
What's the current state of research in AI focusing on Robotics? This article will briefly summarize the technical work presented at RSS 2019 Conference. Let's start by knowing more about the conference.
The Robotics Science and Systems conference (RSS), along with ICRA and IROS, is among the top three conferences for robotics with a good proportion of papers on the intersection of Learning and Robotics being published.
"RSS aspires to be the conference where new bold ideas are presented and where lively debates in the community are initiated. RSS also aspires to be the conference that influences people’s future research activities, and advances our field through a scientific discourse based on multiple views and approaches. The RSS Foundation is very much interested in promoting these high aspirations." - RSS Foundation
This year, it took place between June 22 to June 26 at The University of Freiburg, Freiburg, Germany. With around 272 number of total submissions, 85 papers were accepted. The accepted papers were presented on stage as a 5min talk with a video playing behind. The conference had 3 early career talks by talented young academics summarizing their ongoing work, 4 keynote talks by prominent researchers explaining their thoughts, each talk lasting around 1 hour. What differentiates RSS from ICRA and IROS is that RSS is a single track conference, which simply means that there is only one stage where only one talk is presented at a time.
Workshops
The first two days were scheduled for workshops, which, unlike the main conference, happen simultaneously over a full day.
I arrived mid day for the Combining Learning and Reasoning workshop. The room was full of researchers with people standing outside listening through the windows. The main debate of the whole workshop was
"How do we combine existing knowledge with data-driven learning? What should be built in and what should be learned?"
Reasoning, in the context of Robotics, in a general sense, deals with making computations over multiple time steps in the future to fulfill an objective, for example, computing actions to take at each time step in order to reach a destination location. Learning, on the other hand, deals with leveraging past experiences to make fast and more accurate decisions without necessarily looking into the future, for example, to decide whether an image contains a cat. The paradigms of Reasoning and Learning can be combined in creative ways to solve problems in a better way, For example, to make a better chess playing AI (AlphaZero) by leveraging learning to learn how good a chess position is in order to guide the reasoning process. Interested readers are encouraged to go through this post for a brilliantly written and thorough overview on combining learning and reasoning.
On the second day, I attended the Robust autonomy: Safe robot learning and control in uncertain real-world environments Workshop. Invited talks focused mainly on theoretical aspects of safety as well as on real world practical methods. It was quite inspiring to observe how deeply the researchers cared about the safety aspects of the systems they created. The aim of the workshop was to
“Provide a forum for discussion among researchers, industry, and regulators as to the core challenges, promising solution strategies, fundamental limitations, and regulatory realities involved in deploying safety-critical systems.”
Safety, is a very important issue in current times. As we see more and more autonomous systems being deployed in the real world, it is imperative to define what safety is and understand, quantify and improve the degree to which these systems are safe in order to trust these systems with making decisions autonomously. I found this post to be quite comprehensive in summarizing the current state of research in AI safety.
Main Conference
There has been a growing trend in robotics research of incorporating ideas from Machine Learning, Computer Vision and Natural Language Processing. Especially, core ideas from the field of deep learning are being applied creatively in a variety of subfields of robotics (Navigation, control, planning to name a few). It’s a truly exciting time and place to be in.
After having a glance at the paper titles and abstracts, I found around 40 papers out of the total 85 accepted papers to incorporate some learning based method! For the sake of brevity, I would deliberately skip over a lot of papers and list out a few papers from diverse subfields I found to be interesting. Interested readers are encouraged to check out all the paper titles and abstracts here. Let’s get started.
Themes
Autonomous Driving
Autonomous driving, as most of you know, is a highly popular research topic these days, with both academia and industry racing to solve it. It is an extremely hard problem to solve in my opinion, owing to the near infinite unseen situations an agent would face during deployment. Decision making is one of the most difficult aspects of this field. How should the autonomous agent take a decision from all the information it has currently? How should the agent integrate all the information it has from the past until present to help it make better decisions? Some of the works presented at RSS try to answer these questions.
