
Humanity’s rich history has left behind an enormous number of historical documents and artifacts. However, virtually none of these documents, containing stories and recorded experiences essential to our cultural heritage, can be understood by non-experts due to language and writing changes over time.
For instance, archaeologist have unearthed tens of thousands of clay tablets from ancient Babylon [1] , yet only a few hundred specially trained scholars can translate them. The vast majority of these documents have never been read, even if they were uncovered in the 1800s. To give a further illustration of the challenge posed by this scale, a tablet from the Tale of Gilgamesh was collected in an expedition in 1851, but its significance was not brought to light until 1872. This tablet contains a pre-biblical flood narrative, which has enormous cultural significance as a precursor to the Noah’s Ark narrative.
This is a global problem, yet one of the most striking examples is the case of Japan. From 800 until 1900 CE, Japan used a writing system called Kuzushiji, which was removed from the curriculum in 1900 when the elementary school education was reformed. Currently, the overwhelming majority of Japanese speakers cannot read texts which are more than 150 years old. The volume of these texts — comprised of over three million books in storage but only readable by a handful of specially-trained scholars — is staggering. One library alone has digitized 20 million pages from such documents. The total number of documents — including, but not limited to, letters and personal diaries — is estimated to be over one billion. Given that very few people can understand these texts, mostly those with PhDs in classical Japanese literature and Japanese history, it would be very expensive and time-consuming to finance for scholars to convert these documents to modern Japanese. This has motivated the use of machine learning to automatically understand these texts.
This is a difficult task. Kuzushiji is written in a script which differs substantially from modern Japanese, making even basic recognition difficult for contemporary Japanese. However, once Kuzushiji has been converted to the modern script, it is readable by most people fluent in Japanese. Even so, some difficulties remain due to changes in grammar and vocabulary.
Given its importance to Japanese culture, the problem with utilizing computers to help with Kuzushiji recognition has been explored extensively [2] through the use of various methods in deep learning and computer vision. However, these models were unable to achieve strong performance on Kuzushiji recognition. This was due to inadequate understanding of Japanese historical literature in the optical character recognition (OCR) community and the lack of high quality standardized datasets.
To address this, the National Institute of Japanese Literature (NIJL) created and released a Kuzushiji dataset, curated by the Center for Open Data in the Humanities (CODH). The dataset currently has over 4000 character classes and a million character images. Before the release of this Kuzushiji dataset, OCR researchers tried to create datasets themselves. However, the number of characters was very limited which made their models perform poorly when evaluated on the full range of data. The NIJL-CODH addressed this problem by providing a large and comprehensive Kuzushiji dataset for researchers to train and evaluate on.
There are several reasons why Kuzushiji recognition is challenging:
-
Capturing both local and global context is important. Owing to the fact that some characters are written in a contextually dependent way, it is important to consider multiple characters while classifying, rather than considering each character individually.
-
The total number of characters in the vocabulary is very large. Specifically, the NIJL-CODH dataset has over 4300 characters, while, in reality, there are a lot more characters. Moreover, the dataset follows a long-tailed distribution, so there are many characters which only appear a few times or even once in the dataset,which contains 44 books.
-
Many characters can be written in multiple ways, based on Hentaigana. Hentaigana is the old way of writing Hiragana or Japanese phonetic characters with the characteristic that many characters can be mapped to one character today. The concept of Hentaigana is seen to be difficult for modern Japanese readers to understand.
-
Kuzushiji texts are often written together with illustrations and elaborate backgrounds, which are often hard to cleanly separate from text. These are common because the most popular printing system in premodern Japan was woodblock printing, which involves carving a whole piece of wood along with illustrations. Therefore, the page layout can be complicated and artistic, and is not always easy to represent as a sequence.


- Chirashigaki was a method of writing popular in premodern Japanese due to the aesthetic appeal of the text. This writing style was common in personal letters and poems. When humans read these documents, they decided where to start reading based on the size of characters and the darkness of the ink. This is one reason why conventional sequence models do not have the capability to work well with many Kuzushiji documents.

