
Background
Much recent work on large language models (LLMs) has explored the phenomenon of in-context learning (ICL). In this paradigm, an LLM learns to solve a new task at inference time (without any change to its weights) by being fed a prompt with examples of that task. For example, a prompt might give an LLM examples of translations, word corrections, or arithmetic, then ask it to translate a new sentence, correct a new word, or solve a new arithmetic problem:

In-context learning has an important relationship with prompting. If you ask ChatGPT to categorize different pieces of writing by theme, you might first give it example pieces with their correct categorizations. This fundamentally achieves the same thing, but is presented in a more “fluent” format. Recent works have explored how we can manipulate prompts to allow LLMs to perform certain tasks more easily, such as "Teaching Algorithmic Reasoning via In-Context Learning" by Zhou et al.
The GPT-4 technical report includes examples of questions, answers, and answer explanations when asking the model to answer new questions. The (clipped) example below comes from Section A.8, and gives the model a few example questions, answers, and explanations for the multiple choice section of an AP Art History Exam. At the end, the prompt provides just a question and asks the model to provide its (multiple choice) answer and an explanation.

The brunt of why ICL has been so interesting since it was introduced in the original GPT-3 paper is that, without any further fine-tuning, a pre-trained model is able to learn to do something entirely new by merely being shown a few input-output examples. As this Stanford blog notes, ICL is competitive on many NLP benchmarks when compared with models trained on much more labeled data.
This piece reviews literature that has attempted to understand ICL, and is supplemented by two paper summaries and author Q&As with researchers who have published on the topic.
What’s happening in in-context learning? The Literature
ICL was defined in “Language Models are Few-Shot Learners” by Brown et al., the paper that introduced GPT-3:
During unsupervised pre-training, a language model develops a broad set of skills and pattern recognition abilities. It then uses these abilities at inference time to rapidly adapt to or recognize the desired task. We use the term “in-context learning” to describe the inner loop of this process, which occurs within the forward-pass upon each sequence.
However, the mechanisms underlying ICL–an understanding of why LLMs are able to rapidly adapt to new tasks “without further training”–remain the subject of contending explanations. These attempts at explanation are the subject of this section.
Early Analyses
