
Have your conference or journal reviewers ever completely misunderstood your paper or raised unreasonable objections? Ours certainly have, and it is not an enjoyable experience. The million dollar question is whether this is an inevitable occupational hazard of academic life, or there is something that we can do about the infamous Reviewer #2.
This may be an unpopular opinion, but our new position paper argues that the bad reviews are a consequence of the goals and the organization of peer review as we currently have it, and not simply because Reviewer #2 is evil incarnate. This is good news: if we understand what is wrong in our reviewing system, we can fix it. This piece focuses on NLP, but many problems and potential solutions are applicable to other fields.
Why is peer review so difficult?
The NLP community can actually answer this question because peer review is fundamentally an annotation task: we present the reviewers with papers and review forms, and collect their annotations (scores and comments). Then area chairs receive the reviews, and provide their own annotations (acceptance recommendations). For any annotation task, we know that the quality of annotations and the inter-annotator agreement heavily depends on how clear each decision is, whether all annotators interpret the instructions in the same way, and whether they have the incentive to do the best job they can, or just the minimum possible amount of effort.
In the case of peer review, do we have a clear decision boundary? No. Taking citation counts as a proxy, (Anderson, 2009) argues that research paper merit is Zipf-distributed: many papers are clear rejects, while a few are clear accepts. In between those two extremes, decisions are very difficult, and any differences between the best rejected and the worst accepted paper are tiny, even given the best possible set of reviewers. Yet, the fundamental goal of peer review in a top conference is to rank all papers by merit so as to only accept the top 20-25% and reject the rest:

If the paper merit is Zipf-distributed, for many papers the acceptance decisions would be very difficult. And this prediction bears out: NeurIPS 2014 conducted an experiment where 10% of submissions were reviewed by two independent sets of reviewers. These reviewers disagreed on 57% of accepted papers (Price, 2014). In other words, if you simply re-ran the reviewer assignment with the same reviewer pool, over half of accepted NeurIPS papers would have been rejected!
An exacerbating factor is that papers in an interdisciplinary area such as NLP are a mixed bag of contribution types (experiments, data, theory), methodology (deep learning, proofs, model analysis, theoretical arguments), different language material, and goals and interests of the authors (applications, basic research, meta-research etc). In such a field, we will have a lot of apples-to-oranges comparisons with no correct answers. Suppose you were assigned a paper with a stronger evaluation, and a paper with a more original model: which one would you rank higher, and how much higher? How does either of these empirical papers compare to a theoretical work or a position paper?
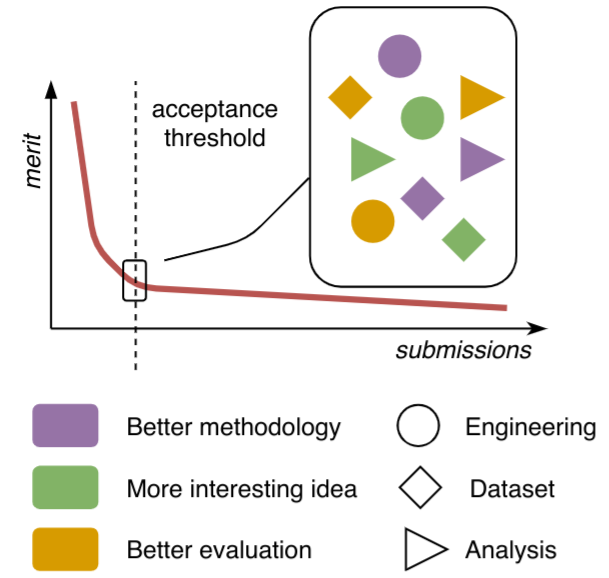
How the reviewers cope
So, the peer review process, as it is currently formulated, is an annotation task that is objectively very difficult, if at all possible. And we do not even have the incentives to spend a lot of time on it: peer review is currently invisible service work that is not often budgeted for as part of a paid research job.
What do humans do when they have to reason under high uncertainty, and quickly? They rely on biases and heuristics (Kahneman, 2013). In this case, the heuristics power much of the "review-to-reject" thinking: if you can only find a reason to justify a low score, you can move on to the other items on your overflowing to-do list. Some of the more famous Reviewer #2 heuristics in NLP include:
- Non-native writing: papers with non-native English and/or unconventional writing style may even be perceived as worse than papers with weaker content (K. W. Church, 2020)
- No SOTA results: claiming state-of-the-art performance is often viewed as a proof of a valid research contribution, and the lack of such results - as evidence of no contribution. In reality, such results are neither necessary nor sufficient (Rogers, 2020a).
