
Imagine you’re chilling in your little log cabin in the woods all alone. As you start with the 2nd book of the week on a December evening, you hear some heavy foot-steps nearby. You run to the window to see what it was. Through the window, you see a large and seemingly furry silhouette fade into the dark woods just beyond the front yard. The information you received from your environment screams of a bigfoot encounter, but your rational mind tells you that it is far more likely that it’s just an overly enthusiastic hiker passing by.
You just successfully made the “right mistake” by assuming that it's probably just a hiker, even though the information you have suggests otherwise. Your mind found a “rational explanation” to the raw information thanks to the years of experience you have in the woods.
An experiment by Liu et al. [1] involved scanning participants’ brains as they looked at images of gray “static”. They observed that the frontal and occipital regions of the participants' brains fired into action when they thought they saw a face, and these areas are thought to deal with higher-level thinking – such as planning and memory. This burst of activity may reflect the influence of expectation and experience.
As elaborated in It’s Bayes All The Way Up [2], Corlett, Frith & Fletcher [3] built a model of perception which involved a “handshake” between the “top-down” and the “bottom-up” ends of human perception, which can be defined in simple words as follows:
- Bottom-up: Processes and infers direct conclusions from raw information coming in from the sense organs. Scary Silhouette + Howls = bigfoot!
- Top-down: Adds a “layer of reasoning” on top of the raw information that is received and utilizes “learned priors” (i.e., experience from the past) to make sense out of the data. Scary Silhouette + Howls = an overly enthusiastic (or drunk) hiker.
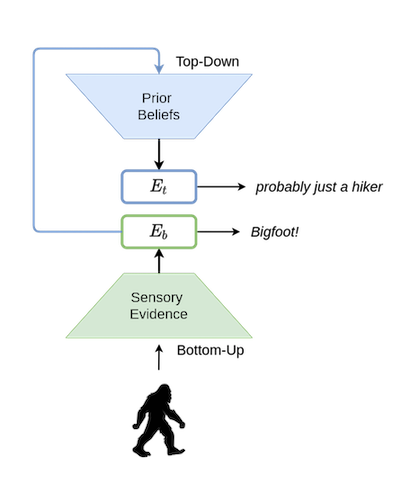
Kids are much more likely to “fall for” the direct conclusions made by bottom-up perception. This is because their top-down perception has not had enough “experience/training data” to learn and refine itself. In a way, we can say that their “world model” is not as good as that of adults.
An interesting consequence of a strong top-down perception is the ability of us humans to see things like animals/faces in the clouds (Pareidolia). This weird phenomenon in the brain might seem like a bug to us, but it used to be a life saving feature for our ancestors who were hunters/gatherers. It was safer for them to assume that they saw a face, even when there was none. This worked as a means of protection from predators in the wild.
What Are Multimodal Language Models?
Large Language Models like that of GPT-3/Luminous/PaLM are, in simple words, next token predictors. One can think of them as (large) neural networks which were trained to classify the next word/punctuation in a sentence, which, if done enough times, seems to generate text that’s coherent with the context.
Multimodal Language Models (LMs) are an attempt to make such language models perceive the world in a way that’s one step closer to that of humans. Most of the popular deep-learning models today (Like ResNets, GPT-Neo, etc) are purely specialized for either vision or language based tasks. ResNets are good for extracting information from images, and language models like GPT-Neo are good at generating text. Multimodal LMs are an attempt to make neural nets perceive information in the form of both images and text by combining vision and language models.
So Where Do Multimodal LMs Come In?
Multimodal LMs have the power to leverage the world knowledge encoded within its Language Model in other domains like images. We humans don’t just read and write. We see, read, and write. Multimodal LMs try to emulate this by adapting their image encoders to be compatible with the “embedding space” of their LMs.
One such example is MAGMA [4], which is a GPT-style model that can “see”. It can take an arbitrary sequence of text and images as an input and generate text accordingly.
