that we need a wide range of experiences, beliefs, philosophies, and friendships to truly teach us about the world. Ensemble methods teach us that sometimes two heads really are better than one. The curse of dimensionality teaches us that we can never take everything into account, that there is a certain level of faith inherent in being human.
Consider, for example, gradient descent. I have a life mantra for when I’m really stuck: “Do the next right thing”. It means that when I’m spiraling with self-doubt and uncertainty, I need to stop imagining a whole future in front of me and simply focus on the next thing that I can do. We cannot possibly know the landscape of what will happen; we can only take the next step. We have a goal in mind: to get a new job, to fall in love, to get healthy … or the ever-fleeting “to be happy”. All we can do is try to take a step in the right direction.
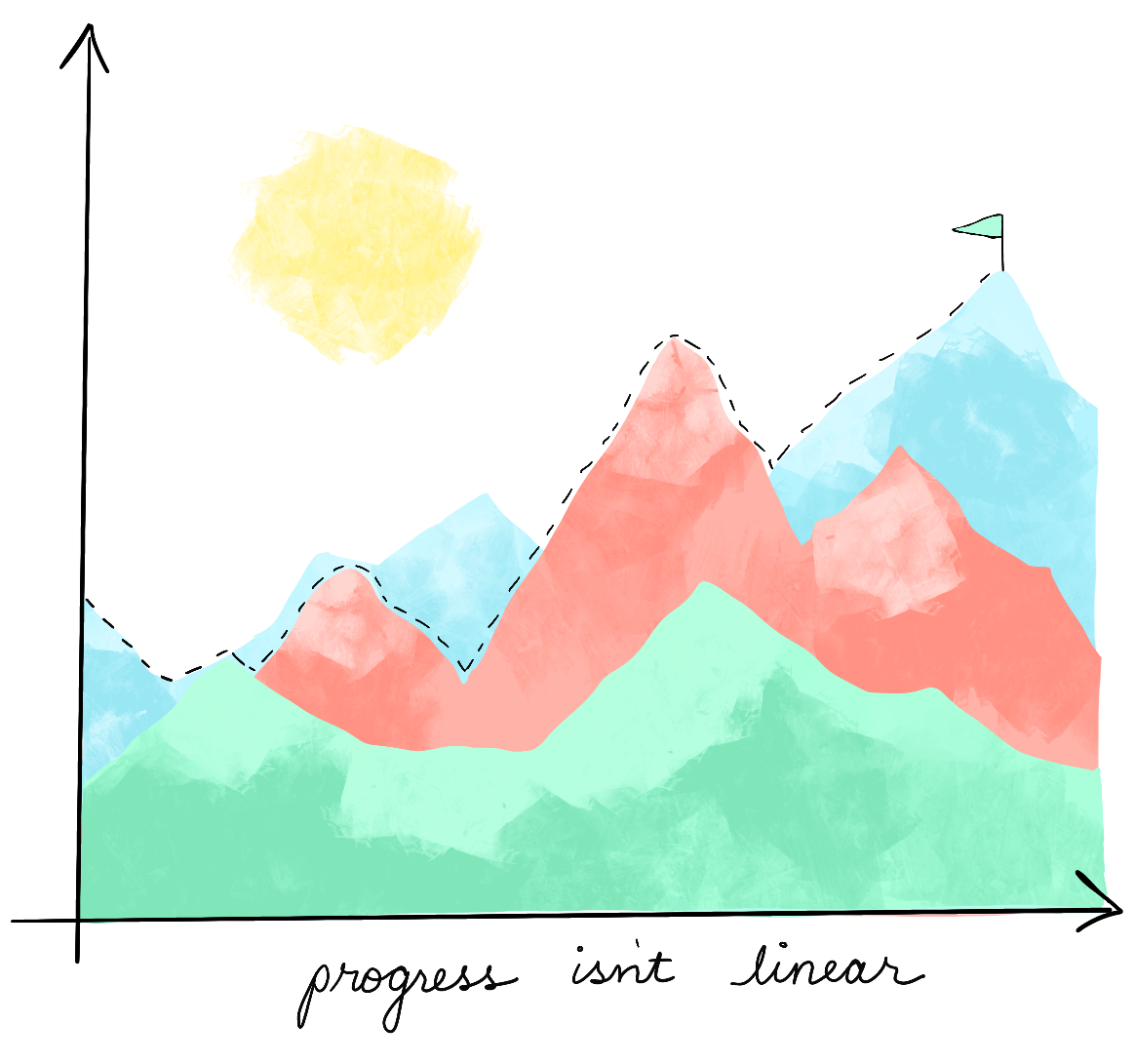
For those unfamiliar with gradient descent, it is an optimization algorithm used to get the “best” outcome (often referred to as a minima). The algorithm begins at an initial point in the parameter space, and iteratively takes steps “downward”, or towards what we hope is the minima. It is quite literally, doing the next right thing until it converges on the set of parameters that perform well. Just as in life, sometimes things have to get worse before they get better. A step in what seemed like the right direction can leave us stuck in a job, a relationship, or a routine that no longer serves us. Gradient descent (and many machine learning algorithms) have a special solution to this. Every so often, the algorithm randomly restarts in an entirely new place, just in case there’s something better it couldn’t get to by simply following the slope downwards. Sometimes in life, we need to take a leap of faith. Sometimes we need to start all over to find what’s best for us. Each of our journeys is a combination of accidents, luck, support, love, loss, joy, and a little bit of magic. All we can do to keep our head above water is to keep moving in the direction of our dreams, and every so often taking a leap into the unknown. The hope is that along the way, we find ourselves.
Author Bio
Yim is a PhD student at the University of Washington, researching innovative ways to teach machine learning. They are particularly interested in widespread algorithmic literacy on social media, with the goal of creating tools to empower users to speak up for themselves when algorithms perpetuate harm. They are nonbinary, an advocate for domestic violence survivors, and they are blessed with autism!
Citation
For attribution in academic contexts or books, please cite this work as
Yim Lucky Register, "It’s All Training Data: Using Lessons from Machine Learning to Retrain Your Mind", The Gradient, 2021.
BibTeX citation:
@article{register2021trainingdata,
author = {Register, Yim Lucky},
title = {It’s All Training Data: Using Lessons from Machine Learning to Retrain Your Mind},
journal = {The Gradient},
year = {2021},
howpublished = {\url{https://thegradient.pub/its-all-training-data/} },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.

{kind=link}