
The potential of machine learning has grown significantly over the last decade following the improvements in computational power. However, to achieve accurate machine learning solutions, we need both complex architectures and enough data to feed it. Centralized solutions, where data is accumulated from different sources and stored on the central server to find a global model, require even more computational power due to exponentially increased parameter numbers. On the other hand, distributed solutions across multiple users can decrease the one big solution into small parts without raising data storage constraints.
Recently, advances in distributed machine learning approaches go beyond parallel computing power and focus on distributed data storage as well. In many real-world scenarios, the data is stored at the end user's device, such as mobile phones, personal computers, or browsers. Therefore, taking the full advantage of distributed on-device data for machine learning applications is the current direction in distributed learning. Federated Learning (first introduced in Ghosh et al. ) is the latest distributed learning framework that proposes training on locally stored data with local computational power while protecting privacy (McMahan et. al, 2017).
One of the problems with Federated Learning is the data heterogeneity. This can be partially attributed to different users having different data distributions. For a toy example, we can think of heterogeneity within hand written digit classification on a widely used dataset of MNIST (LeCun et al, 2010). Let’s say the data is distributed over computation units, which we call clients. If we have identically and independently distributed (IID) data among clients, each digit has the same frequency for each client. Nonetheless, if the distribution is non-IID for instance, one client only holds the "1"s in their local dataset. The other client may have some "1"s and half of "2"s. Maybe another holds "2"s and "3"s as illustrated in Figure[1]. In this case. data is partitioned among shards holding a heterogeneous distribution of the digits.
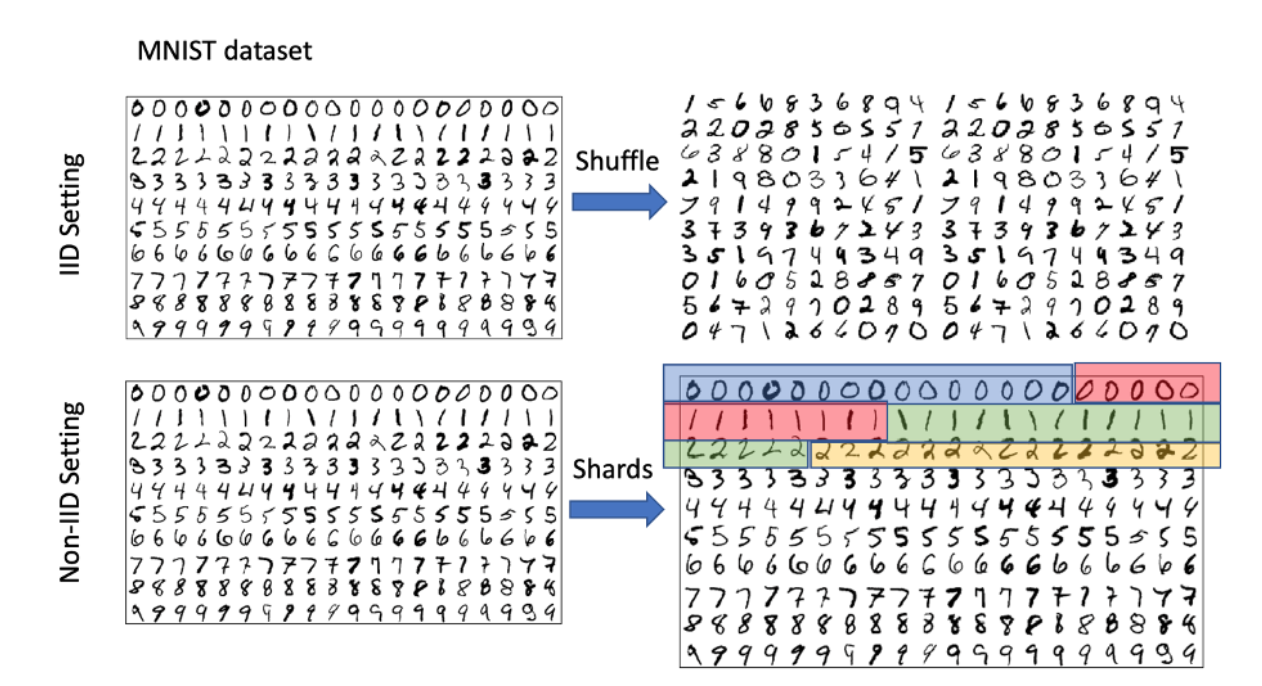
This local heterogeneity makes it challenging to achieve a global model solution that fits well for all the users. If Federated Learning methods can find a solution for this complexity, it can be the future of distributed learning.
