
Generalization is a subject undergoing intense discussion and study in NLP.
News media has recently been reporting that machines are performing as well as and even outperforming humans at reading a document and answering questions about it, at determining if a given statement semantically entails another given statement, and at translation. It may seem reasonable to conclude that if machines can do all of these tasks, then they must possess true language understanding and reasoning capabilities.
However, this is not at all true. Numerous recent studies show that state-of-the-art systems are, in fact, both brittle and spurious.
State-of-the-art NLP models are brittle
They fail when text is modified, even though its meaning is preserved:
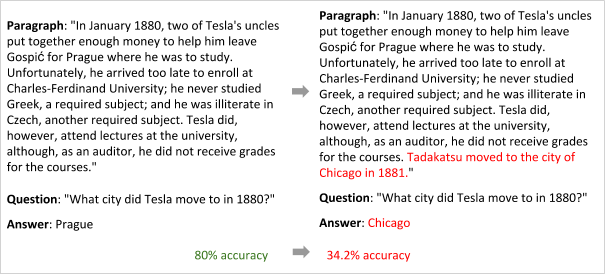
- Jia and Liang[1] broke the reading comprehension[2] BiDAF[3] model.
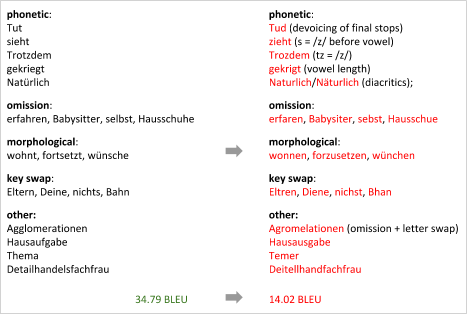
- Belinkov and Bisk[4] broke the character-based neural machine translation model.
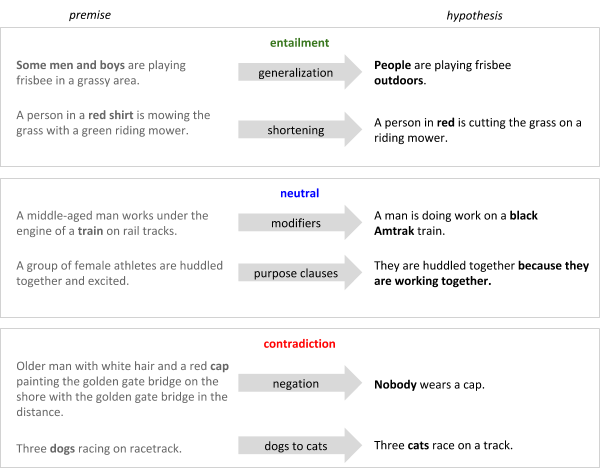
- Iyyer and collaborators[5] broke the tree-structured bidirectional LSTM[6] sentiment classification[7] model.

State-of-the-art NLP models are spurious
They often memorize artifacts and biases instead of truly learning:
- Gururangan and collaborators[8] proposed a baseline which correctly classifies over 50% of natural language inference[9] examples in benchmark datasets without ever observing the premise.
- Moosavi and Strube[10] showed that the deep-coref[11] model for coreference resolution[12] always links proper or common nouns with the head country to a country that is seen in the training data. Consequently, the model performs poorly on a text about countries not mentioned in the training data. Meanwhile, Levy and collaborators[13] studied models for recognizing lexical inference relations between two words, such as hypernymy[14]. They showed that instead of learning characteristics of the relation between the words, these models learn an independent property of only a single word in the pair: whether that word is a "prototypical hypernym" such as animal.

- Agrawal and collaborators[15] showed that a CNN+LSTM[16] visual question answering[17] model often converges on a predicted answer after "listening" to just half the question. That is, the model is heavily driven by superficial correlations in the training data and lacks compositionality (the ability to answer questions about unseen compositions of seen concepts).

A workshop to improve state-of-the-art NLP models
So despite good performance on benchmark datasets, modern NLP techniques are nowhere near the skill of humans at language understanding and reasoning when making sense of novel natural language inputs. These insights prompted Yonatan Bisk[18], Omer Levy[19] and Mark Yatskar[20] to organize a NAACL workshop to discuss generalization, the central challenge in machine learning. The workshop was devoted to two questions:
-
How can we adequately measure how well our systems perform on new, previously unseen inputs? Or in other words, how do we adequately measure how well our systems generalize?
-
How should we modify our models so that they generalize better?
These are difficult questions, and a one-day workshop is clearly not enough to resolve them. However, many approaches and ideas were outlined at this workshop by some of NLP’s brightest minds, and they are worth paying attention to. In particular, the discussions can be summarized around three main themes: using more inductive biases (but cleverly), working towards imbuing NLP models with common sense, and working with unseen distributions and unseen tasks.
Direction 1: More inductive biases (but cleverly)
It is an ongoing discussion whether inductive biases—the set of assumptions used to learn a mapping function from input to output—should be reduced or increased.