In-context learning was first seriously contended with in Brown et al., which both observed GPT-3’s capability for ICL and observed that larger models made “increasingly efficient use of in-context information,” hypothesizing that further scaling would result in additional gains for ICL abilities. While the ICL abilities GPT-3 displayed were impressive, it is worth noting that GPT-3 showed no clear ICL on the Winograd dataset and mixed results from ICL on commonsense reasoning tasks.
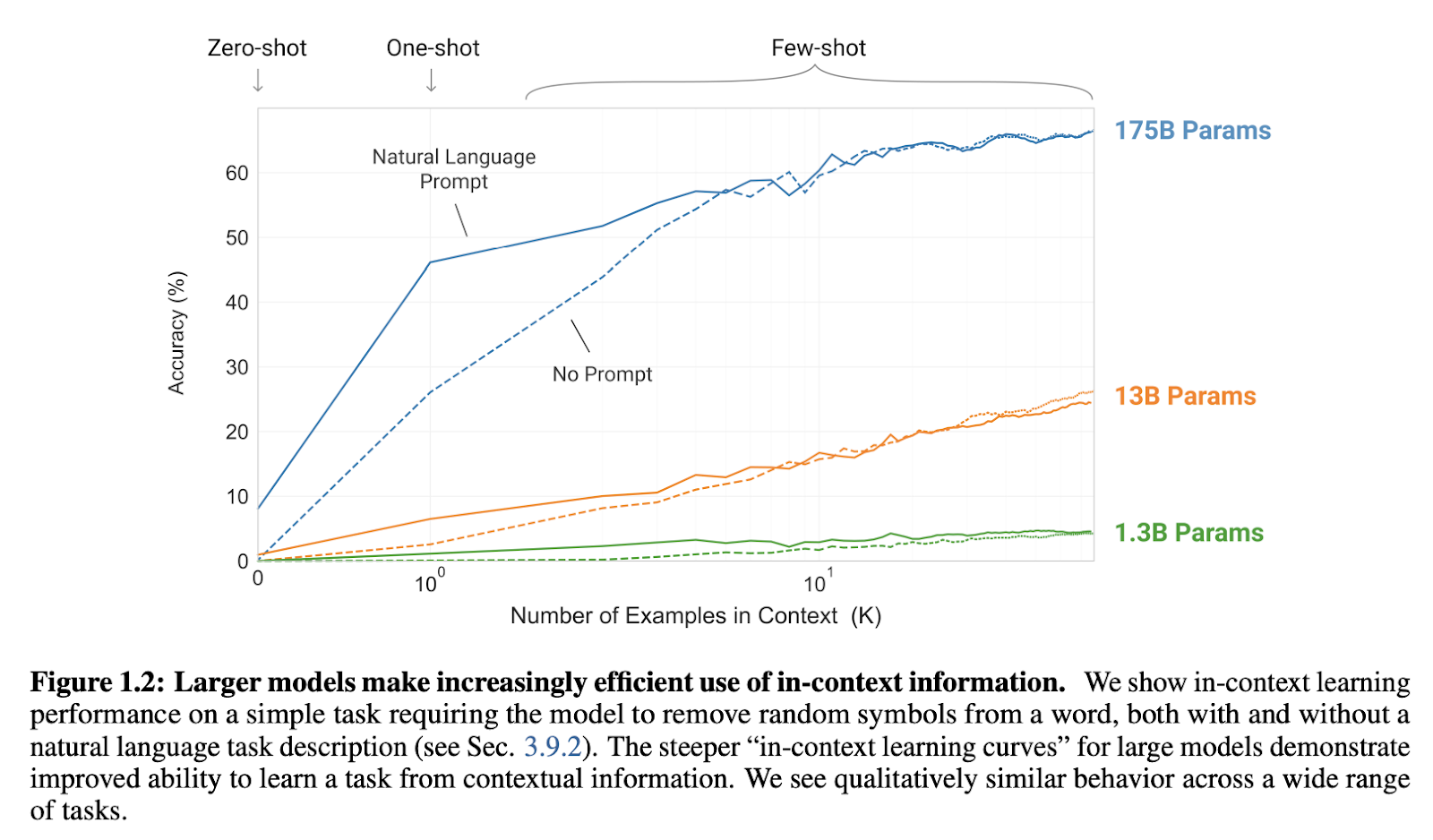
One earlier work, “An Explanation of In-context Learning as Implicit Bayesian Inference” by Xie et al., attempted to develop a mathematical framework for understanding how ICL emerges during pre-training. At a high level, the authors’ framework understands ICL as “locating” latent concepts the LM has acquired from its training data–all components of the prompt (format, inputs, outputs, and the input-output mapping) may be used to locate a concept. In more detail, the LM might infer that the task demonstrated by the prompt’s training examples is sentiment classification (the “concept” can be more detailed than this, e.g. sentiment classification of financial news), then apply that mapping to the test input. The authors give more detail on their approach:
In this paper, we study how in-context learning can emerge when pretraining documents have long-range coherence. Here, the LM must infer a latent document-level concept to generate coherent next tokens during pretraining. At test time, in-context learning occurs when the LM also infers a shared latent concept between examples in a prompt. We prove when this occurs despite a distribution mismatch between prompts and pretraining data in a setting where the pretraining distribution is a mixture of HMMs.
To study the phenomenon, the authors introduce a simple pretraining distribution where ICL emerges:
To generate a document, we first draw a latent concept $\theta$, which parameterizes the transitions of a Hidden Markov Model (HMM), then sample a sequence of tokens from this HMM… During pretraining, the LM must infer the latent concept across multiple sentences to generate coherent continuations… in-context learning occurs when the LM also infers a shared prompt concept across examples to make a prediction.
The authors then argue that, when the LM fits its pretraining distribution p exactly, ICL characterizes the conditional distribution of completions given prompts p(output|prompt) under the pretraining distribution; the prompt is generated from another distribution (since the prompt is not drawn directly from the training data). This conditional posterior predictive distribution marginalizes out latent concepts
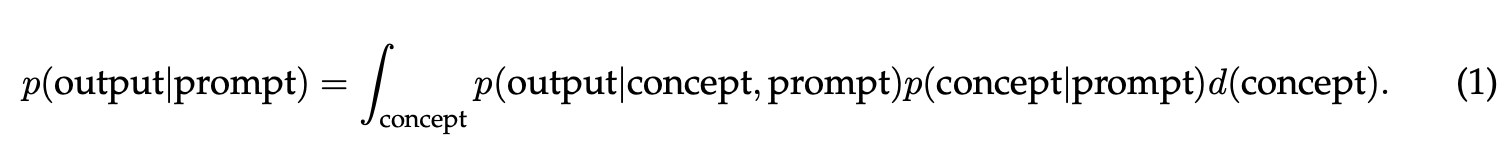
If p(concept|prompt) concentrates on the prompt concept with more examples then the LM learns via marginalization by “selecting” the prompt concept–this equates to performing Bayesian inference.
