
During the past decade, machine learning has exploded in popularity and is now being applied to problems in many fields. Traditionally, a single machine learning model is devoted to one task, e.g. classifying images, which is known as single-task learning (STL). There are some advantages, however, to training models to make multiple kinds of predictions on a single sample, e.g. image classification and semantic segmentation. This is known as Multi-task learning (MTL). In this article, we discuss the motivation for MTL as well as some use cases, difficulties, and recent algorithmic advances.
Motivation for MTL
There are various reasons that warrant the use of MTL. We know machine learning models generally require a large volume of data for training. However, we often end up with many tasks for which the individual datasets are insufficiently sized to achieve good results. In this case, if some of these tasks are related, e.g. predicting many diseases and outcomes from a patient’s profile, we can merge the features and labels into a single larger training dataset, so that we can take advantage of shared information from related tasks to build a sufficiently large dataset.
MTL also improves the generalization of the model. Using MTL, the information learned from related tasks improves the model’s ability to learn a useful representation of the data, which reduces overfitting and enhances generalization. MTL can also reduce training time because instead of investing time training many models on multiple tasks, we train a single model.
MTL is crucial in some cases, such as when the model will be deployed in an environment with limited computational power. Since machine learning models often have many parameters that need to be stored in memory, for applications where the computational power is limited (e.g. edge devices), it is preferable to have a single MTL network with some shared parameters, as opposed to multiple STL models doing related tasks. For example, in self-driving cars, we need multiple tasks to be done in real-time, including object detection and depth estimation. Having multiple neural networks doing these tasks individually requires computational power that might not be available. Instead, using a single model trained with MTL reduces the memory requirements and speeds up inference.
The Problem with Multitasking
Despite the advantages of MTL, there are some cases where the approach can actually hurt performance. During the training of an MTL network, tasks can compete with each other in order to achieve a better learning representation i.e. one or more tasks can dominate the training process. For example, when instance segmentation (segmenting a separate mask for each individual object in an image) is trained alongside semantic segmentation (classifying of objects at pixel level) in an MTL setting, the latter task often dominates the learning process unless some task balancing mechanism is employed [1].
Furthermore, the loss function of MTL may also be more complex as a result of multiple summed losses, thereby making the optimization more difficult. In these cases, there is a negative effect of cooperating on multiple tasks, and individual networks that are trained on single tasks may perform better.
So when should we multitask? Answering that question is difficult, but in the last few years, there have been a series of important papers that propose algorithms to learn what and when tasks should be learned together, and when tasks should be learned separately. Here are three important papers towards that end:
AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning
Motivation: Generally in MTL, one of two approaches is used. One is hard parameter sharing, in which initial layers are shared up until a certain point after which the network branches out to make predictions for individual tasks. The problem with this approach is that it forces the machine learning practitioner to specify which layers are to be shared, which may not be optimal for the tasks at hand. In soft parameter sharing, each task is learned with separate models and weights, but the objective function includes a loss term that encourages the parameters of the models to be similar. The downside of soft parameter sharing is the large number of parameters, especially as the number of tasks grows.
To combine the benefits of these approaches, X. Sun et al. proposed, “AdaShare: Learning What to Share for Efficient Deep Multi-Task Learning” (2020) [2]. The primary goal of the researchers was to specify a single multi-layer architecture for MTL and train a policy that determines which layers to share by multiple tasks, which layers to use for specific tasks and which layers to skip for all tasks while ensuring the model provides highest performance at its most compact form.
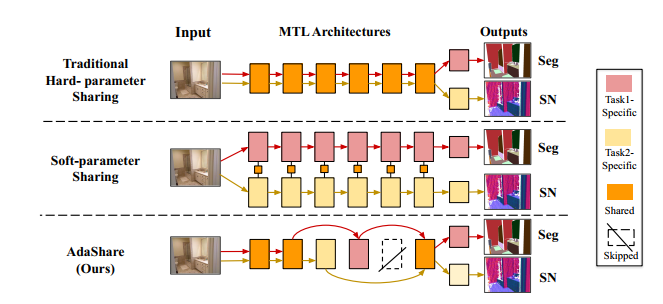
Method: The method proposed by the authors jointly optimizes the network parameters and a binary random variable ul,k for each layer l and each task in Tk, where Tk represents a set of k tasks. Here, the binary random variable or policy represents which tasks are shared, skipped, or done individually by a particular block for multiple tasks. Since the policy variable is non-differentiable, the Gumbel-Softmax sampling [3] approach is used to optimize it. The loss function proposed in the paper is the sum of the task-specific losses, a sparsity loss to encourage model compactness, and a sharing loss that encourages block sharing across tasks.