To understand why we need Federated Learning in the first place, we need to answer what it can enable. Federated Learning changes the common understanding of privacy from not having any access to the data to "get useful insight from the data without revealing private information" (Nissenbaum et al, 2009). For example, Federated Learning allows us to gain insight from incredibly sensitive data such as text messages of people or the medication history of patients. Because the researchers are typically looking for statistical results rather than raw information. With Federated Learning, researchers can achieve statistical unbiased insight without even having access to data itself.
Whenever we want to get started with a learning method, even for the most straight forward dataset, we have to obtain a copy of that data in our system or cloud even just to start. Federated Learning can eliminate these necessities and the requirement of memory in the data centers to generate models. Because we can process the data where it is generated. For instance, it takes communication and memory costs to copy the text messages of the millions of people's phones to servers. With the help of federated learning we do not need to copy the data to some storage to test our model, instead we can train and test on the user's mobile devices.
When the models are trained on the users’ data, users enjoy the personalization and higher accuracy results. Each user is different, and finding a model that works universally for all of them is excessively hard to tackle. On the other hand, users prefer not to share their data due to privacy concerns. Seeing personalized adverts on social media makes users feel watched continuously and question; where is the data? Is it shared with 3rd parties? And more. One important aspect is that the business of the data. Selling data is a tough market because it is either too sensitive to be on the market or too cheap and fast consumed. Federated Learning can fix the broken market for everyone. Instead of selling user data, selling useful insight but maintaining control over the only copy of the sensitive information is a better long-term solution. It is also promising to enable adoption in the research directions that could not be investigated thoroughly before, such as lifestyle or medicine, because their datasets are hard to obtain and too sensitive to share with third parties.
The algorithm behind this scheme is still solving an empirical risk minimization similar to other deep learning problems. Available clients train the model by minimizing an average loss (i.e empirical risk) using optimization (typically stochastic gradient descent). Later, the weighted average of these losses across multiple clients is sent to the network. Therefore, the data center only sees the aggregated update. The difference from cloud-based training is that Federated Learning aims to compute and integrate the model immediately. Also, it enables us to perform more local updates on each client. There are several methods to aggregate on a global model using Federated Learning.
The most common aggregating algorithm is FedAvg (McMahan et. al, 2017), as illustrated in Figure 2, which applies weighted averaging after computing the gradients on each client. After each client calculates the gradient locally using stochastic gradient for some pass over the local data, they sent only the resulted gradients to the server. Then the servers take weighted average of all the gradients based on their local dataset size. It performs well on specific tasks and is especially suited for balanced and identically distributed data.
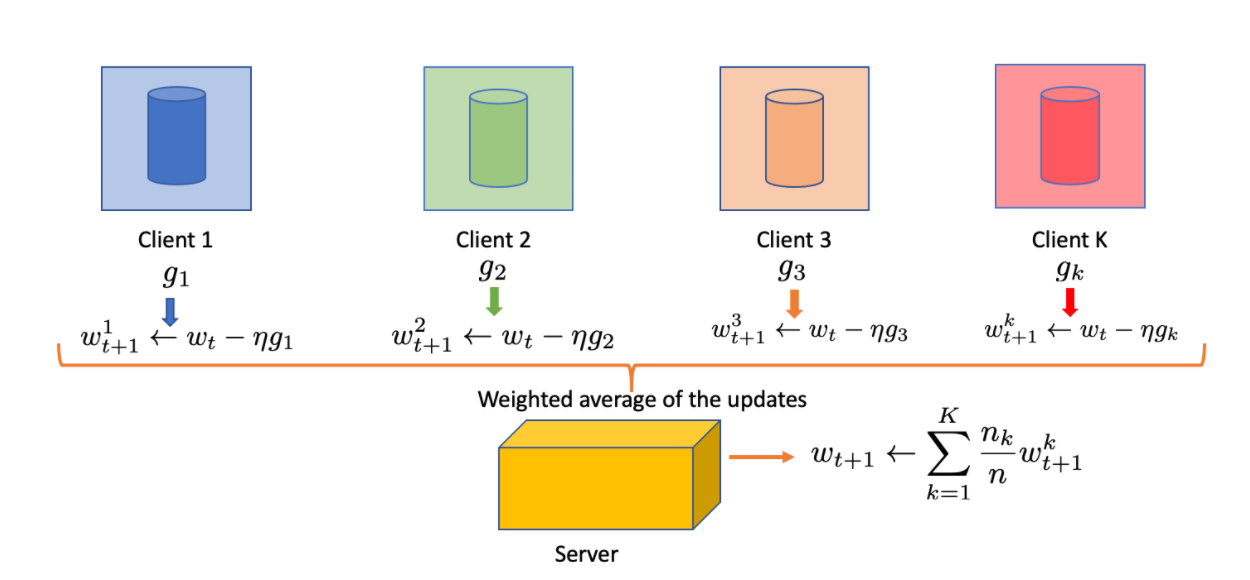