In Section 2, the authors characterize their theoretical setting–the pretraining distribution is a mixture of HMMs (MoHMM): it involves a latent concept $\theta$ from a family of concepts, which defines a distribution over observed tokens from a vocabulary. They generate a document by sampling a concept from a prior $p(\theta)$ and sample the document given the concept–the probability of the document (a length $T$ sequence) given the concept is defined by a HMM, and $\theta$ determines the transition probability matrix of the HMM hidden states. Their in-context predictor, a Bayesian predictor, outputs the most likely prediction over the pretraining distribution conditioned on the prompt from the prompt distribution.
Gabriel Poesia, though he finds the take on ICL convincing, noted that the paper’s argument might miss a link between the author’s Bayesian predictor and Transformers trained via maximum likelihood: that a Bayesian predictor would perform ICL and achieve optimal 0-1 loss does not imply any model achieving optimal 0-1 loss behaves equivalently to the Bayesian predictor.
Ferenc Huszár further notes that the authors’ analysis makes very strong assumptions about how the ICL task embedded in the sequence is related to the MoHMM distribution, and comments that the in-context task under study is more like a few-shot sequence completion task than a classification task. I think this is not entirely damning for the paper’s insights, and Bayesian inference may yet explain some forms of extrapolation.
A second work named “Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?” by Min et al., the subject of one of this article’s Q&As, analyzed which aspects of a prompt affect downstream task performance in in-context learners. The authors identify four aspects of the demonstrations (considered as input-output pairs $(x_1,y_1), … (x_k,y_k)$) that could provide learning signal:
- The input-label mapping
- The distribution of the input text
- The label space
- The format
In particular, the authors find that ground truth demonstrations are not required to achieve improved performance on a range of classification and multi-choice tasks–demonstrations with random labels achieve similar improvement to demonstrations with gold labels, and both outperform a zero-shot baseline that asks a LM to perform these tasks with no demonstrations. The authors also find that conditioning in the label space significantly contributes to performance gains when using demonstrations. The format also turns out to be very important to improvements from demonstrations: removing the format, or providing demonstrations with labels only, performs close to or worse than no demonstrations.
In summary, the three things that matter for in-context demonstrations are the input distribution (the underlying distribution inputs in ICL examples come from), the output space (the set of outputs—classes or answer choices—in the task), and the format of the demonstration. A Stanford AI Lab blog post connects the empirical findings in Min et al. to the hypothesis presented in Xie et al.: since LMs do not rely on the input-output correspondence in a prompt, they may already have been exposed to notions of this correspondence during pretraining that ICL then leverages. The other components of the prompt may be seen as providing evidence that allow the model to locate concepts (defined by Xie as latent variables that contain document-level statistics) it has already learned.
Induction Heads and Gradient Descent
When studying transformers under the lens of mechanistic interpretability, researchers at Anthropic studied a circuit they dubbed an induction head. Studying simplified, attention-only transformers, the researchers found that two layer models use attention head composition to create these induction heads, which perform in-context learning.
In simple terms, induction heads search over their context for previous examples of the token that a model is currently processing. If they find the current token in the context, they look at the following token and copy it–this allows them to repeat previous sequences of tokens in order to form new completions. Essentially, the idea is similar to copy-pasting from previous outputs of the model. For instance, continuing “Harry” with “Potter” may be done by looking at a previous output of “Harry Potter”.