LeTS-Drive: Driving among a Crowd by Learning from Tree Search
Panpan Cai, Yuanfu Luo, Aseem Saxena, David Hsu, Wee Sun Lee
National University of Singapore
Abstract
Autonomous driving in a crowded environment, e.g., a busy traffic intersection, is an unsolved challenge for robotics. The robot vehicle must contend with a dynamic and partially observable environment, noisy sensors, and many agents. A principled approach is to formalize it as a Partially Observable Markov Decision Process (POMDP) and solve it through online belief-tree search. To handle a large crowd and achieve real-time performance in this very challenging setting, we propose LeTS-Drive, which integrates online POMDP planning and deep learning. It consists of two phases. In the offline phase, we learn a policy and the corresponding value function by imitating the belief tree search. In the online phase, the learned policy and value function guide the belief tree search. LeTS-Drive leverages the robustness of planning and the runtime efficiency of learning to enhance the performance of both. Experimental results in simulation show that LeTS-Drive outperforms either planning or imitation learning alone and develops sophisticated driving skills.
One Line Summary - Approach for Autonomous Driving in crowded environments by first imitating an expert, then leveraging the imitation agent in order to guide the belief tree search reasoning process, resulting in an agent with sophisticated driving skills outperforming either reasoning or imitation alone.
ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst
Mayank Bansal, Alex Krizhevsky, Abhijit Ogale
Waymo Research
Abstract
Our goal is to train a policy for autonomous driving via imitation learning that is robust enough to drive a real vehicle. We find that standard behavior cloning is insufficient for handling complex driving scenarios, even when we leverage a perception system for preprocessing the input and a controller for executing the output on the car: 30 million examples are still not enough. We propose exposing the learner to synthesized data in the form of perturbations to the expert's driving, which creates interesting situations such as collisions and/or going off the road. Rather than purely imitating all data, we augment the imitation loss with additional losses that penalize undesirable events and encourage progress -- the perturbations then provide an important signal for these losses and lead to robustness of the learned model. We show that the ChauffeurNet model can handle complex situations in simulation, and present ablation experiments that emphasize the importance of each of our proposed changes and show that the model is responding to the appropriate causal factors. Finally, we demonstrate the model driving a real car at our test facility.
One Line Summary - Imitation of human expert for Autonomous Driving by adding disturbances to expert decisions in order to encounter complex scenarios and penalizing undesirable events by adding auxiliary losses during training.
Robotic Manipulation
Autonomous robots are increasingly finding a place in warehouses and households. To be effective in these places, these robots need to be good at manipulation of arbitrarily shaped objects to begin with. Objects can be manipulated in a lot of ways like grasping, pushing, pulling, screwing, squeezing to name the most basic ones. Learning can help robots generalize over different shapes of objects and different environmental conditions (surface friction for pushing/pulling). A lot of works presented at RSS focus on different manipulation problems like grasping, rope knotting to name a few.
Autonomous Tool Construction Using Part Shape and Attachment Prediction
Lakshmi Nair, Nithin Shrivatsav, Zackory Erickson and Sonia Chernova
Georgia Institute of Technology
Abstract
This work explores the problem of robot tool construction - creating tools from parts available in the environment. We advance the state-of-the-art in robotic tool construction by introducing an approach that enables the robot to construct a wider range of tools with greater computational efficiency. Specifically, given an action that the robot wishes to accomplish and a set of building parts available to the robot, our approach reasons about the shape of the parts and potential ways of attaching them, generating a ranking of part combinations that the robot then uses to construct and test the target tool. We validate our approach on the construction of five tools using a physical 7-DOF robot arm.
One Line Summary - Autonomous robot tool construction by reasoning about shapes of component parts and potential ways of attaching them, thus creating a ranking of part combinations.
Learning Robotic Manipulation through Visual Planning and Acting
Angelina Wang, Thanard Kurutach, Kara Liu, Pieter Abbeel, Aviv Tamar
UC Berkeley, Technion
Abstract
Planning for robotic manipulation requires reasoning about the changes a robot can affect on objects. When such interactions can be modelled analytically, as in domains with rigid objects, efficient planning algorithms exist. However, in both domestic and industrial domains, the objects of interest can be soft, or deformable, and hard to model analytically. For such cases, we posit that a data-driven modelling approach is more suitable. In recent years, progress in deep generative models has produced methods that learn to 'imagine' plausible images from data. Building on the recent Causal InfoGAN generative model, in this work we learn to imagine goal-directed object manipulation directly from raw image data of self-supervised interaction of the robot with the object. After learning, given a goal observation of the system, our model can generate an imagined plan -- a sequence of images that transition the object into the desired goal. To execute the plan, we use it as a reference trajectory to track with a visual servoing controller, which we also learn from the data as an inverse dynamics model. In a simulated manipulation task, we show that separating the problem into visual planning and visual tracking control is more sample efficient and more interpretable than alternative data-driven approaches. We further demonstrate our approach on learning to imagine and execute in 3 environments, the final of which is deformable rope manipulation on a PR2 robot.