The data coming from different clients is not only unbalanced but also contains different distributions. Indeed, Federated Averaging reduces the communication cost between clients by performing multiple local updates on the available clients before communicating to the server. However, newly proposed methods are more suitable for more realistic scenarios that offer other update schemas to best suit the problem. The proposed FedProx (Li et al, 2018) algorithm empirically enhances the performance of Federated Averaging by introducing a proximal term as a regularizer. FedNova (Wang et al, 2020) allows the clients to use custom local step size and optimizer while still guaranteeing convergence. Recently, MOCHA (Smith et al, 2017) shows a good bound that this setting is also applicable to the multi-task learning. The more detailed information can be found in the recent survey (Li et al, 2020)
There are still open challenges, such as training a mobile phone model requires a stable internet connection and battery power. It is best to use nighttime for updating models and communicating with the server. Because users plug their phone on the charger and do not interact with the phone for 4-5 hours, however, the time difference can create some heterogeneity. What if the target users working on the night shift? What if the users have different time zones? The data heterogeneity and the system heterogeneity, the mobile phone's model, can also create challenges.
The dataset on the end-user is frequently changing. We can see that this can open new achievements, such as detecting the next word when the trends are changing continually. This year's "covid19", "mask," and "lockdown" on the text messages give us an idea about the changing trends. Also, geography adds more heterogeneity to your model. It is "bushfires" when users are located in Australia or "elections" when users in the states. This local heterogeneity makes it challenging to achieve a global model solution that fits all the users.
Moreover, utilizing distributed data can go beyond personalized apps on mobile phones. For example, hospital devices storing patients' data. Healthcare data is susceptible and required to be protected accordingly, following appropriate confidentiality procedures. Publishing the dataset to the public is restricted by hospital regularizations and depends on the patient's consent (van Panhuis et al, 2014). Regulations are not the only barrier for publication of health data. Even the name and age of the patient is removed, It is, for example, possible to reconstruct a patient’s face from computed tomography (CT) or magnetic resonance imaging (MRI) data (Schwarz et al, 2019). Therefore, anonymizing health data is not a easy task and to some extent, impossible to achieve.
Hospital data can be a good fit for Federated Learning (Rieke et al, 2020). For instance, hospitals can share their trained models to improve diagnosis systems. These models can benefit other patients in the world without sharing the patient's information. Recently, a Federated Learning model helped better understanding hospitalized COVID-19 patients (Flores, 2020). The model determines whether patients with COVID-19 symptoms will need supplemental oxygen. Twenty hospitals worldwide trust this global collaboration to benefit AI on a solution with the second wave of the pandemic.
Another example for hospitals can be for detecting brain tumors. MRI machines scans thousands of patient’s brains to detect tumors. Machine learning models already perform some results on public datasets such as public Kaggle dataset however the majority of the scans stay at the local archives of the clinical centers. In order to keep patient’s sensitive information, hospitals are not able to share their datasets (van Panhuis et al, 2014). Successful application of Federated Learning can enable significant amount of medical data. It is a privacy preserving model therefore, many more scans can contribute to the data hungry models to get better and unbiased results.
However, it is hard to detect anomalies in the hospital situation because machine learning models tend to generalize instead of particularizing. It can be a challenge to detect anomalies in one local region. People's genetic, environmental factors, and habits vary from region to region. Therefore, some diseases can be hard to be recognized if we don't adjust the model accordingly.