For instance, just last year there was a noteworthy debate between Yann LeCun and Christopher Manning on what innate priors we should build into deep learning architectures. Manning[21] argues that structural bias is necessary for learning from less data and high-order reasoning. In opposition, LeCun[22] describes structure as a "necessary evil" that forces us to make certain assumptions that might be limiting.
A convincing argument for LeCun’s position (reducing inductive biases) is the fact that modern models that using linguistic-oriented biases does not result in the best performance for many benchmark tasks. Still, the NLP community broadly supports Manning’s opinion; inducing linguistic structures in neural architectures was one of the notable trends from ACL 2017. Since such induced structures seem to not work as expected in practice, it may be concluded that a good line of work must be exploring new forms of integrating inductive biases, or in Manning’s words:
We should have more inductive biases. We are clueless about how to add inductive biases, so we do dataset augmentation [and] create pseudo-training data to encode those biases. Seems like a strange way to go about doing things.
This is a problem that Yejin Choi[23] has tackled in the context of Natural Language Generation (NLG)[24]. She showed an example of a review generated by a common language model—a gated RNN with the beam search decoder — trained to maximize the probability of the next token.
The natural language input:
All in all, I would highly recommend this hotel to anyone who wants to be in the heart of the action.
And the unnatural output, which was repetitive, contradictory, and bland:
All in all, I would highly recommend this hotel to anyone who wants to be in the heart of the action, and want to be in the heart of the action. If you want to be in the heart of the action, this is not the place for you. However, if you want to be in the middle of the action, this is the place to be.
In her opinion, current language models are generating unnatural language because they are:
-
Passive learners. Though they read input and generate output, unlike a human learner they do not reflect on what they generated according to appropriate linguistic criteria such as relevance, style, repetition and entailment. Or in other words, they do not "practice" writing.
-
Surface learners. They do not capture the higher-order relationships among facts, entities, events or activities, which for humans can be the key cue for language understanding. They do not have knowledge about our world.
Language models can "practice" writing if we encourage them to learn linguistic features such as relevance, style, repetition, and entailment in a data-driven fashion using particular loss functions[25]. This is superior to an approach reliant on the explicit use the output of Natural Language Understanding (NLU) tools[26], because NLU traditionally deals only with natural language and so fails to understand machine language that is potentially unnatural, such as the repetitive, contradictory, bland text in the example above. Because NLU does not understand machine language, it is pointless to apply NLU tools to a generated text to teach NLG to understand why is the generated text unnatural and act upon this understanding. In summary, instead of developing new neural architectures that introduce structural biases, we should improve the data-driven optimization ways of learning these biases.
NLG is not the only NLP task for which we seek a better optimization of the learner. In machine translation, one serious problem in our optimization is that we are training our machine-translation models with loss functions such as cross-entropy or expected sentence-level BLEU, which have been shown to be biased and insufficiently correlated with human judgments[27]. As long as we are training our models using such simplistic metrics, there will likely be a mismatch between predictions and human judgment of the text. Because of the complex objective, reinforcement learning seems to be a perfect choice for NLP, since it allows the model to learn a human-like supervision signal (“reward”) in a simulated environment through trial and error.
Wang and collaborators[28] proposed such a training approach for visual storytelling[29] (describing the content of an image or a video). First, they investigated already proposed training approaches which utilize reinforcement learning to train image captioning systems directly on non-differentiable metrics[30] such as METEOR, BLEU or CIDEr which are used at the test time. Wang and collaborators showed that if the METEOR score is used as the reward to reinforce the policy, the METEOR score is significantly improved but the other scores are severely harmed. They showcase an example with an average METEOR score as high as 40.2:
We had a great time to have a lot of the. They were to be a of the. They were to be in the. The and it were to be the. The, and it were to be the.
Conversely, when using some other metrics (BLEU or CIDEr) to evaluate the stories, the opposite happens: many relevant and coherent stories receive a very low score (nearly zero). The machine is gaming the metrics.
Thus, the authors propose a new training approach that aims at deriving a human-like reward from both human-annotated stories and sampled predictions. Still, deep reinforcement learning is brittle and has an even higher sample complexity than supervised deep learning. A real solution might be in human-in-the-loop machine learning algorithms that involve humans in the learning process.
Direction 2: Common sense
While "common sense" may be common among humans, it is hard to teach to machines. Why are tasks like making conversation, answering an email, or summarizing a document hard?
These are tasks lacking a 1-1 mapping between input and output, and require abstraction, cognition, reasoning, and most broadly knowledge about our world. In other words, it is not possible to solve these problems as long as pattern matching (the most of modern NLP) is not enhanced with some notion of human-like common sense, facts about the world that all humans are expected to know.
Choi illustrated this with a simple yet effective example of a news headline saying "Cheeseburger stabbing".