One Line Summary - Manipulation of objects which are soft and deformable by learning to imagine plausible visual appearances of a particular object using Causal InfoGAN generative model.
Control
The field of Robot control aims at controlling robots to reliably, accurately and safely execute high level actions. Due to imperfect motors for wheels, joints and rotors, there is an error between expected and actual actions being executed. These errors accumulate over multiple time steps and can be catastrophic. Therefore, some form of feedback is important to minimize the error. We can further improve the controllers by making the controllers predict the near future from the current state and adjust accordingly. The field of model predictive control specifically focuses on this aspect. Learning comes in the picture, as it helps in building better models for predicting the future. MPC is especially applied in situations like autonomous car racing, drone acrobatics to name a few.
Inverting Learned Dynamics Models for Aggressive Multirotor Control
Alexander Spitzer, Nathan Michael
Carnegie Mellon University
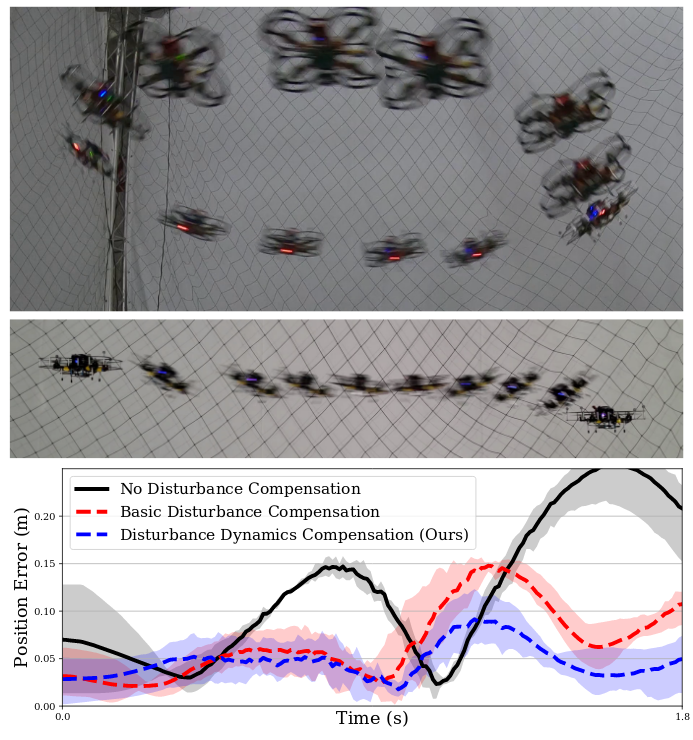
Abstract
We present a control strategy that applies inverse dynamics to a learned acceleration error model for accurate multirotor control input generation. This allows us to retain accurate trajectory and control input generation despite the presence of exogenous disturbances and modeling errors. Although accurate control input generation is traditionally possible when combined with parameter learning-based techniques, we propose a method that can do so while solving the relatively easier non-parametric model learning problem. We show that our technique is able to compensate for a larger class of model disturbances than traditional techniques can and we show reduced tracking error while following trajectories demanding accelerations of more than 7 m/s^2 in multirotor simulation and hardware experiments.
One Line Summary - Approach for controlling a robot to execute aggresive multirotor trajectories by learning a non parametric acceleration error model.