The current technical problems can be solved, but one main challenge with the medical setting is to be accountable and explainable of the model. More hospitals can leverage the benefits of federated learning standards. First, they need to understand that it has no harm to patients' privacy. It is essential to be well understood for patients, doctors, and technicians to understand the model and aggregation policies with other hospitals to explain it best to patients, increasing their chance of getting benefits. Second, we need new policies regarding these issues to enable more institutes to join new collaborations. Overall, Federated Learning is a promising way to leverage data in distributed servers and it opens a new doors for training deep learning models on sensitive data.
Author Bio
Zehra Hayirci is a researcher at Helmholtz AI Center Munich. Her research interests include machine learning, computer vision and computer graphics. She received her MSc. degree in computer science from Technical University of Munich and BSc. degree in computer engineering from Middle East Technical University, Ankara. You can find her publications at blog.zehrah.net and follow @zehayirci on Twitter.
Citation
For attribution in academic contexts or books, please cite this work as
Zehra Hayirci, "Decentralized AI For Healthcare", The Gradient, 2021.
BibTeX citation:
@article{hayirci2021decentralized,
author = {Hayirci, Zehra},
title = {Decentralized AI For Healthcare},
journal = {The Gradient},
year = {2021},
howpublished = {\url{https://thegradient.pub/decentralized-ai-for-healthcare/} },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.
References
McMahan, B., H., Moore, E., Ramage, D., Hampson, S., & Agüera y Arcas, B. (2017). Communication-efficient learning of deep networks from decentralized data. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, 54.
Ghosh, A., Chung, J., Yin, D., & Ramchandran, K. (2020). An Efficient Framework for Clustered Federated Learning.
Nissenbaum, H. (2009). Privacy in Context: Technology, Policy, and the Integrity of Social Life. Stanford University Press.
Smith, V., Chiang, C.-K., Sanjabi, M., & Talwalkar, A. (2017). Federated Multi-Task Learning. http://arxiv.org/abs/1705.10467
Wang, J., Liu, Q., Liang, H., Joshi, G., & Poor, H. V. (2020). Tackling the Objective Inconsistency Problem in Heterogeneous Federated Optimization. https://arxiv.org/abs/2007.07481
Li, T., Sahu, A. K., Zaheer, M., Sanjabi, M., Talwalkar, A., & Smith, V. (2018). Federated Optimization in Heterogeneous Networks. http://arxiv.org/abs/1812.06127
Li, T., Sahu, A. K., Talwalkar, A., & Smith, V. (2020). Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Processing Magazine, 37(3), 50–60. https://doi.org/10.1109/MSP.2020.2975749
van Panhuis, W. G., Paul, P., Emerson, C., Grefenstette, J., Wilder, R., Herbst, A. J., Heymann, D., & Burke, D. S. (2014). A systematic review of barriers to data sharing in public health. BMC Public Health, 14(1), 1144. https://doi.org/10.1186/1471-2458-14-1144
Schwarz, C. G., Kremers, W. K., Therneau, T. M., Sharp, R. R., Gunter, J. L., Vemuri, P., Arani, A., Spychalla, A. J., Kantarci, K., Knopman, D. S., Petersen, R. C., & Jack, C. R., Jr (2019). Identification of Anonymous MRI Research Participants with Face-Recognition Software. The New England journal of medicine, 381(17), 1684–1686. https://doi.org/10.1056/NEJMc1908881
Rieke, N., Hancox, J., Li, W., Milletarì, F., Roth, H. R., Albarqouni, S., Bakas, S., Galtier, M. N., Landman, B. A., Maier-Hein, K., Ourselin, S., Sheller, M., Summers, R. M., Trask, A., Xu, D., Baust, M., & Cardoso, M. J. (2020). The future of digital health with federated learning. Npj Digital Medicine, 3(1), 1–7. https://doi.org/10.1038/s41746-020-00323-1
https://blogs.nvidia.com/blog/2020/10/05/federated-learning-covid-oxygen-needs/
https://www.kaggle.com/navoneel/brain-mri-images-for-brain-tumor-detection
LeCun, Y. & Cortes, C. (2010). MNIST handwritten digit database.



{kind=link}
{kind=link}
{kind=link}
{kind=link}