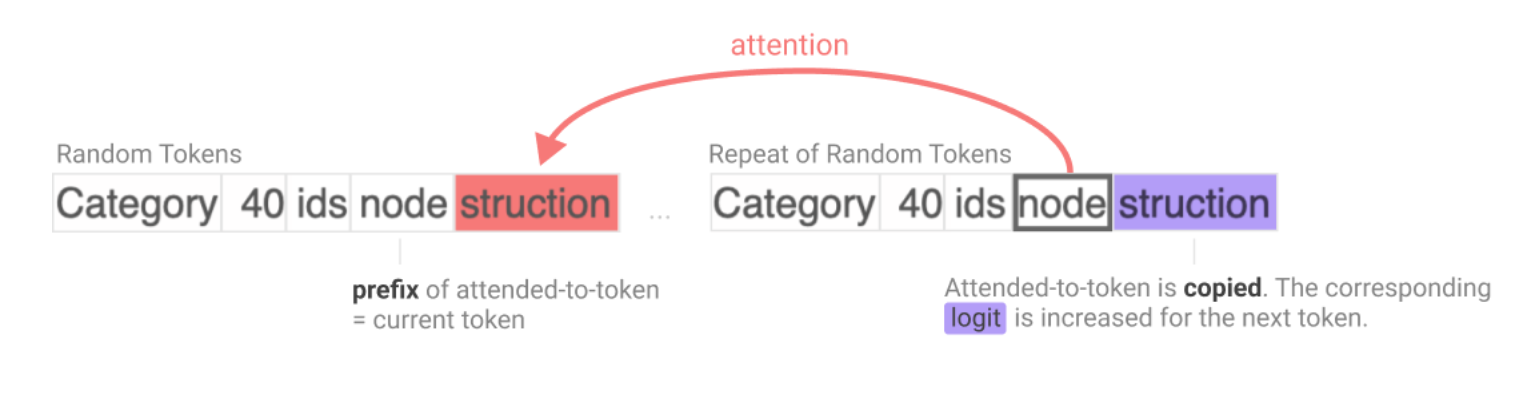
There is much more detail about induction heads and a full exegesis would likely also require some detail from the lengthy Mathematical Framework for Transformer Circuits, which introduces Anthropic’s mechanistic framework for understanding transformer models. I’ll refer interested readers to Neel Nanda’s explainer videos on the Mathematical Framework and Induction Heads papers and this lecture by Chris Olah on Induction Heads.
The upshot, as far as we are concerned, is that induction heads appear in transformer models just as transformers improve in their ability to do ICL. Since researchers can fully reverse engineer how these components of transformers work, they present a promising avenue for developing a fuller understanding of how and why ICL works.
More recent work contextualizes (no pun intended) ICL in the light of gradient descent. Naturally, the word learning would suggest that ICL implements some sort of optimization process.
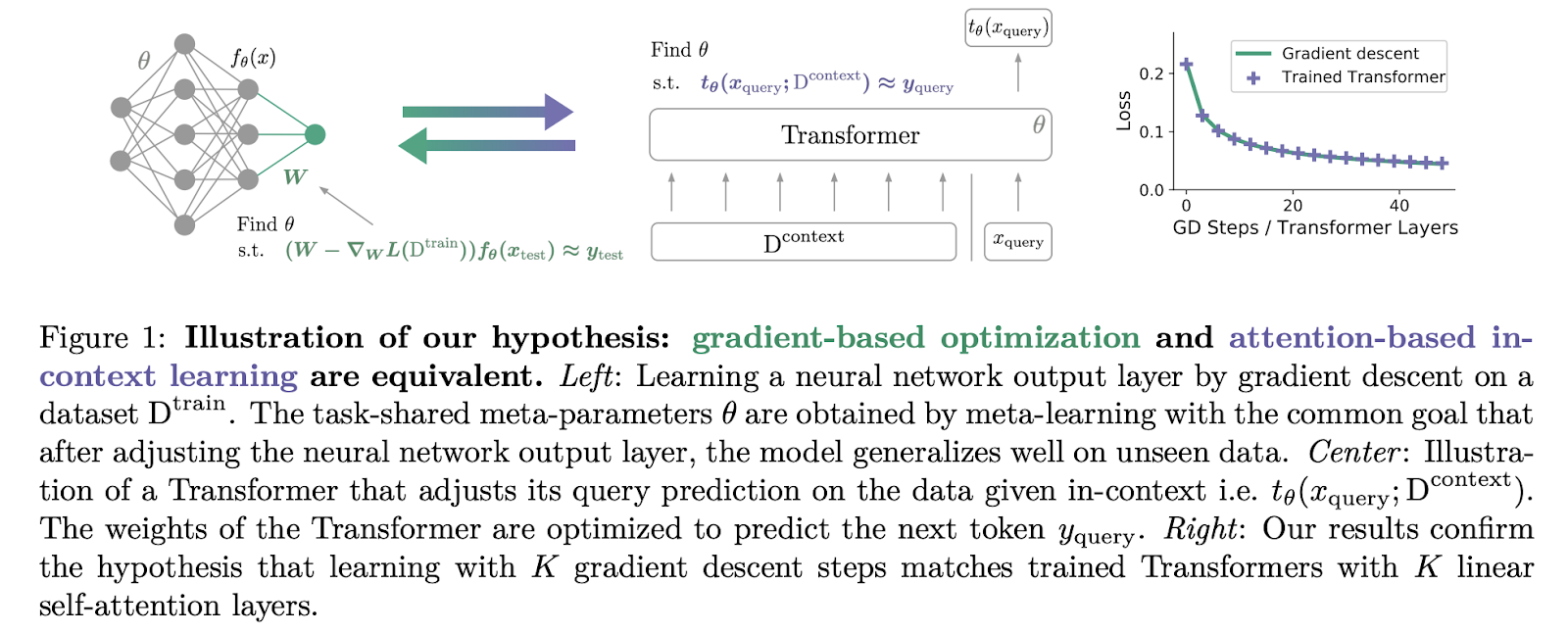
In “What Learning Algorithm is In-Context Learning,” Akyürek et al., using linear regression as a toy problem, provide evidence for the hypothesis that transformer-based in-context learners indeed implement standard learning algorithms implicitly.