Highly Parallelized Data-Driven MPC for Minimal Intervention Shared Control
Alexander Broad, Todd Murphey, Brenna Argall
Northwestern University, Shirley Ryan AbilityLab
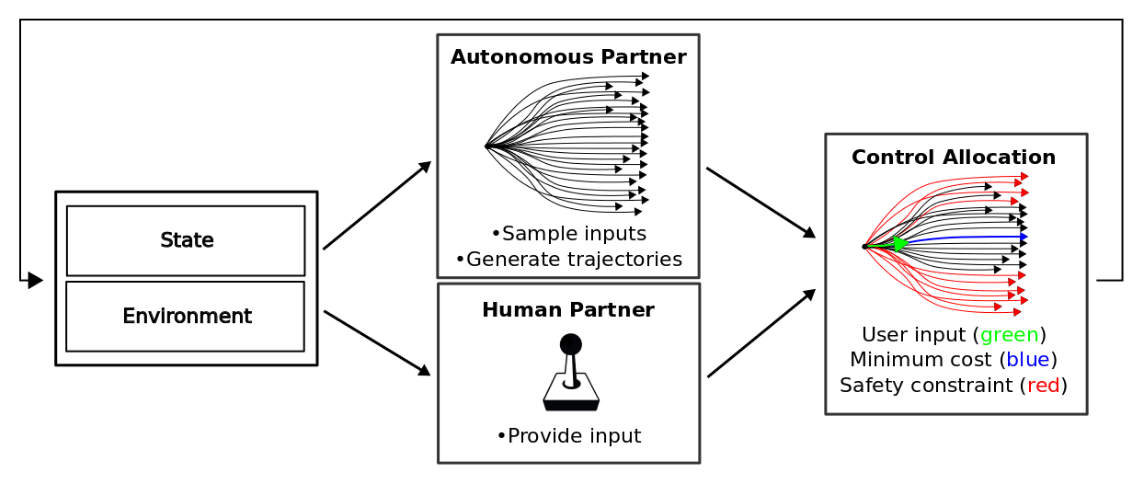
Abstract
We present a shared control paradigm that improves a user's ability to operate complex, dynamic systems in potentially dangerous environments without a priori knowledge of the user's objective. In this paradigm, the role of the autonomous partner is to improve the general safety of the system without constraining the user's ability to achieve unspecified behaviors. Our approach relies on a data-driven, model-based representation of the joint human-machine system to evaluate, in parallel, a significant number of potential inputs that the user may wish to provide. These samples are used to (1) predict the safety of the system over a receding horizon, and (2) minimize the influence of the autonomous partner. The resulting shared control algorithm maximizes the authority allocated to the human partner to improve their sense of agency, while improving safety. We evaluate the efficacy of our shared control algorithm with a human subjects study (n=20) conducted in two simulated environments: a balance bot and a race car. During the experiment, users are free to operate each system however they would like (i.e., there is no specified task) and are only asked to try to avoid unsafe regions of the state space. Using modern computational resources (i.e., GPUs) our approach is able to consider more than 10,000 potential trajectories at each time step in a control loop running at 100Hz for the balance bot and 60Hz for the race car. The results of the study show that our shared control paradigm improves system safety without knowledge of the user's goal, while maintaining high-levels of user satisfaction and low-levels of frustration. Our code is available online at https://github.com/asbroad/mpmi_shared_control.
One Line Summary - Paradigm for controlling a robot both autonomously and manually via a data-driven, model-based representation of the system to predict the safety of the system in the near future and to minimize the influence of the autonomous component, resulting in a safer system and an improved sense of agency in the human user.
Sim2Real
Robotics, in a nutshell, aims for reliable control of agents in order to solve various problems (navigation, manipulation etc). Collecting data for applying learning based methods in robotics in the real world can be slow, expensive and unsafe. It is not possible to capture all situations a robot might face in the real world in a limited amount of time. Advances in the field of computer graphics and availability of large compute come to the rescue. It is now possible for simulated robots to collect huge amounts of data in a hyper-realistic simulated world in a reasonable amount of time in a safe manner. In practice though, the models learnt on simulated data do not transfer well to the real world. The field of Sim2Real tries to solve this problem.