- Untrendy topic: the main track of a top conference is more likely to welcome a paper on a "scientifically sexy" topic (Smith, 2010). In NLP, it is currently easier to publish on Transformers than something "niche" like historical text normalization.
- No deep learning: the "mainstream" NLP papers currently focus on deep learning experiments, making theoretical work, linguistic resources (Rogers, 2020b), and cross-disciplinary efforts look like suspicious outliers - even though "computational linguistics" is not just about deep learning.
- Work not-on-English: English is the "default" language to study (Bender, 2019), and work on other languages is easily accused of being "niche" and non-generalizable - even though English only workis equally non-generalizable.
- Not-top-people: where the paper can be deanonymized from a preprint, the famous authors and labs with borderline papers are more likely to get accepted, while underrepresented communities are at disadvantage (Rogers, 2020c).
- Simplicity: a solution that seems too simple may look like the authors did not work hard enough, even though the goal is to solve the problem rather than solve it in a complex way.
- Obvious follow-up questions: if it is easy to think of something to add, the paper may be perceived as lacking substance, even if the amount of work is comparable with the papers that do not easily provoke follow-up questions. That would explain why short papers are significantly harder to publish (e.g. EMNLP 2020 accepted 24.6% long vs 16.7% short papers).
- Novelty: absurd as it may sound, genuinely novel work is easier to object to, and thus harder to publish than then the 'safe', incremental papers (Bhattacharya & Packalen, 2020; K. Church, 2017; Smith, 2010).
- "I'd do it differently": A reviewer may consciously or unconsciously take a dislike to a study for not matching their own methodological choices and interests, even if the study is still sound and valid.
What can we do to improve peer review?
If the system is so broken - can we just get rid of it? Unfortunately, no. Most hiring and grant committees on the planet consist largely of non-experts, and these non-experts need some kind of "research excellency" metric. This is the role played by the selectivity of top conferences and journals. If they simply increase the acceptance rate, they will lose their status, and our field will not be able to compete with other fields for research resources. And no, we cannot just take citation counts as a proxy for paper merit, because they are heavily influenced by the current status of the authors and their institutions.
EMNLP 2020 experimented with a "soft acceptance rate increase": establishing a companion volume called "Findings of EMNLP". It accepted roughly 15% submissions that "narrowly missed acceptance to the main conference, but were judged to be solid, well-executed research, and worthy of publication". "Findings" gives the authors the option to publish quickly and move on, but its very existence is likely to impact how the reviewers approach the non-mainstream papers, exacerbating the above biases rather than addressing the core problem. Furthermore, no matter how respected the "Findings" may become in the field, in the eyes of most hiring/grant committees it will always be second-tier, and continue marginalizing "untrendy" researchers and even whole subfields.
Since the acceptance rates are a necessary evil, we cannot solve the fundamental problem of the mismatch between the Zipf distribution of the paper merit, and the target accept-reject distribution. What we can do is reduce the number of papers rejected due to reviewer biases. The decisions around acceptance threshold will still be difficult and arbitrary to some degree, but at least we would be getting higher-quality feedback that would help us improve the papers, and that in the long run would surely be better for the field. Reducing biases would also help us to accept a more diverse selection of papers, which is also good for an interdisciplinary field.
How can we do it? The biases and heuristics are a coping mechanism for what is fundamentally a poorly defined annotation task with poor incentives. Fundamentally, we need to reduce the need to resort to heuristics, and this can be done in two complementary ways:
- Improving the incentives: increasing the visibility and value of peer review in researcher profiles (publons provide a great example), providing perks like free membership and conference registration.
- Reducing the uncertainty: improving paper-to-reviewer matching, offering fine-grained tracks and review forms tailored for different paper types. As for the questions like "does stronger evaluation count for more or less than a more original model?", these are apples-to-oranges comparisons that should be defined in the editorial policies, and pre-announced in CFPs, so that the authors would know what to expect and send their work to better-matching venues. The program chairs should then try to make consistent decisions based on reviewers' answers to clear questions, rather than something ambiguous like the "overall recommendation" (which everyone has a different formula for).
Many authors are also calling for measures to disincentivize the bad reviews e.g. by making the *ACL reviews public. However, this does not address the core problem (high-uncertainty decision-making), and public negative reviews can have repercussions for junior researchers.
What holds us back?