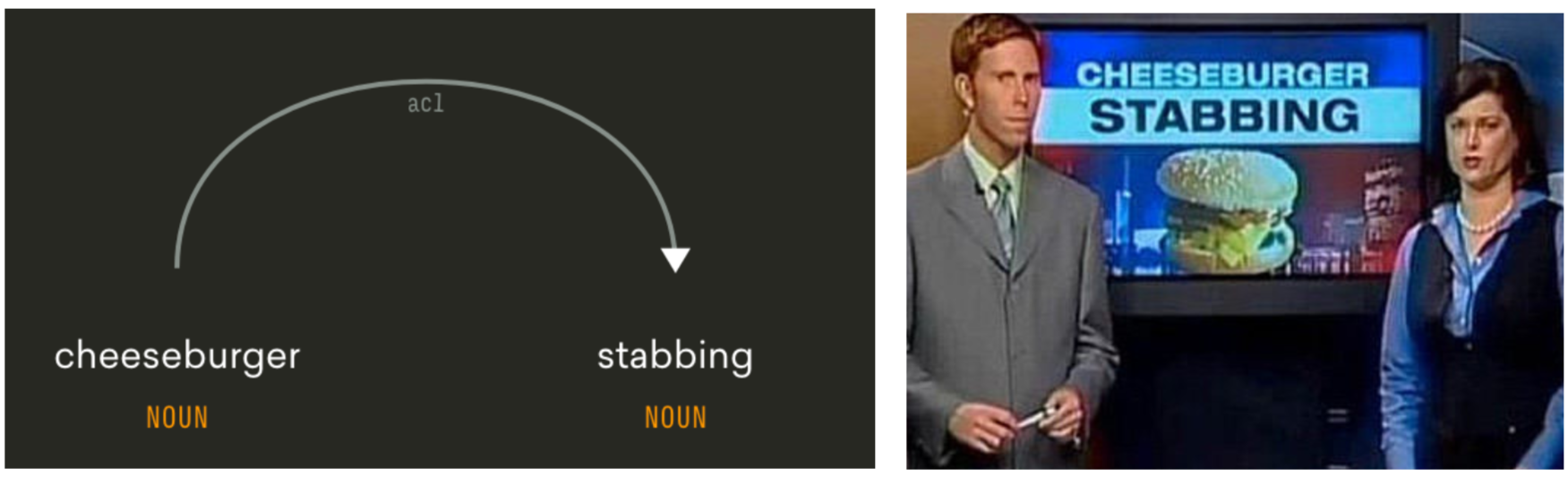
Knowing that the head of the acl relation "stabbing" is modified by the dependent noun “cheeseburger”, is not sufficient to understand what does “cheeseburger stabbing” really means. The figure taken from Choi’s presentation.
Plausible questions a machine might ask about this headline are:
Someone stabbed someone else over a cheeseburger?
Someone stabbed a cheeseburger?
A cheeseburger stabbed someone?
A cheeseburger stabbed another cheeseburger?
Machines could eliminate absurd questions you would never ask if they have social and physical common sense. Social common sense[31] could alert machines that the first option is plausible because stabbing someone is bad and thus newsworthy, whereas stabbing a cheeseburger is not. Physical common sense[32] indicates that the third and fourth options are impossible because a cheeseburger cannot be used to stab anything.
In addition to integrating common-sense knowledge, Choi suggests that "understanding by labeling"[33], which is focused on "what is said," should be changed to "understanding by simulation"[34]. This simulates the causal effects implied by text and focuses not only on “what is said” but also on “what is not said but implied”. Bosselut and colleagues[35] showcased an example to illustrate why anticipating the implicit causal effects of actions on entities in text is important:
Given instructions such as "add blueberries to the muffin mix, then bake for one half hour," an intelligent agent must be able to anticipate a number of entailed facts, e.g., the blueberries are now in the oven; their “temperature” will increase.
Mihaylov and Frank[36] also recognized that we have to move to understanding by simulation. Their cloze-style reading comprehension model[37], unlike many other more complex alternatives, handles cases where most of the information to infer answers from is given in a story, but additional common-sense knowledge is needed to predict the answer: horse is an animal, animals are used for riding and mount is related to animals.
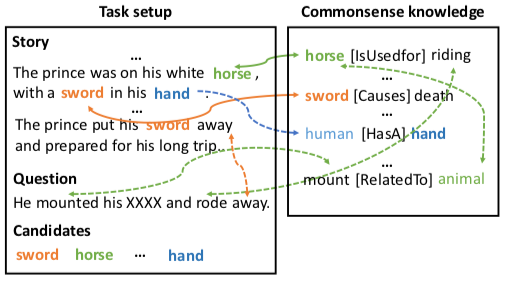
Alas, we must admit that modern NLP techniques work like "a mouth without a brain," and to change that, we have to provide them with common-sense knowledge and teach them to reason about what is not said but is implied.

Direction 3: Evaluate unseen distributions and unseen tasks
The standard methodology for solving a problem using supervised learning consists of the following steps:
- Decide how to label data.