BayesSim: Adaptive Domain Randomization Via Probabilistic Inference for Robotics Simulators
Fabio Ramos, Rafael Carvalhaes Possas, Dieter Fox
NVIDIA, University of Sydney, University of Washington

Abstract
We introduce BayesSim, a framework for robotics simulations allowing a full Bayesian treatment for the parameters of the simulator. As simulators become more sophisticated and able to represent the dynamics more accurately, fundamental problems in robotics such as motion planning and perception can be solved in simulation and solutions transferred to the physical robot. However, even the most complex simulator might still not be able to represent reality in all its details either due to inaccurate parametrization or simplistic assumptions in the dynamic models. BayesSim provides a principled framework to reason about the uncertainty of simulation parameters. Given a black-box simulator (or generative model) that outputs trajectories of state and action pairs from unknown simulation parameters, followed by trajectories obtained with a physical robot, we develop a likelihood-free inference method that computes the posterior distribution of simulation parameters. This posterior can then be used in problems where Sim2Real is critical, for example in policy search. We compare the performance of BayesSim in obtaining accurate posteriors in a number of classical control and robotics problems, and show that the posterior computed from BayesSim can be used for domain randomization outperforming alternative methods that randomize based on uniform priors.
One Line Summary - Approach to Sim2Real by formulating a principled framework for reasoning about the posterior distribution of simulation model parameters computed via a likelihood-free inference method.
Social Robotics
"A social robot is an autonomous robot that interacts and communicates with humans or other autonomous physical agents by following social behaviors and rules attached to its role. Like other robots, a social robot is physically embodied." - Wikipedia
The field of social robotics is closely tied to ‘Affective Computing’, a term coined by Dr. Rosalind Picard from the Affective Computing group at the MIT Media Lab.
“Affective Computing is computing that relates to, arises from, or deliberately influences emotion or other affective phenomena” - Rosalind Picard
It’s an exciting time to be in, witnessing the development of social robots such as Sophia, Anki, Pepper and Nao to name a few. It is hard not to imagine a future where robots could understand human affect reliably and interact accordingly. This line of work is not popular at RSS, with only a single paper accepted this year.
Predicting Human Interpretations of Affect and Valence in a Social Robot
Casey Kennington, David McNeill
Boise State University

Abstract
As the adoption of robots becomes widespread across more industries and domains, those robots will be placed in new contexts where they will interact with people who do not understand how they work. The consequences of such a disparity can already be seen in how people assign anthropomorphic characteristics to those robots, despite what what the robot designers may have intended. In this paper, we seek to understand how people interpret a social robot's performance of an emotion, what we term 'affective display,' and the positive or negative valence of that affect. To this end, we tasked annotators with observing the Anki Cozmo robot perform its over 900 pre-scripted behaviors and labeling those behaviors with 16 possible affective display labels (e.g., interest, boredom, disgust, etc.). In our first experiment, we trained a neural network to predict annotated labels given multimodal information about the robot's movement, face, and audio. The results suggest that pairing affects to predict the valence between them is more informative, which we confirmed in a second experiment. Both experiments show that certain modalities are more useful for predicting displays of affect and valence. For our final experiment, we generated novel robot behaviors and tasked human raters with assigning scores to valence pairs instead of applying labels, then compared our model's predictions of valence between the affective pairs and compared the results to the human ratings. We conclude that robot designers and researchers cannot assume that people will perceive affect or valence as designed, and make several suggestions for directions of future work.
One Line Summary - Understand how humans interpret a social robot's display of an emotion, concluding that humans might not percieve a social robot's emotion the way its designer intended.
Algorithm as a Neural Network
Quite a few research groups are working on reformulating traditional probabilistic methods like Particle Filters as neural networks. The main advantage offered by differentiable formulations is that they can handle modelling errors and approximations more robustly and can potentially run faster than their traditional counterparts.
Differentiable Algorithm Networks for Composable Robot Learning
Peter Karkus, Xiao Ma, David Hsu, Leslie Pack Kaelbling, Wee Sun Lee, Tomás Lozano-Pérez
National University of Singapore, Massachusetts Institute of Technology
Abstract
This paper introduces the Differentiable Algorithm Network (DAN), a composable architecture for robot learning systems. A DAN is composed of neural network modules, each encoding a differentiable robot algorithm and an associated model; and it is trained end-to-end from data. DAN combines the strengths of model-driven modular system design and data-driven end-to-end learning. The algorithms and models act as structural assumptions to reduce the data requirements for learning; end-to-end learning allows the modules to adapt to one another and compensate for imperfect models and algorithms, in order to achieve the best overall system performance. We illustrate the DAN methodology through a case study on a simulated robot system, which learns to navigate in complex 3-D environments with only local visual observations and an image of a partially correct 2-D floor map.