KuroNet
KuroNet is a Kuzushiji transcription model that I developed with my collaborators, Tarin Clanuwat and Asanobu Kitamoto from the ROIS-DS Center for Open Data in the Humanities at the National Institute of Informatics in Japan. The KuroNet method is motivated by the idea of processing an entire page of text together, with the goal of capturing both long-range and local dependencies. KuroNet passes images containing an entire page of text through a residual U-Net architecture (FusionNet) in order to obtain a feature representation. However, the total number of character classes in our dataset is relatively large at over 4300. Therefore, we found that predicting the exact character at each position was too computationally expensive, and, in hopes of solving this, we introduced an approximation, which initially estimates whether a spatial position contains a character. From there, it only computes the relatively expensive character classifier at positions which contain characters, according to the ground truth. This technique, which is an example of Teacher Forcing, helps to dramatically lower memory usage and computation.
We also examined using data augmentation to improve generalization performance, which is known to be especially important for deep learning when the amount of labeled data is limited. We explored a variant of the Mixup regularizer [3], in which we interpolated a small amount in the direction of random different examples while retaining the original label. Many books are written on a relatively thin paper, so the content of the adjacent page is often faintly visible through the paper. The images produced by Mixup appear somewhat similar to images where the adjacent page's content are faintly visible. Therefore, Mixup may have an added benefit of helping encourage the model to ignore the adjacent page.
For more information about KuroNet, please checkout our paper KuroNet: Pre-Modern Japanese Kuzushiji Character Recognition with Deep Learning, which was accepted to the 2019 International Conference on Document Analysis and Recognition (ICDAR) [4].

KuroNet can transcribe an entire Kuzushiji page with an average time of 1.2 seconds per page, including a post-processing pipeline that is not carefully optimized. Even though performance still varies greatly between books, we found that woodblock printed books from the Edo period — 17th to 19th century — are where KuroNet performs well. We found that the model struggles with unusually sized and rare characters. Furthermore, we evaluated the model on held-out pages from a variety of books and found that the worst performing books were dictionaries which contains many unusual characters, and a cookbook, with many illustrations and unusual layouts.
Kaggle Kuzushiji Recognition Competition