“Transformers learn in-context by gradient descent” makes precisely the claim suggested by its title. The authors hypothesize that a transformer forward pass implements ICL “by gradient-based optimization of an implicit auto-regressive inner loss constructed from its in-context data.” As we discussed in a recent Gradient Update, this work shows that transformer architectures of modest size can technically implement gradient descent.
Learnability and ICL in Larger Language Models
Two recent papers from March explore a few interesting properties of in-context learning, which shed some light and raise questions on the “learning” aspect of ICL.
First, “The Learnability of In-Context Learning” presents a first-of-its-kind PAC-based framework for in-context learnability. With a mild assumption on the number of pretraining examples for a model and the number of downstream task examples, the authors claim that when the pretraining distribution is a mixture of latent tasks, these tasks can be efficiently learned via ICL. The authors justify a number of interesting results in this paper, but the key takeaway is that this work further primes the intuition that ICL locates a concept that a language model has already learned. The idea of a “mixture of latent tasks” might also remind one of MetaICL, which explored downstream performance after tuning a pretrained model to do ICL on a large set of training tasks.
“Large Language Models Do In-Context Learning Differently” further studies which facets of ICL affect performance, shedding additional light on whether “learning” actually happens in ICL. “Rethinking the Role of Demonstrations” showed that presenting a model with random mappings instead of correct input-output values did not substantially affect performance, indicating that language models primarily rely on semantic prior knowledge while following the format of in-context examples. Meanwhile, the works on ICL and gradient descent show that transformers in simple settings learn the input-label mappings from in-context examples.