One Line Summary - DAN consists of different modules, each module encoding a differential algorithm along with an associated model, which can be trained end to end and allows the modules to adapt to one another and compensate for imperfect models and algorithms.
Value Iteration Networks on Multiple Levels of Abstraction
Daniel Schleich, Tobias Klamt, and Sven Behnke
Rheinische Friedrich-Wilhelms-Universit ̈at Bonn, Autonomous Intelligent Systems, Bonn, Germany
Abstract
Learning-based methods are promising to plan robot motion without performing extensive search, which is needed by many non-learning approaches. Recently, Value Iteration Networks (VINs) received much interest since---in contrast to standard CNN-based architectures---they learn goal-directed behaviors which generalize well to unseen domains. However, VINs are restricted to small and low-dimensional domains, limiting their applicability to real-world planning problems. To address this issue, we propose to extend VINs to representations with multiple levels of abstraction. While the vicinity of the robot is represented in sufficient detail, the representation gets spatially coarser with increasing distance from the robot. The information loss caused by the decreasing resolution is compensated by increasing the number of features representing a cell. We show that our approach is capable of solving significantly larger 2D grid world planning tasks than the original VIN implementation. In contrast to a multiresolution coarse-to-fine VIN implementation which does not employ additional descriptive features, our approach is capable of solving challenging environments, which demonstrates that the proposed method learns to encode useful information in the additional features. As an application for solving real-world planning tasks, we successfully employ our method to plan omnidirectional driving for a search-and-rescue robot in cluttered terrain.
One Line Summary - Extending Value Iteration Networks by modifying representations to different levels of details in order to reason over high dimensional state spaces in a reasonable amount of time.
Awards
Let’s get to know the papers which the RSS Committee deemed as important. For the sake of brevity, I unfortunately, have to ommit the nominated papers which did not win the award.
Best Systems Paper Award in Memory of Seth Teller
Learning to Throw Arbitrary Objects with Residual Physics
Andy Zeng, Shuran Song, Johnny Lee, Alberto Rodriguez, Thomas Funkhouser
Princeton University, Google, Columbia University, Massachusetts Institute of Technology
Abstract
We investigate whether a robot arm can learn to pick and throw arbitrary objects into selected boxes quickly and accurately. Throwing has the potential to increase the physical reachability and picking speed of a robot arm. However, precisely throwing arbitrary objects in unstructured settings presents many challenges: from acquiring reliable pre-throw conditions (e.g. initial pose of object in manipulator) to handling varying object-centric properties (e.g. mass distribution, friction, shape) and dynamics (e.g. aerodynamics). In this work, we propose an end-to-end formulation that jointly learns to infer control parameters for grasping and throwing motion primitives from visual observations (images of arbitrary objects in a bin) through trial and error. Within this formulation, we investigate the synergies between grasping and throwing (i.e., learning grasps that enable more accurate throws) and between simulation and deep learning (i.e., using deep networks to predict residuals on top of control parameters predicted by a physics simulator). The resulting system, TossingBot, is able to grasp and throw arbitrary objects into boxes located outside its maximum reach range at 500+ mean picks per hour (600+ grasps per hour with 84% throwing accuracy); and generalizes to new objects and landing locations.
One Line Summary - Make a robot arm learn to pick and throw arbitrary objects quickly and accurately by jointly learning control parameters for grasping and throwing motion primitives from visual observations.
Best Student Paper Award
An Online Learning Approach to Model Predictive Control
Nolan Wagener, Ching-An Cheng, Jacob Sacks, Byron Boots
Georgia Institute of Technology
Abstract
Model predictive control (MPC) is a powerful technique for solving dynamic control tasks. In this paper, we show that there exists a close connection between MPC and online learning, an abstract theoretical framework for analyzing online decision making in the optimization literature. This new perspective provides a foundation for leveraging powerful online learning algorithms to design MPC algorithms. Specifically, we propose a new algorithm based on dynamic mirror descent (DMD), an online learning algorithm that is designed for non-stationary setups. Our algorithm, Dynamic Mirror Descent Model Predictive Control (DMD-MPC), represents a general family of MPC algorithms that includes many existing techniques as special instances. DMD-MPC also provides a fresh perspective on previous heuristics used in MPC and suggests a principled way to design new MPC algorithms. In the experimental section of this paper, we demonstrate the flexibility of DMD-MPC, presenting a set of new MPC algorithms on a simple simulated cartpole and a simulated and real-world aggressive driving task.