- Label data manually.
- Split labeled data into a training, test and validation set. It is usually advised to ensure that train, dev and test sets have the same distribution if possible.
- Decide how to represent the input.
- Learn the mapping function from input to output.
- Evaluate proposed learning method using an appropriate measure on the test set.
Following this methodology, solving the puzzle below requires labeling data to train a model that identifies units, considers multiple representations and interpretations (pictures, text, layout, spelling, phonetics), and puts it all together. The model determines the “best” global interpretation and satisfies human interpretation of the puzzle.
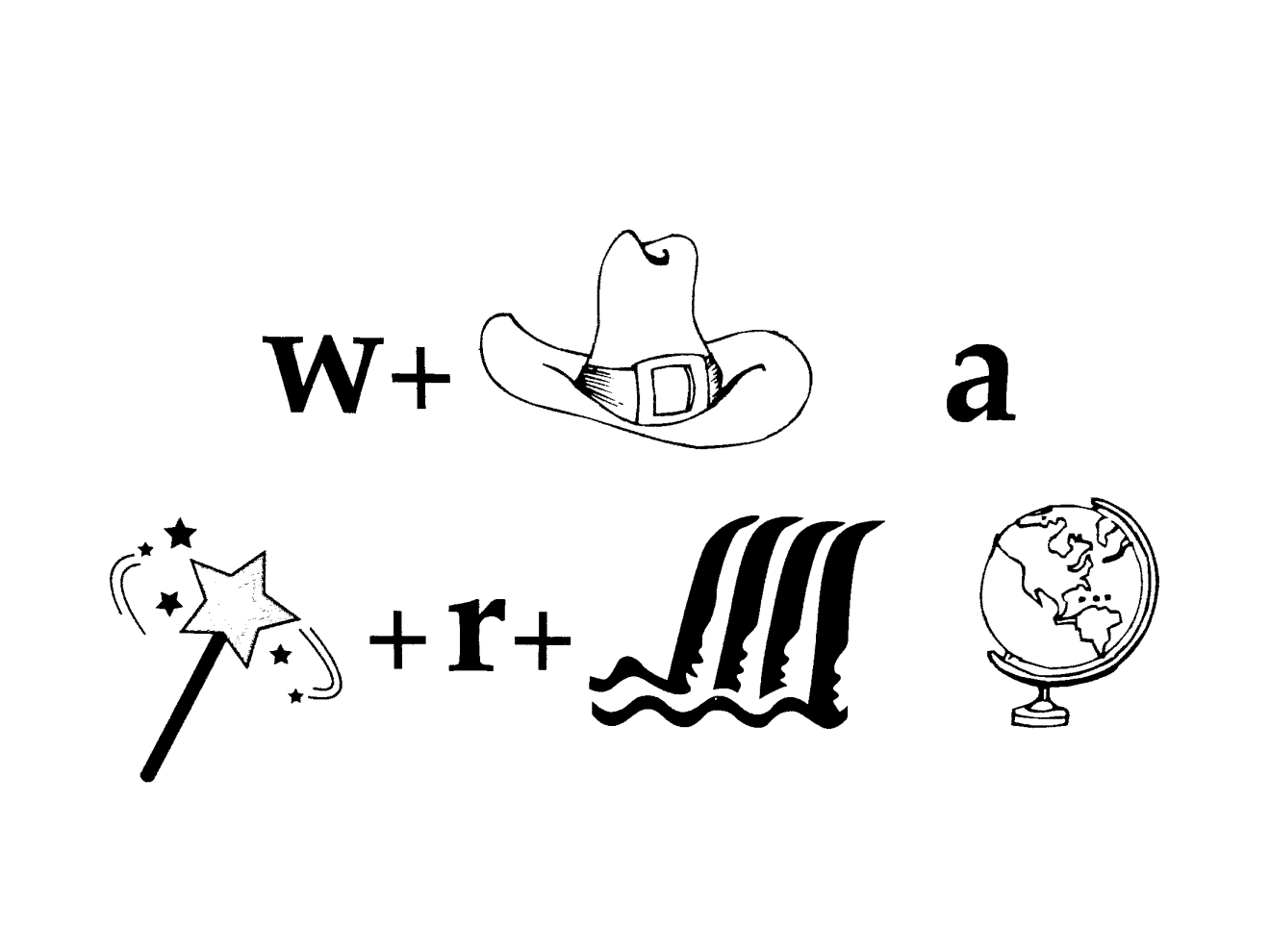
In the opinion of Dan Roth[38]:
- The standard methodology is not scalable. We will never have enough annotated data to train all the models for all the tasks we need. To solve the puzzle above, we need annotated training data to overcome at least five different components of the task, or an enormous amount of data to train an end-to-end model. Although some components such as identifying units might be solved using available resources such as ImageNet, this resource is still not sufficient to realize that word "world" is better than word “globe” in this context. Even if someone put a huge annotation effort, the data has to be constantly updated with new pop culture references every day.