In this paper, Wei et al. study how semantic priors and input-label mappings interact in three settings:
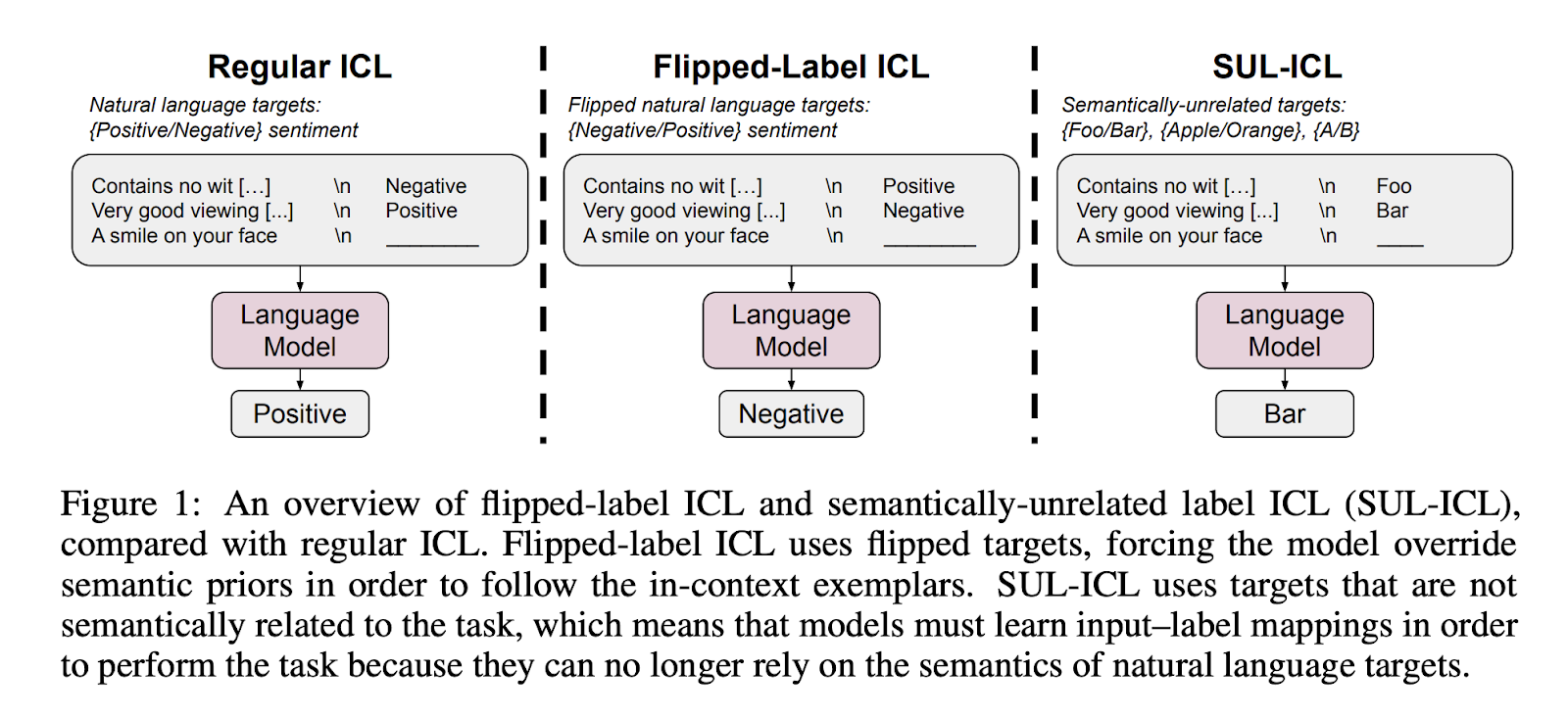
- Regular ICL: both semantic priors and input-label mappings can allow a model to perform ICL successfully.
- Flipped-label ICL: all labels in examples are flipped, producing a disagreement between semantic prior knowledge and input-label examples. Performance above 50% on an evaluation set with ground-truth labels indicates a model failed to override semantic priors. Performance below 50% performance indicates that a model successfully learned from the (incorrect) input-label mappings, overriding its priors.
- Semantically-unrelated label ICL (SUL-ICL): the labels are semantically unrelated to the task (e.g., “foo/bar” are used as labels for a sentiment classification task instead of “positive/negative”). In this setting, a model can only perform ICL by using input-label mappings.
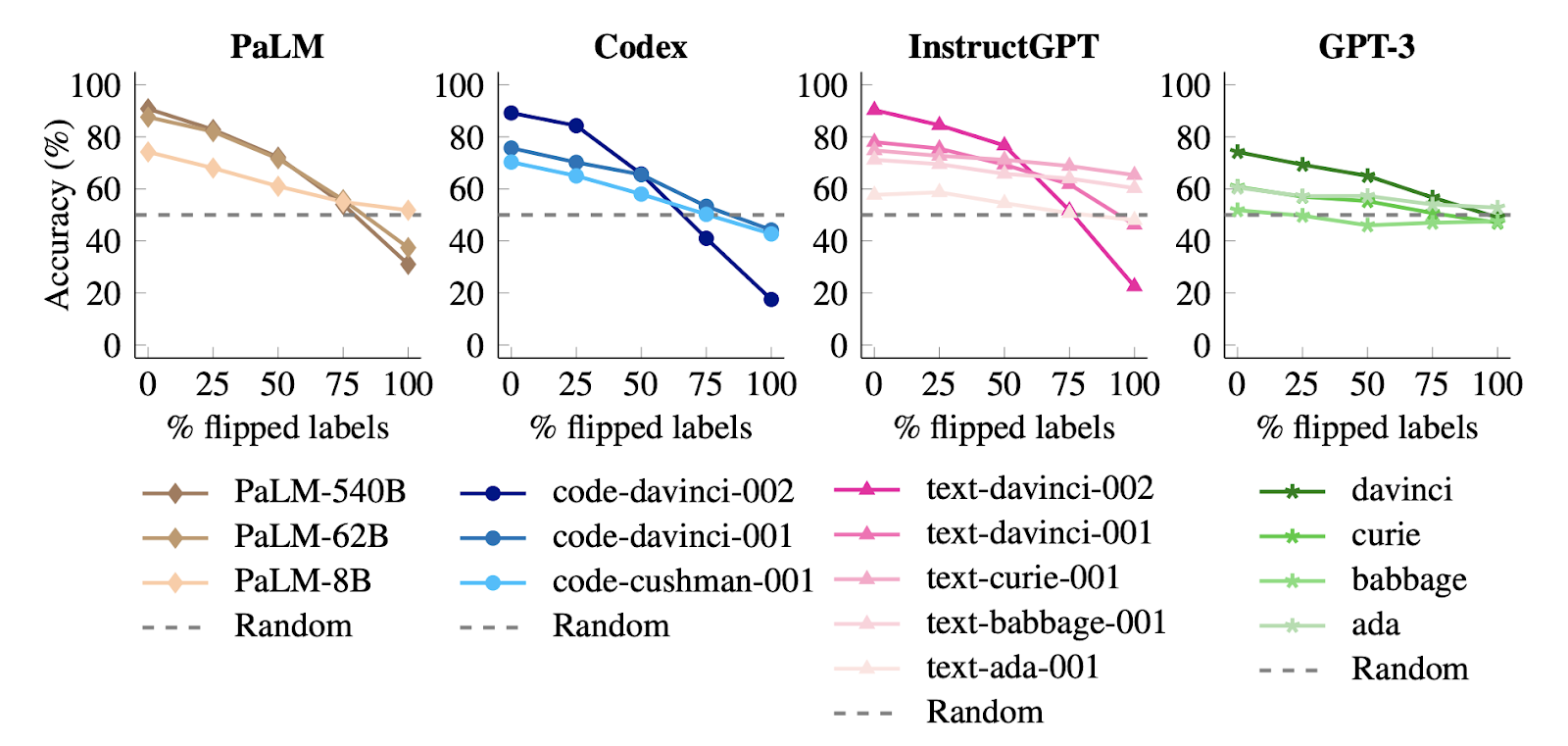
The key takeaway from this paper is that LLMs demonstrate an emergent ability to override their semantic priors and learn from input-label mappings. In other words, a sufficiently large model asked to in-context learn on examples with flipped labels will then show degraded (below 50%) performance on an evaluation set whose examples have correct labels. Since small models do not demonstrate this ability and instead rely on semantic priors (as in “Rethinking the Role of Demonstrations”), this ability appears to emerge with scale.
In the SUL-ICL setting, the authors demonstrate a similar shift in capabilities from small to large models. The below figure shows performance differences between regular ICL and SUL-ICL, where models are asked to in-context learn using examples whose labels are semantically unrelated to the task.
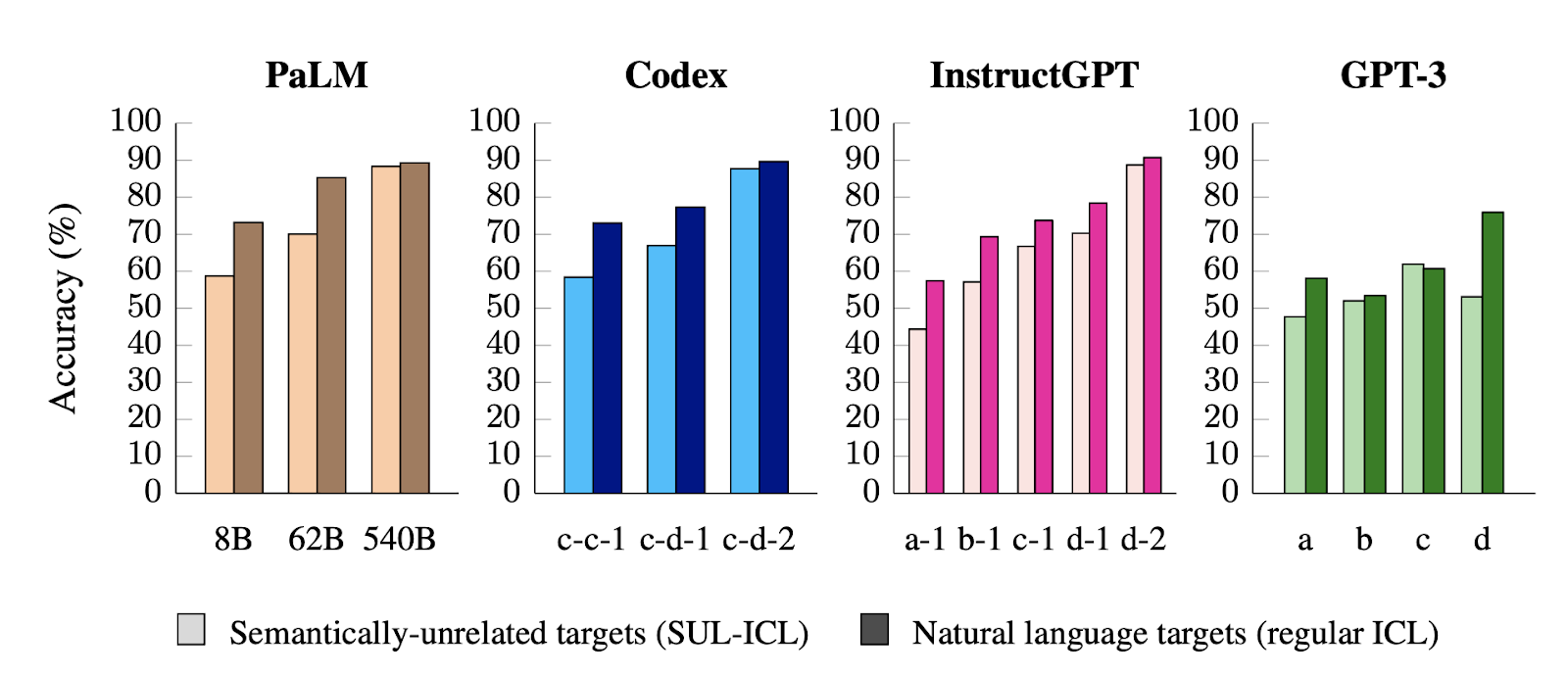