It can be used to answer questions related to images, identify and describe objects present in the input images, and is also sometimes surprisingly good at Optical Character Recognition (OCR). It is also known to have a good sense of humor [5].
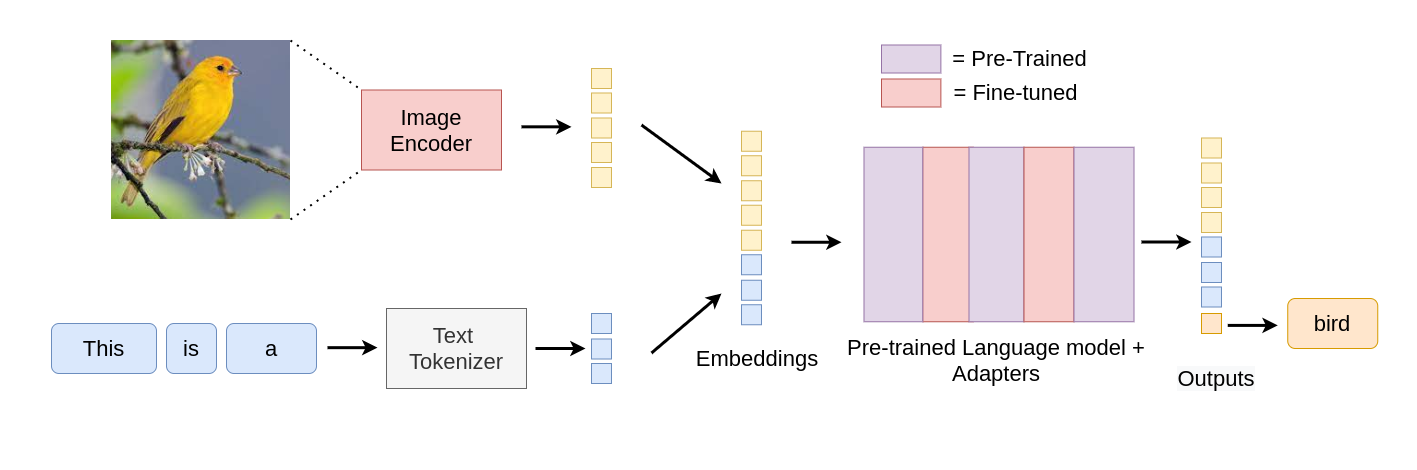
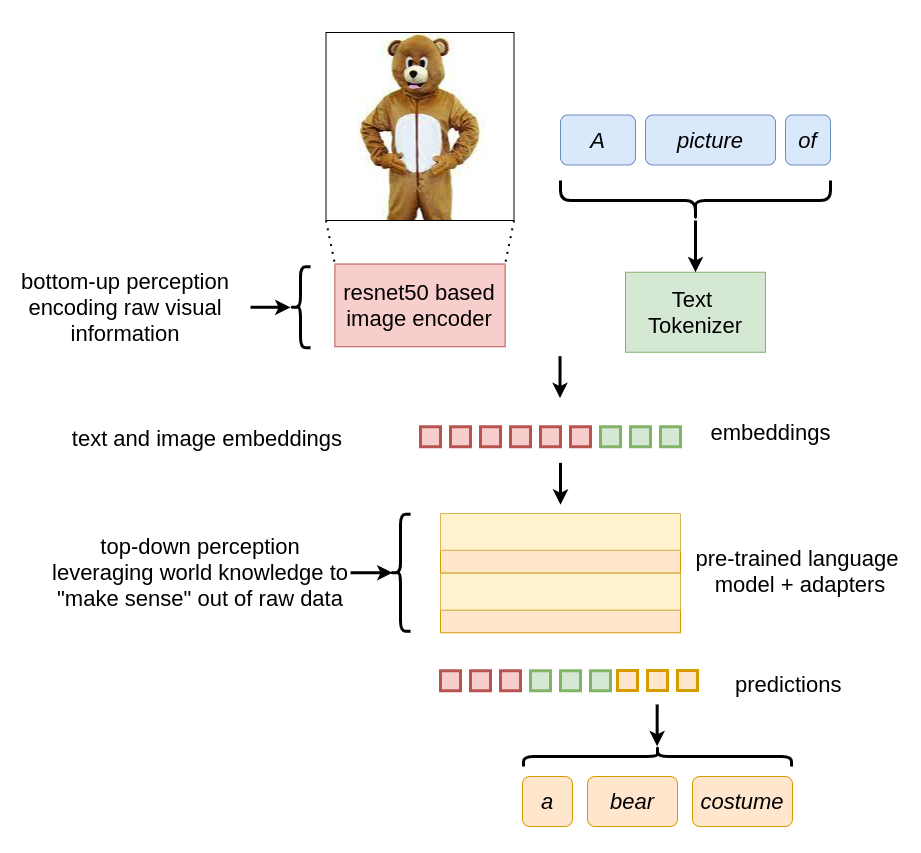
The pre-trained LM at the heart of this architecture contains within itself the world knowledge that gets leveraged in order to “make sense out of the inputs”. In more ways than one, it is equivalent to the top-down element of human perception which sometimes helps it make the right mistakes, as we’ll see below. With two quotes from It’s Bayes All The Way Up [2], we can chalk out MAGMA’s architecture as follows:
- Bottom-up processing is when you build perceptions into a model of the world. - Which, in this case, is the image encoder’s job.