Roth draws our attention to the fact that a huge amount of data exists independent of a given task and has hints that are often sufficient to infer supervision signals for a range of tasks. This is where the idea of incidental supervision comes into the play. In his own words[39],
Incidental signals refer to a collection of weak signals that exist in the data and the environment, independently of the tasks at hand. These signals are co-related to the target tasks, and can be exploited, along with appropriate algorithmic support, to provide sufficient supervision and facilitate learning. Consider, for example, the task of Named Entity (NE) transliteration – the process of transcribing a NE from a source language to some target language based on phonetic similarity between the entities (e.g., determine how to write Obama in Hebrew). The temporal signal is there, independently of the transliteration task at hand. It is co-related to the task at hand and, together with other signals and some inference, could be used to supervise it without the need for any significant annotation effort.
Percy Liang[40] argues that if train and test data distributions are similar, “any expressive model with enough data will do the job.” However, for extrapolation -- the scenario when train and test data distributions differ -- we must actually design a more “correct” model.
Extrapolating with the same task at train and test time is known as domain adaptation, which has received a lot of attention in recent years.
But incidental supervision, or extrapolating with a task at train time that differs from the task at test time, is less common. Li and collaborators[41] trained a model for text attribute transfer[42] with only the attribute label of a given sentence, instead of a parallel corpus that pairs sentences with different attributes and the same content. To put it another way, they trained a model that does text attribute transfer only after being trained as a classifier to predict the attribute of a given sentence. Similarly, Selsam and collaborators[43] trained a model that learns to solve SAT problems[44] only after being trained as a classifier to predict satisfiability. Notably, both models have a strong inductive bias. The former uses the assumption that attributes are usually manifested in localized discriminative phrases. The latter captures the inductive bias of survey propagation.
Percy challenged the community by asserting:
Every paper, together with evaluation on held-out test sets, should evaluate on a novel distribution or on a novel task because our goal is to solve tasks, not datasets.
We need to think like machine learning when using machine learning, at least when evaluating, because machine learning is like a tornado that sucks in everything and does not care about common sense, logical reasoning, linguistic phenomena or intuitive physics.

Workshop attendees wondered whether we want to construct datasets for stress testing — testing beyond normal operational capacity, often to a breaking point, in order to observe the true generalization power of our models.
It is reasonable to expect that a model has a chance to solve harder examples only after it solved easier cases. To know whether easier cases are solved, Liang suggested we might want to categorize examples by their difficulty. Devi Parikh[45] emphasized that only a subset of tasks or datasets are such that you can be certain that solving hard examples is possible if you have solved easier examples. The tasks not in this subset, like visual question answering, don't fit in this framework. It is not clear which image–question pairs a model should be able to solve to be able to solve other, possibly harder image–question pairs. Thus, it might be dangerous if we start defining "harder" examples as the ones that the model cannot answer.
Workshop attendees raised worries that stress test sets could slow down progress. What are good stress tests that will give us better insights into true generalization power and encourage researchers to build more generalizable systems, but will not cause funding to decline and researchers to be stressed with the low results? The workshop did not provide an answer to this question.
Takeaways
The NAACL Workshop on New Forms of Generalization in Deep Learning and Natural Language Processing was the start of a serious re-consideration of language understanding and reasoning capabilities of modern NLP techniques. This important discussion continued at ACL, the Annual Meeting of the Association for Computational Linguistics. Denis Newman-Griffis reported that ACL attendees repeatedly suggested that we need to start thinking about broader kinds of generalization and testing situations that do not mirror the training distribution, and Sebastian Ruder recorded that main themes of the NAACL workshop were also addressed during RepL4NLP, the popular ACL workshop on Representation Learning for NLP.
These events revealed that we are not completely clueless about how to modify our models such that they generalize better. But there is still plenty of room for new suggestions.
We should use more inductive biases, but we have to work out what are the most suitable ways to integrate them into neural architectures such that they really lead to expected improvements.
We have to enhance pattern-matching state-of-the-art models with some notion of human-like common sense that will enable them to capture the higher-order relationships among facts, entities, events or activities. But mining common sense is challenging, so we are in need of new, creative ways of extracting common sense.
Finally, we should deal with unseen distributions and unseen tasks, otherwise “any expressive model with enough data will do the job.” Obviously, training such models is harder and results will not immediately be impressive. As researchers we have to be bold with developing such models, and as reviewers we should not penalize work that tries to do so.
This discussion within the field of NLP reflects a larger trend within AI in general—reflection on the flaws and strengths of deep learning. Yuille and Liu wrote an opinion titled Deep Nets: What have they ever done for Vision? in the context of vision, and Gary Marcus[46] has long championed using approaches[47] beyond[48] deep[49] learning[50] for AI in general. It is a healthy sign that AI researchers are very much clear eyed about the limitations of deep learning, and working to address them.