While increasing model size improves performance in both regular ICL and SUL-ICL, the drop in performance from regular ICL to SUL-ICL motivates an interesting observation. Small models experience a greater performance drop between regular ICL and SUL-ICL, indicating that these models’ semantic priors, which rely on the actual names of labels, prevent them from learning from examples with semantically-unrelated labels. Large models, on the other hand, experience a much smaller performance drop; this indicates that they can still learn input-label mappings in-context without semantic priors
What’s Next for In-Context Learning?
In a question from our Q&A, Sewon Min raised an interesting point about how she thinks about in-context learning: she states:
if we define “learning” as obtaining a new intrinsic ability it has not had previously, then I think learning has to be with gradient updates. I believe whatever that is happening at test time is a consequence of “learning” that happened at pre-training time. That is related to our claim in the paper that “in-context learning is mainly for better location (activation) of the intrinsic abilities LMs have learned during training”, which has been claimed by other papers as well (Xie et al. 2021, Reynolds & McDonell 2021).
The idea that in-context learning merely locates some latent ability or piece of knowledge a language model has already imbibed from its training data feels intuitive and makes the phenomenon a bit more plausible. A few months ago, I wondered whether the recent works connecting ICL to gradient descent problematized this view—if there is a connection between ICL and gradient descent, perhaps language models do learn something new when presented with in-context examples?
The recent finding that larger language models can override their semantic priors and, perhaps, “learn” something seems to point to the conclusion that the answer to “Do language models actually learn something in context, as opposed to merely locating concepts learned from pretraining?” is not yes or no. Smaller models do not seem to learn from in-context examples, and larger ones do.