While KuroNet achieved state-of-the-art results at the time of its development and was published in the top tier conference on document analysis and recognition, we wanted to open this research up to the broader community. We did this partially to stimulate further research on Kuzushiji and to discover ways in which KuroNet may be deficient.
Ultimately, after 3 months of competition, which saw 293 teams, 338 competitors, and 2652 submissions, the winner achieved an F1 score of 0.950. When we evaluated KuroNet on the same setup, we found that it achieved an F1 score 0.902, which would have put it in 12th place — which, although acceptable, remains well below the best performing solutions.
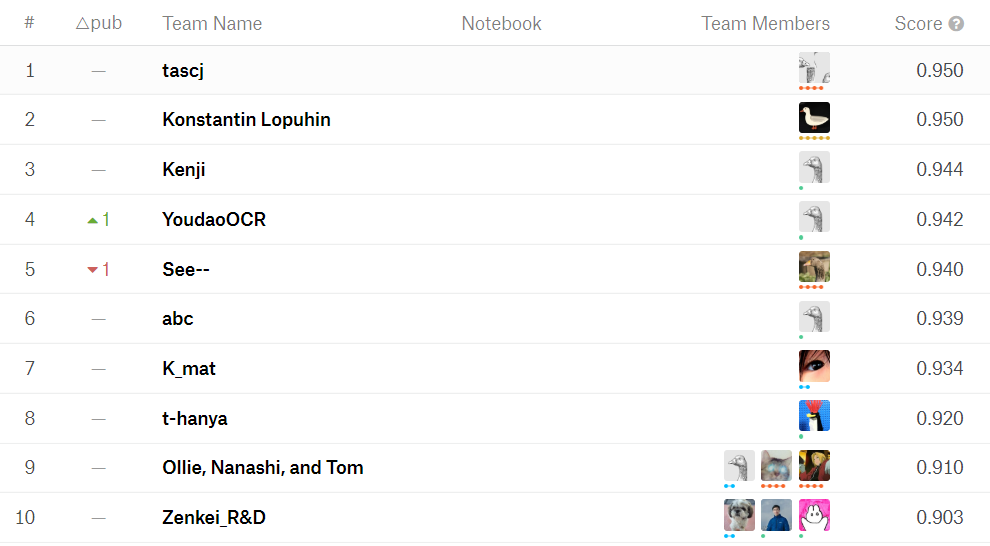
There are several important lessons that we learned from hosting this Kaggle competition:
-
Some existing object detection algorithms work quite well on this task, even when used “out of the box.” For example, Faster R-CNN and Cascade R-CNN produced excellent results without modification or any Kuzushiji-specific techniques. Given how different Kuzushiji pages are from the usual object detection tasks, it was rather surprising that they still performed well.
-
At the same time, other techniques perform poorly when used without modification. For example, You Only Look Once (YOLO) performed quite badly despite substantial effort. Other techniques using CenterNet performed well, but required more effort and domain-specific tuning to get working.
-
Several leading approaches had models that performed detection and classification jointly. Those that did not employ clever techniques for incorporating surrounding characters in their classification pipeline.
-
Few of the top solutions used language models or tried to treat the characters as sequences.
Future Research
The work done by CODH has already led to substantial progress in transcribing Kuzushiji documents, however, the overall problem of unlocking the knowledge of historical documents is far from solved.
Even in the domain of transcribing Kuzushiji, there are still substantial open challenges. One challenge is that the labeled training data tends to come from whole pages of text, with a focus on documents from a particular time period (mostly the late Edo Period, 17th to 19th century). However there are many other types of Kuzushiji text that a person might want to transcribe. Some documents are handwritten, whereas others are printed (typically using woodblocks). Some types of pages have atypical or rarely seen content — such as the title pages of books. I met someone in Japan who had been hiking through the mountains and found a stone pathmarker written in Kuzushiji, and wanted to have it transcribed. Generalizing to these very different kinds of data, especially when the medium for the writing changes, can be quite difficult, although this has come under increasing attention as a research area in machine learning. The invariant risk minimization technique [5] focuses on this very problem.
Another exciting open problem comes from the fact that all of the proposed techniques only convert Kuzushiji documents into the modern Japanese script. This makes the individual characters recognizable, but the overall text is still quite difficult to read. From discussing with native Japanese speakers, I have the impression that it is possible to read for a normal Japanese person, but is moderately harder than reading Shakespeare is for contemporary English speakers. Thus, an exciting and very open Machine Learning problem would be converting from the older language to the vocabulary and grammar of modern Japanese. This problem is accessible, as there are many cases where an outdated word could be swapped with a more modern word, but is also very deep, as translating poetry and beautiful prose correctly, with its many nuances, could be nearly impossible. Additionally, the lack (or small volume) of cleanly aligned paired data from classical and modern Japanese may motivate the use of recent research on unsupervised and low resource machine translation.
I believe that this is one of the most impactful applications for machine learning today, and making progress will require collaboration between those with both domain-specific expertise in historical documents, applied ML researchers, and basic ML algorithm researchers. This needs to be an interdisciplinary effort. Historians can help to identify the most relevant subproblems and can intuitively judge whether metrics are actually useful. Applied ML researchers can build models to optimize these metrics and identify where today’s algorithms fall short. Basic ML researchers can help to make the algorithms better. For example, our work on Japanese requires better algorithms for few-shot learning as well as better generalization to changing environments, both of which are increasingly widely studied problems in the ML research community.
At the same time, this needs to be an international effort. Inaccessible documents are a problem for historical languages from all over the world, and only by engaging researchers from around the world, can we hope to make progress. It is also important to engage with indigenous communities which have great historical heritage but may be underrepresented in certain research fields.
The value of history and literature education is hugely underestimated in many places around the world. In our world of growing deception and fake news, a deeper knowledge of history is more important than ever. Making historical document more accessible and understandable can help to raise awareness of the importance of this education, by allowing students to interact with a much vaster amount of content and in a more organic and accessible way. In the case of Japan, I hope that our work will allow students and the general public to read historical stories the way that they were meant to be read - alongside rich illustrations and in an accessible writing style. I also hope that this will let them choose between a much greater variety of content including action, comedy, and adventure, making these studies much more pleasurable and accessible.
Zhang, Hongyi, et al. "mixup: Beyond empirical risk minimization." ICLR 2018. ↩︎
Clanuwat, Tarin, Alex Lamb, and Asanobu Kitamoto. "KuroNet: Pre-Modern Japanese Kuzushiji Character Recognition with Deep Learning." ICDAR 2019. ↩︎
Arjovsky, Martin, et al. "Invariant risk minimization." arXiv preprint arXiv:1907.02893 (2019). ↩︎
Author Bio
Alex Lamb is a PhD student at the Universite de Montreal and the Montreal Institute for Learning Algorithms (MILA). His major research interests are new architectures and techniques for deep learning which improve generalization and modularity.
Acknowledgments
Special thanks to the National Institute of Japanese Literature (NIJL) for constructing the dataset and the National Institute of Informatics (NII) for co-organizing the competition.
Citation
For attribution in academic contexts or books, please cite this work as
ALex Lamb, "How Machine Learning Can Help Unlock the World of Ancient Japan", The Gradient, 2019.
BibTeX citation:
@article{lamb2019unlocking,
author = {Lamb, Alex},
title = {How Machine Learning Can Help Unlock the World of Ancient Japan},
journal = {The Gradient},
year = {2019},
howpublished = {\url{https://thegradient.pub/gaussian-process-not-quite-for-dummies/ } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.



{kind=link}
{kind=link}
{kind=link}
{kind=link}