At this point, the reader may join the disappointed reviewers of our paper and say that we are not proposing anything new. It is obvious that something like improved paper-to-reviewer matching would improve review quality, isn't it? Well, this is precisely what holds us back. With respect to peer review, we need implementation rather than conceptual innovation, but as researchers we tend to only value and reward the latter.
You might ask — aren't the conference organizers already doing all that? Well, so far it has not been systematic. Each of the major *ACL conferences are organized by a new set of people each year, and they all introduce new policies, usually changing many things at once. While this brings a lot of diversity, we have no way to test which changes are more successful: the organizers typically do some analysis, but each of them only has access to their own data, and they may not necessarily be asking the same questions. For example, ACL 2020 handled the increased reviewer load by forcing all authors to register as reviewers, and EMNLP 2020 - by requiring the senior authors to mentor junior reviewers. These two different recruitment strategies were accompanied by different review forms and policies. The end result is that we ran two very large-scale experiments with ourselves as the guinea pigs, but we do not really know what worked better and should be used next year. And even if there was such a conclusion, we have no mechanism to ensure that the more successful policy would be kept.
Better review forms, better mechanisms for matching papers and reviewers, and more consistent editorial policies are not going to materialize out of thin air. This is difficult meta-research work which will take many systematic experiments, and which each field has to perform for itself. This should be good news: we are researchers in a fast-growing field, and many young minds are looking for new avenues. But this is actually bad news, because such work is currently very hard to publish within NLP. Without publication incentives, without recognizing such work as main-track-worthy research it is either not going to be done, or it will be taken to outside venues such as PEERE and have little impact on the practices in the field that it should help to improve. In a way, NLP peer review… prevents research on NLP peer review.
The ACL anthology currently lists only four studies of peer review from the meta-research perspective, as opposed to thousands dedicated to all kinds of text analysis. Think about it. The researchers in NLP are not studying the highly frustrating process that governs their own careers, even though they are experts in text analysis, and the data for that frustrating process is textual, structured, abundant, and regularly collected from themselves. Numerous annotation experiments are run every year with themselves as subjects - and no one seems to be checking the results!
Of these four studies, one contributed an actionable insight: ACL reviewers appear to converge to the mean after rebuttals (Gao et al., 2019). This could be countered by letting the reviewers to interact only with the authors during the rebuttal, but not with each other. Yet, to our knowledge, there was no serious discussion of this finding in the context of design of the peer review process for subsequent ACL conferences.
First steps forward
Large-scale changes happen when enough people are paying enough attention to a given problem: for instance, climate change is not going to be seriously addressed until enough voters put it ahead of anything else. The core mechanisms in the academic world are not so different. We all have known about the above problems with peer review for a long time, but what we mostly do with that knowledge is complain when we get bad reviews. The cycle could be sketched as follows:
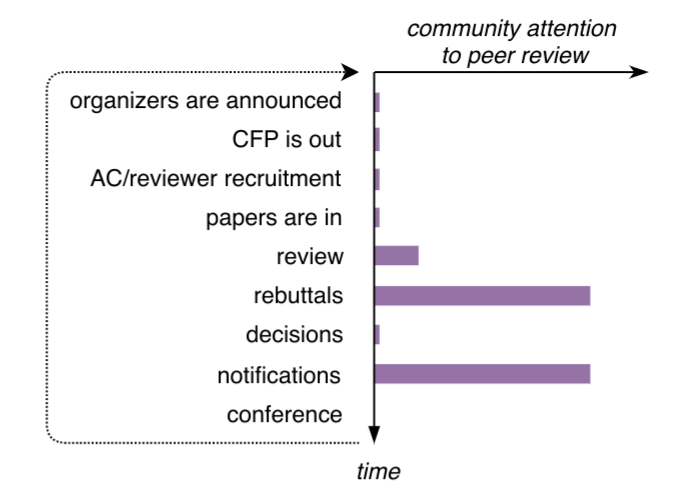
If we want to change things, first of all we must complain talk and think about peer review a lot more, and not only when we're bitter with disappointment. We are the peer reviewers, maybe even part-time reviewers #2! Share your frustration, your insights about what could be done better in the process. Even more importantly, share the good practices when you see them. Talk and think about how this could be done at scale, what studies and experiments would convince the community to adopt better practices, and how we need such studies and experiments to be conducted. We need to persuade a whole lot of the other peer reviewers (ourselves) that meta-research on this process is valid, main-track-worthy research, and not a suspicious outlier among the torrent of deep learning papers.