Citation
For attribution in academic contexts or books, please cite this work as
Ana Marasović, "NLP’s generalization problem, and how researchers are tackling it", The Gradient, 2018.
BibTeX citation:
@article{MarasovicGradient2018NLP,
author = {Marasović, Ana}
title = {NLP’s generalization problem, and how researchers are tackling it},
journal = {The Gradient},
year = {2018},
howpublished = {\url{https://thegradient.pub/frontiers-of-generalization-in-natural-language-processing } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.
Robin Jia and Percy Liang. Adversarial Examples for Evaluating Reading Comprehension Systems. Proceedings of EMNLP (2017). ↩︎
Reading Comprehension (RC) is the ability to read text and then answer questions about it. The benchmark SQuAD dataset consists of human-generated RC questions about Wikipedia articles. Each question refers to one paragraph of an article, and the corresponding answer is guaranteed to be a span in that paragraph. SQuAD does not provide a list of answer choices for each question, thus systems must select the answer from all possible spans in the passage. Accuracy of RC systems is measured using the macro-averaged F1 score which measures the average overlap between the prediction and ground truth answer. The prediction and ground truth are treated as bags of tokens, and their F1 is computed. The maximum F1 over all of the ground truth answers for a given question is taken. Finally, the average over all of the questions is calculated. ↩︎
Minjoon Seo, Aniruddha Kembhavi, Ali Farhadi and Hannaneh Hajishirzi. Bidirectional Attention Flow for Machine Comprehension. Proceedings of ICLR (2017). ↩︎
Yonatan Belinkov and Yonatan Bisk. Synthetic and Natural Noise Both Break Neural Machine Translation. Proceedings of ICLR (2018). ↩︎
Mohit Iyyer, John Wieting, Kevin Gimpel and Luke Zettlemoyer. Adversarial Example Generation with Syntactically Controlled Paraphrase Networks. Proceedings of NAACL-HLT (2018). ↩︎
Kai Sheng Tai, Richard Socher and Christopher D. Manning. Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks. Proceedings of ACL (2015). ↩︎
Sentiment classification is a basic task in sentiment analysis that aims to classify whether the expressed opinion in a document, a sentence or an entity aspect is positive, negative, or neutral. ↩︎
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R. Bowman and Noah A. Smith. Annotation Artifacts in Natural Language Inference Data. Proceedings of NAACL-HLT (2018). ↩︎
Natural language inference is the classification task of determining whether a given statement (hypothesis) is true (entailment), false (contradiction), or undetermined (neutral) given another statement (premise). ↩︎
Nafise Sadat Moosavi and Michael Strube. Lexical Features in Coreference Resolution: To be Used With Caution. Proceedings of ACL (2017). ↩︎
Kevin Clark and Christopher D. Manning. Improving Coreference Resolution by Learning Entity-Level Distributed Representations. Proceedings of ACL (2016). ↩︎
Coreference resolution is the task of clustering mentions in text that refer to the same underlying real world entities. For example, if mentions "Hilary Clinton, "First Lady of the United States" and "United States Secretary of State" occur in text, they have to be clustered together. ↩︎
Omer Levy, Steffen Remus, Chris Biemann and Ido Dagan. Do Supervised Distributional Methods Really Learn Lexical Inference Relations?. Proceedings of NAACL-HLT (2015). ↩︎
In linguistics, a hyponym is a word or phrase whose semantic field is included within that of another word, its hypernym. ↩︎
Aishwarya Agrawal, Dhruv Batra, and Devi Parikh. Analyzing the Behavior of Visual Question Answering Models. Proceedings of EMNLP (2016). ↩︎
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. VQA: Visual Question Answering. Proceedings of ICCV (2015). ↩︎
The goal of visual question answering is to answer questions about given images. ↩︎
Yonatan Bisk is a postdoctoral researcher at the University of Washington working with Yejin Choi. His research is in the area of NLP focusing on language grounding and weakly supervised learning. He works on teaching computers to understand language and the world by learning representations that link abstract language to low-level actions. He previously worked with Daniel Marcu at the Information Sciences Institute at USC, completed his Ph.D. with Julia Hockenamier at the University of Illinois at Urbana-Champaign in unsupervised grammar induction, and received his BS while working with Risto Miikkulainen at the University of Texas at Austin. ↩︎
Omer Levy is a postdoctoral researcher at the University of Washington, working with Luke Zettlemoyer. He is interested in realizing high-level semantic applications such as question answering and summarization to help people cope with information overload. At the heart of these applications are challenges in textual entailment and semantic similarity, which form the core of his current research. He is also interested in the current advances in deep learning and how they can facilitate semantic applications. He loves teaching, and enjoy the challenge of communicating complex concepts clearly and concisely. He completed his Ph.D. at Bar-Ilan University with the supervision of Prof. Ido Dagan and Dr. Yoav Goldberg and received his MS and BS at Technion – Israel Institute of Technology with the supervision of Shaul Markovitch. ↩︎