However, Akyürek et al. make another observation that might encourage us to read these results as degrees of learning. Section 4.3 observes that ICL exhibits algorithmic phase transitions as model depth increases: one-layer transformers’ ICL behavior approximates a single step of gradient descent, while wider and deeper transformers match ordinary least squares or ridge regression solutions. Akyürek et al. did not study transformers at the scale of Wei et al, but it is possible to imagine that if small models implement simple learning algorithms in-context, larger models might implement more sophisticated functions during ICL.
To conclude, a number of works seem to problematize the notion that ICL does not involve learning and merely locates concepts existing in a pre-trained model. Wei et al. indicates that there is not a binary answer here: large models seem to “learn” more from in-context examples than small models. But the results connecting ICL to gradient descent suggest that there is some reason to believe learning might occur when small models perform ICL as well.
I won’t make a strong claim here—essentially nothing is “out of distribution” for a sufficiently large model, and the capacity these models have makes it difficult to form a strong intuition around what they are “doing” with the information they have gained via pretraining. If everything is truly in-distribution, then what is left but to recombine? For now, I’ll avoid taking a stance on whether “learning” is actually happening in ICL—I do think there are interesting arguments on each side. I suspect our understanding of ICL will continue to evolve, and I hope we better understand when and how “learning” occurs in ICL.




{kind=link}
{kind=link}
{kind=link}
{kind=link}