One Line Summary - An abstract theoretical framework which connects Model Predictive Control to Online Learning, providing a foundation for formulating a new family of Model Predictive Control Algorithms and also providing a principled way to design new MPC algorithms.
Best Paper Award
A Magnetically-Actuated Untethered Jellyfish-Inspired Soft Milliswimmer
Ziyu Ren, Tianlu Wang, Wenqi Hu, Metin Sitti
Max Planck Institute for Intelligent Systems
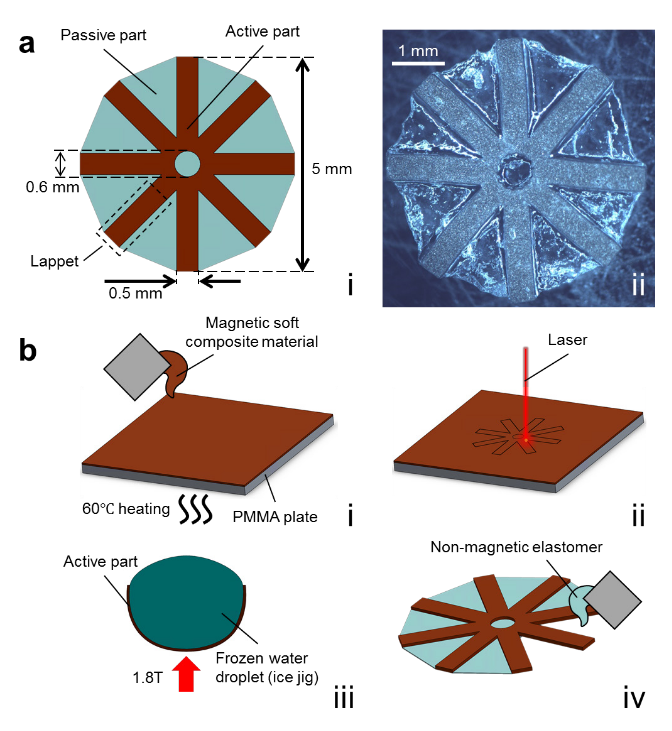
Abstract
Untethered small-scale soft robots can potentially be used in healthcare and biomedical applications. They can access small spaces and reshape their bodies in a programmable manner to adapt to unstructured environments and have diverse dynamic behaviors. However, the functionalities of current miniature soft robots are limited, restricting their applications in medical procedures. Taking the advantage of the shape-programmable ability of magnetic soft composite materials, here we propose an untethered soft millirobot (jellyfishbot) that can swim like a jellyfish by time- and trajectory-asymmetric up and down beating of its lappets. Its swimming speed and direction can be controlled by tuning the magnitude, frequency, and direction of the external oscillating magnetic field. We demonstrate that such jellyfishbot can perform several tasks that could be useful towards medical applications, such as delivering drugs, clogging a narrow tube or vessel, and patching a target area under ultrasound imaging-based guiding. The millirobot presented in this paper could be used inside organs filled with fluids completely, such as a bladder or inflated stomach.
One Line Summary - By leveraging the shape-programmable ability of magnetic soft composite materials, a millimeter-scale untethered robot is proposed for medical applications which swims like a jellyfish, its swimming direction and speed can be controlled by tuning the magnitude, frequency, and direction of the external oscillating magnetic field.
Some interesting papers
There were quite a few works on traditional robotics fields like SLAM, control theory which did not incorporate any learning based methods. I will mention some works on microrobotics and soft robotics.
Microrobotics
Microrobotics is the field of robotics dealing with miniature sized robots constrained by power, communication bandwidth and compute. Microrobots have the potential to be used in large swarms in a variety of situations, for example, in rescue operations or in drug delivery.