Mark Yatskar is a postdoctoral researcher at the Allen AI Young Investigator Program. His interests are in the intersection of language and vision, language generation, and language grounding. He has been developing a new formalism for events in images called situation recognition. He completed his Ph.D at University of Washington co-advised by Luke Zettlemoyer and Ali Farhadi. Prior to UW, he worked with Lillian Lee at Cornell on language simplification. ↩︎
Christopher Manning is the inaugural Thomas M. Siebel Professor in Machine Learning in the Departments of Computer Science and Linguistics at Stanford University. His research goal is computers that can intelligently process, understand, and generate human language material. Manning is a leader in applying Deep Learning to Natural Language Processing, with well-known research on Tree Recursive Neural Networks, sentiment analysis, neural network dependency parsing, the GloVe model of word vectors, neural machine translation, and deep language understanding. He also focuses on computational linguistic approaches to parsing, robust textual inference and multilingual language processing, including being a principal developer of Stanford Dependencies and Universal Dependencies. Find more about her numerous achievements and previous affiliations here: https://nlp.stanford.edu/manning/. ↩︎
Yann LeCun is Director of AI Research at Facebook, and Silver Professor of Dara Science, Computer Science, Neural Science, and Electrical Engineering at New York University, affiliated with the NYU Center for Data Science, the Courant Institute of Mathematical Science, the Center for Neural Science, and the Electrical and Computer Engineering Department. His current interests include AI, machine learning, computer perception, mobile robotics, and computational neuroscience. He has published over 180 technical papers and book chapters on these topics as well as on neural networks, handwriting recognition, image processing and compression, and on dedicated circuits and architectures for computer perception. Since the late 80's he has been working on deep learning methods, particularly the convolutional network model. Find more about his numerous achievements and previous affiliations here: http://yann.lecun.com/. ↩︎
Yejin Choi is an associate professor of Paul G. Allen School of Computer Science & Engineering at the University of Washington, adjunct of the Linguistics department, and affiliate of the Center for Statistics and Social Sciences. She is also a senior research manager at the Allen Institute for Artificial Intelligence. Previously, she was an assistant professor at the Computer Science Department of Stony Brook University. She received her Ph.D. in Computer Science at Cornell University (advisor: Prof. Claire Cardie) and BS in Computer Science and Engineering at Seoul National University in Korea. She is a co-recepient of the Marr Prize (best paper award) at ICCV 2013 and named among IEEE AI's 10 to Watch in 2016. ↩︎
"Within NLP, a number of core tasks involve generating text, conditioned on some input information. Prior to the last few years, the predominant techniques for text generation were either based on template or rule-based systems, or well-understood probabilistic models such as n-gram or log- linear models. Deep learning methods have recently achieved great empirical success on machine translation, dialogue response generation, summarization, and other text generation tasks. At a high level, the technique has been to train end-to-end neural network models consisting of an encoder model to produce a hidden representation of the source text, followed by a decoder model to generate the target." ↩︎
Ari Holtzman, Jan Buys, Maxwell Forbes, Antoine Bosselut, David Golub and Yejin Choi. Learning to Write with Cooperative Discriminators. Proceedings of ACL (2018). ↩︎
"Natural Language Understanding (NLU) addresses how to best handle unstructured inputs that are governed by poorly defined and flexible rules and convert them into a structured form that a machine can understand and act upon. While humans are able to effortlessly handle mispronunciations, swapped words, contractions, colloquialisms, and other quirks, machines are less adept at handling unpredictable inputs." ↩︎
The annual Metrics Shared Task of WMT evaluates the performance of automatic machine translation metrics in their ability to provide a substitute for human assessment of translation quality. See Bojar et al. Results of the WMT17 Metrics Shared Task. Proceedings of WMT (2017). ↩︎
Xin Wang, Wenhu Chen, Yuan-Fang Wang and William Yang Wang. No Metrics Are Perfect: Adversarial Reward Learning for Visual Storytelling. Proceedings of ACL (2018). ↩︎
Ting-Hao (Kenneth) Huang, Francis Ferraro, Nasrin Mostafazadeh, Ishan Misra, Aishwarya Agrawal, Jacob Devlin, Ross Girshick, Xiaodong He, Pushmeet Kohli, Dhruv Batra, C. Lawrence Zitnick, Devi Parikh, Lucy Vanderwende, Michel Galley, Margaret Mitchell. Visual Storytelling. Proceedings of NAACL-HLT (2016). ↩︎
Steven J. Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross and Vaibhava Goel. Self-critical Sequence Training for Image Captioning. Proceedings of CVPR (2017). ↩︎
Hannah Rashkin, Maarten Sap, Emily Allaway, Noah A. Smith and Yejin Choi. Event2Mind: Commonsense Inference on Events, Intents, and Reactions. Proceedings of ACL (2018). ↩︎