- Top-down processing is when you let your models of the world influence your perception. - This is exactly what the LM is doing.
What Do We Mean by the “Right Mistakes”?

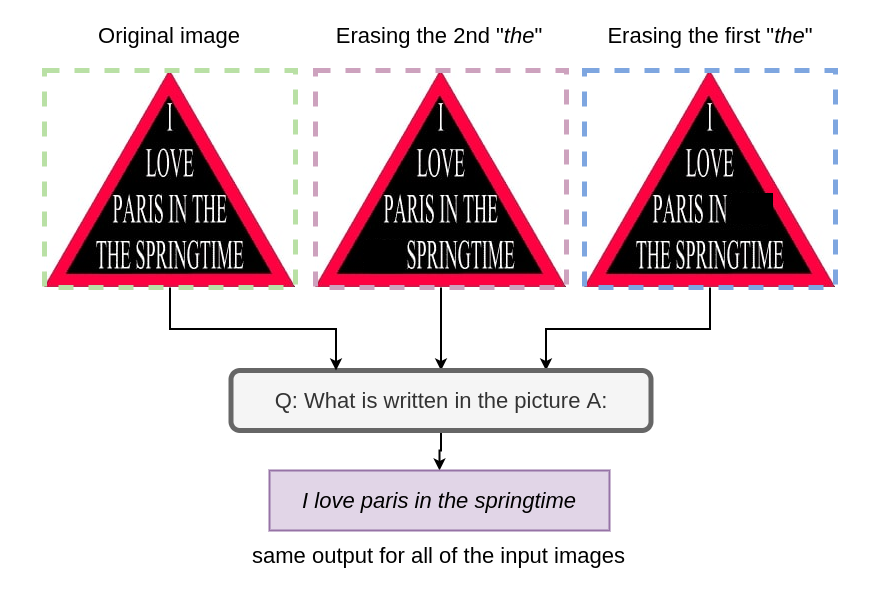
Unless you’ve seen this image before, chances are high that you read it as “I love Paris in the springtime” and not “I love Paris in the the springtime” (notice how there’s a second “the'' in the latter). This is because your top-down perception reads the first half of the sentence and confidently assumes that the rest of it is grammatically correct.
Even though the raw data from the image tells you that there’s a 2nd “the”, you skip over it thanks to your top-down perception which is wired to stitch together sentences from words without fully reading them.
Now the question is, does the same thing occur for MAGMA's outputs? The answer is yes.