Motion Planning, Design Optimization and Fabrication of Ferromagnetic Swimmers
Jaskaran Grover, Daniel Vedova, Nalini Jain, Matthew Travers and Howie Choset
Carnegie Mellon University

Abstract
Small-scale robots have the potential to impact many areas of medicine and manufacturing including targeted drug delivery, telemetry and micromanipulation. This paper develops an algorithmic framework for regulating external magnetic fields to induce motion in millimeter-scale robots in a viscous liquid, to simulate the physics of swimming at the micrometer scale. Our approach for planning motions for these swimmers is based on tools from geometric mechanics that provide a novel means to design periodic changes in the physical shape of a robot that propels it in a desired direction. Using these tools, we are able to derive new motion primitives for generating locomotion in these swimmers. We use these primitives for optimizing swimming efficiency as a function of its internal magnetization and describe a principled approach to encode the best magnetization distributions in the swimmers. We validate this procedure experimentally and conclude by implementing these newly computed motion primitives on several magnetic swimmer prototypes that include two-link and three-link swimmers.
One Line Summary - Algorithmic framework for deriving motion primitives for generating locomotion in viscous liquids for millimeter scale ferromagnetic robots.
Soft Robotics
The field of Soft Robotics focuses on creating robots made out of materials which are not stiff and resemble those found in natural organisms.
Trajectory optimization for cable-driven soft robot locomotion
James M. Bern, Pol Banzet, Roi Poranne, Stelian Coros
ETH Zurich, University of Haifa
Abstract
Compliance is a defining characteristic of biological systems. Understanding how to exploit soft materials as effectively as living creatures do is consequently a fundamental challenge that is key to recreating the complex array of motor skills displayed in nature. As an important step towards this grand challenge, we propose a model-based trajectory optimization method for dynamic, cable-driven soft robot locomotion. To derive this trajectory optimization formulation, we begin by modeling soft robots using the Finite Element Method. Through a numerically robust implicit time integration scheme, forward dynamics simulations are used to predict the motion of the robot over arbitrarily long time horizons. Leveraging sensitivity analysis, we show how to efficiently compute analytic derivatives that encode the way in which entire motion trajectories change with respect to parameters that control cable contractions. This information is then used in a forward shooting method to automatically generate optimal locomotion trajectories starting from high-level goals such as the target walking speed or direction. We demonstrate the efficacy of our method by generating and analyzing locomotion gaits for multiple soft robots. Our results include both simulation and fabricated prototypes.
One Line Summary - Approach for trajectory optimization of a cable-driven soft robot by analytically computing how motion trajectories change with respect to parameters that control cable contractions.
More on Soft Robotics
Professor Koichi Suzumori’s informative, comprehensive and engaging Keynote on the past, present and future of Soft Robotics at RSS is a good place to start knowing more about Soft Robotics.
I will discuss my opinions on the significance of soft robotics with the help of a Japanese word “E-kagen”, which has two contrasting meanings. On the positive side, it could mean suitable, adaptable, and flexible; on the negative side, loose, imprecise, and arbitrary. It is very interesting that these two opposite meanings correspond to the good and poor aspects of soft robots.
-Koichi Suzumori
Koichi Suzumori’s Lab page (in Japanese) - Here
Conclusion
Echoing most of the attendees’ views, RSS was very well organized and all the events were conducted smoothly. The lack of overwhelming industry presence and the single track format made it easier to absorb the research being presented. Personally, the quality of the workshops was quite good and the poster sessions for the main conference helped in understanding specific works in more depth. One thing the RSS Committee could work on would be to be more inclusive with respect to countries with accepted papers (USA coming first with 66% of accepted papers UK 2nd with 7% and Switzerland 3rd with 7%). Ending on a tangential note, Germany, during the time of the conference was unusually hot. I hope that research in robotics could indirectly aid in tackling global warming and climate change.
Aseem Saxena is an AI Engineer affiliated with Panasonic Singapore. These opinions are solely his.
Special thanks to Andrey Kurenkov for his insight and comments.
Special thanks to Hugh Zhang for his guidance and support.
Attribution for cover picture - Here
If you enjoyed this piece and want more, Subscribe to the Gradient and follow us on Twitter!




{kind=link}
{kind=link}
{kind=link}
{kind=link}