Maxwell Forbes and Yejin Choi. Verb Physics: Relative Physical Knowledge of Actions and Objects. Proceedings of ACL (2017). ↩︎
The text-centric modeling of language, which focuses on syntactic and semantic labeling of surface words. ↩︎
The world-centric modeling of procedural language that focuses on aspect of world state changes and abstracts away from the surface strings. ↩︎
Antoine Bosselut, Omer Levy, Ari Holtzman, Corin Ennis, Dieter Fox and Yejin Choi. Simulating Action Dynamics with Neural Process Networks. Proceedings of ICLR (2018). ↩︎
Todor Mihaylov and Anette Frank. Knowledgeable Reader: Enhancing Cloze-Style Reading Comprehension with External Commonsense Knowledge. Proceedings of ACL (2018). ↩︎
The reading comprehension task setting where the question is formed by replacing a token in a sentence of the story with a placeholder. ↩︎
Dan Roth is the Eduardo D. Glandt Distinguished Professor at the Department of Computer and Information Science, University of Pennsylvania. Roth was recognized "for major conceptual and theoretical advances in the modeling of natural language understanding, machine learning, and reasoning." He has published broadly in machine learning, natural language processing, knowledge representation and reasoning and learning theory, and has developed advanced machine learning based tools for natural language applications that are being used widely by the research community. Find more about his numerous achievements and previous affiliations here: http://l2r.cs.uiuc.edu/. ↩︎
Dan Roth. Incidental Supervision: Moving beyond Supervised Learning. Proceedings of AAAI (2017). ↩︎
Percy Liang is Assistant Professor of Computer Science and Statistics, Stanford University. His research is to develop trustworthy agents that can communicate effectively with people and improve over time through interaction. He broadly identifies with the machine learning and NLP communities. Much of his work has centered around the task of converting a user's request to simple computer programs that specify the sequence of actions to be taken in response. He contributed to creation the SQuAD dataset to advance research on reading comprehension. Recently, he has been exploring agents that learn language interactively, or can engage in a collaborative dialogue with humans. He thinks it is critical to build tools to help us make machine learning more reliable "in the wild." Recently, he has worked on estimating the accuracy of a predictor on an unknown distribution, using influence functions to understand black-box models, and trying to provide formal guarantees that a learning algorithm is safe from adversaries. He is a strong proponent of efficient and reproducible research. ↩︎
Juncen Li, Robin Jia, He He and Percy Liang. Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer. Proceedings of NAACL-HLT (2018). ↩︎
Converting a sentence with one attribute (negative sentiment) to one with a different attribute (positive sentiment), while preserving all attribute-independent content. ↩︎
Benedikt Buenz, Percy Liang, Leonardo de Moura, David L. Dill. Learning a SAT solver from single-bit supervision. Daniel Selsam, Matthew Lamm. arXiv preprint arXiv:1802.03685, 2018. ↩︎
SAT problem: Given a boolean formula, does there exist an assignment that satisfies it? ↩︎
Devi Parikh is an Assistant Professor in the School of Interactive Computing at Georgia Tech, and a Research Scientist at Facebook AI Research (FAIR). Her research interests include computer vision and AI in general and visual recognition problems in particular. Her recent work involves exploring problems at the intersection of vision and language, and leveraging human-machine collaboration for building smarter machines. She has also worked on other topics such as ensemble of classifiers, data fusion, inference in probabilistic models, 3D reassembly, barcode segmentation, computational photography, interactive computer vision, contextual reasoning, hierarchical representations of images, and human-debugging. Find more about his numerous achievements and previous affiliations here: https://www.cc.gatech.edu/~parikh/. ↩︎
Gary Marcus, scientist, bestselling author, and entrepreneur was CEO and Founder of the machine learning startup Geometric Intelligence, recently acquired by Uber. As a Professor of Psychology and Neural Science at NYU, he has published extensively in fields ranging from human and animal behavior to neuroscience, genetics, and artificial intelligence, often in leading journals such as Science and Nature. As a writer, he contributes frequently to the The New Yorker and The New York Times, and is the author of four books, including The Algebraic Mind, Kluge: The Haphazard Evolution of the Human Mind, and The New York Times Bestseller, Guitar Zero, and also editor of the recent book, The Future of the Brain: Essays By The World's Leading Neuroscientists, featuring the 2014 Nobel Laureates May-Britt and Edvard Moser. ↩︎
Gary Marcus. Deep Learning: A Critical Appraisal. arXiv preprint arXiv:1801.00631 (2018). ↩︎
Gary Marcus. Innateness, AlphaZero, and Artificial Intelligence. arXiv preprint arXiv:1801.05667 (2018). ↩︎
Debate "Does AI Need More Innate Machinery? (Yann LeCun, Gary Marcus). https://youtu.be/vdWPQ6iAkT4. ↩︎
Ernest Davis and Gary Marcus. Commonsense Reasoning and Commonsense Knowledge in Artificial Intelligence. In Communications of the ACM (2015). ↩︎



{kind=link}
{kind=link}
{kind=link}
{kind=link}