MAGMA is definitely not the best OCR model out there. But what it does seem to provide is an intuitive filter on top of a simple task of reading what’s written on an image. When we erase out either one of the “the” in the image shown above, the result still stays the same.
In another example, we can see how MAGMA tries to “fill in” the partially erased words and comes up with a valid output. Even though it misses one word out on the modified image, it still ends up being close enough.

How Are These Multimodal LMs Any Better Than the CNNs?
The most common architecture that’s generally used for vision tasks are convolutional neural networks (CNNs) [6]. They’re a specialized architecture, to be trained on specialized datasets for very specific tasks like classifying images.
On the other side of this spectrum are the Large Language Models. As Gwern [7] puts it in his article, they’re basically just really big neural networks with a “simple uniform architecture trained in the dumbest way possible” (predicting the next word).
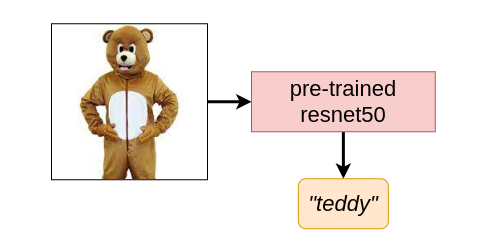
When we feed an image of a man in a teddy bear costume to a CNN (for example, a ResNet50), it encodes the information and predicts that it’s a “teddy”. Completely ignoring the fact that it could just be a man in a teddy costume. We should not blame these models for this limitation, as they were just trained to determine which category an image belongs to, given a limited set of categories (i.e., the ImageNet dataset in this case).
But when we fine-tune the same CNN to encode images so that they become compatible with the “embedding space” of a language model, we can leverage the LM’s world knowledge. This world knowledge within LMs is loosely equivalent to a form of “top-down” perception which parses the raw visual information sent from the image encoder.
How Are Multimodal LMs Different From Just Expanding a Vision Model’s Training Data To Include Images of a Teddy Bear Costume?
The problem with explicitly trying to expand the output domain to contain such things is that it’s not practical given the sheer number of possibilities out there. LMs, on the other hand, do not require such arrangements because they have implicit world knowledge encoded into them (biased or not). The ResNet50 in this case has a very limited output domain.
In a nutshell, the output of something like that of a ResNet50 is limited to only the labels of the classes it was trained on, while the LM is able to generate outputs of arbitrary length, thus giving it a much larger output domain as big as the domain of the language it was trained on.
Multimodal LMs are an attempt to, rather than expand the output space of a vision model, expand the input space of an LM by adding bottom-up processing to its already existing world model.
Closing Words
An exciting research direction in this field would be to bring in more modalities not only to the input, but also to the output space. Models which can generate both text and images as one single, seamless output.
Intelligence is not always about being correct, it sometimes is about making the right mistakes based on one’s understanding of the world. This principle in itself is an important basis of how humans work.
I’m sure a lot of AI researchers would be very happy on the day when AI starts seeing things in the clouds the way we do. It’ll get us one step closer to the pursuit of making machines wonder about things the way we do, and ask the questions we never could.
Author Bio
Mayukh is an AI researcher at Aleph-Alpha. His work focuses on reverse engineering Large Multimodal Language Models to make them explainable to humans. He is also an Undergrad student at Amrita Vishwa Vidyapeetham.
References
[1]: https://www.sciencedirect.com/science/article/abs/pii/S0010945214000288
[2]: https://slatestarcodex.com/2016/09/12/its-bayes-all-the-way-up/
[3]: https://www.nature.com/articles/nrn2536
[4]: https://arxiv.org/abs/2112.05253
[5]: https://twitter.com/Sigmoid_Freud
[6]: https://victorzhou.com/blog/intro-to-cnns-part-1/
[7]: https://www.gwern.net/Scaling-hypothesis



{kind=link}
{kind=link}
{kind=link}
{kind=link}