The second thing to do would be to create the mechanisms for enabling this work. Let us stress that the current lack of systematic testing of different peer review strategies is not the fault of conference organizers. It's just that it would require a lot of work on top of the gazillion things they are already doing as unpaid volunteers. Also, it is a long-term rather than per-conference project, which requires long-term strategies and mechanisms that are not currently in place. We need to regularly collect and regularly publish our peer review corpora, to develop mechanisms for running systematic experiments on peer review forms and policies, and for the subsequent implementation of the successful ones. None of this is likely to happen without ACL, and so we should keep all the above in mind during elections and business meetings. We need new roles for systematic development, testing, and implementation of peer review policies, as well as incentivizing good peer review work by increasing its prestige and visibility. There is already a committee working on the rolling review reform, which aims at decreasing the volume of reviews, but this is orthogonal to our topic.
And the third thing is the practical research to be done by us as NLP researchers, especially those who work in the areas of annotation and scholarly document processing. Can we develop methods to better match papers to reviewers (not only by topics, but also the core methodology and target language)? What can we do for the papers for which we cannot find reviewers who are working in that area? Can we help the area chairs to flag shallow, heuristic-based reviews, as well as the rude and one-liner reviews? When does that happen, and do certain types of papers get disproportionately affected? What kinds of tracks and review forms would improve the reviewer agreement and make the job easier for the chairs? Can we detect and normalize the cases where the reviewers' comments do not match their numeric scores? These are all legitimate and interesting NLP topics, and doing such research + implementing its results is the best possible response to Reviewer #2.
Acknowledgements
This paper builds on numerous conversations, blog and Twitter posts. We would like to thank (in alphabetical order) Emily M. Bender, Trevor Cohn, Leon Derczynski, Matt Gardner, Yoav Goldberg, Yang Liu, Tal Linzen, Ani Nenkova, Graham Neubig, Ted Pedersen, Ehud Reiter, Joseph M. Rogers, Anna Rumshisky, Amanda Stent, Nathan Schneider, Karin Vespoor, Bonnie Webber, and many others. We also thank the anonymous reviewers for helping us to formulate the problem. Many of the discussion points previously appeared on the Hacking Semantics blog.
To cite our paper:
@inproceedings{rogers-augenstein-2020-improve,
title = "What Can We Do to Improve Peer Review in {NLP}?",
author = "Rogers, Anna and Augenstein, Isabelle",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.112",
pages = "1256--1262"}
References
Anderson, T. (2009). Conference reviewing considered harmful. ACM SIGOPS Operating Systems Review, 43(2), 108. https://doi.org/10.1145/1531793.1531815
Bender, E. M. (2019, September 15). The #BenderRule: On Naming the Languages We Study and Why It Matters. The Gradient. https://thegradient.pub/the-benderrule-on-naming-the-languages-we-study-and-why-it-matters/
Bhattacharya, J., & Packalen, M. (2020). Stagnation and Scientific Incentives. National Bureau of Economic Research. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3539319
Church, K. (2017). Emerging trends: Inflation. Natural Language Engineering, 23(5), 807–812. https://doi.org/10.1017/S1351324917000286
Church, K. W. (2020). Emerging trends: Reviewing the reviewers (again). Natural Language Engineering, 26(2), 245–257. https://doi.org/10.1017/S1351324920000030
Gao, Y., Eger, S., Kuznetsov, I., Gurevych, I., & Miyao, Y. (2019). Does My Rebuttal Matter? Insights from a Major NLP Conference. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 1274–1290. https://doi.org/10.18653/v1/N19-1129
Kahneman, D. (2013). Thinking, fast and slow (1st pbk. ed). Farrar, Straus and Giroux.
Price, E. (2014). The NIPS experiment. Moody Rd. http://blog.mrtz.org/2014/12/15/the-nips-experiment.html
Rogers, A. (2020a, April 3). Peer review in NLP: Reject-if-not-SOTA. Hacking Semantics. https://hackingsemantics.xyz/2020/reviewing-models/
Rogers, A. (2020b, April 16). Peer review in NLP: Resource papers. Hacking Semantics. https://hackingsemantics.xyz/2020/reviewing-data/
Rogers, A. (2020c, July 15). Should the reviewers know who the authors are? Hacking Semantics. https://hackingsemantics.xyz/2020/anonymity/
Smith, R. (2010). Classical peer review: An empty gun. Breast Cancer Research, 12(4), S13. https://doi.org/10.1186/bcr2742



{kind=link}
{kind=link}
{kind=link}
{kind=link}