Limitations: The main limitation of the proposed method is that it requires the model to have skip connections between layers. While such architectures have been used in prior work (e.g. ResNets), the proposed approach cannot directly be generalized to other network architectures.
End-to-End Multi-Task Learning with Attention
Motivation: In order to do MTL effectively, a network needs to share related information from the input features between tasks, while also balancing the learning rates of individual tasks. In “End-to-End Multi-Task Learning with Attention” [4], S. Liu et al. introduce a unified approach which employs both task sharing and task balancing schemes in the learning process.
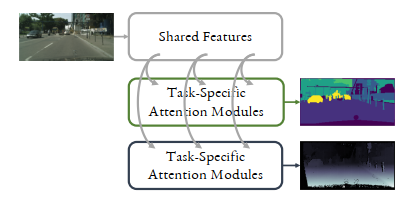
Method: This approach proposed by the authors divides a neural network architecture into two parts. The first part are standard shared layers trained on all of the features and tasks. Following these shared layers, a soft-attention mechanism collects task-specific features from the shared layers, allowing the tasks to be learned end-to-end in a self-supervised fashion. In other words, these attention modules act as feature selectors for each specific task, which are fed into the second, task-specific part of the network.
In addition, to balance the learning rates of different tasks, the authors also propose a “dynamic weight averaging” technique. At the very beginning, for the first two iterations of training, the weight for each task’s loss is initialized to 1. After each iteration, the weights are first adjusted to be the ratio of the losses over the previous two iterations for that task, and then soft-maxed so that they are between 0 and 1. With this technique, the weights adapt so that the tasks that are hardest to learn are given more weight during training.
Limitations: Although this method is seemingly effective, the experiments run by the authors of this paper (as well as the other two papers we review) are mostly limited to a small number of computer vision tasks. Although the authors try the method on one dataset with up to 10 tasks, the results are not compared with other state-of-the-art MTL methods. Further evaluation is needed to understand how this method scales with increasing number and diversity of tasks.
Which Tasks Should Be Learned Together in Multi-task Learning?
Motivation: In this paper by Trevor Standley et al. [5], the authors consider not only how to group tasks together for MTL, but also explore how much computational budget should be assigned to each group of tasks. The authors introduce a new learning framework for multi-task learning which maximizes the performance on the tasks within a given computational budget.
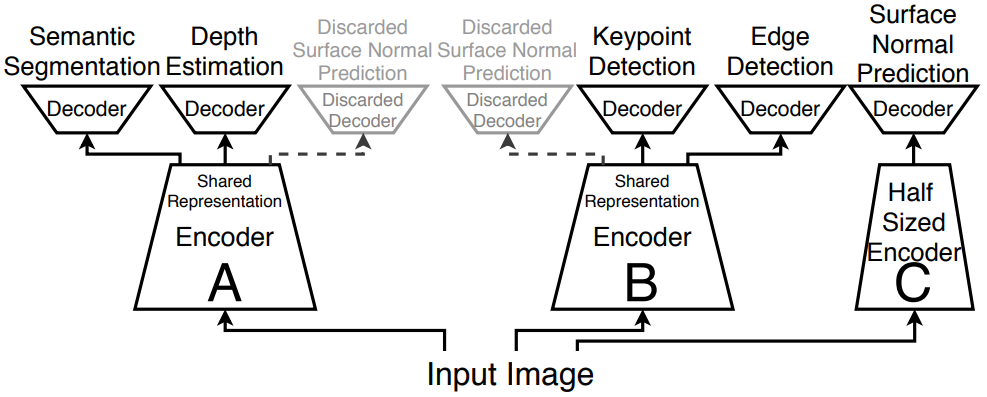
Method: To study the relationship between the sets of tasks, the authors carry out empirical studies of model performance in different settings on the Taskonomy dataset [6]. The results of the study highlight the influence of network capacity, auxiliary tasks, and the amount of training data on the task relationships and overall MTL performance.
Based on the results of the study, the authors propose three techniques for MTL: optimal solution (OS), early stopping approximation (ESA) and higher order approximation (HOA). The first approach is based on the branch-and-bound algorithm, which uses a combinatorial approach to choose the optimal solution in the space of all the fully-trained network-task combinations, based on performance and inference time.
Since OS can take a significant amount of time to run, the latter approaches are faster approximations. ESA reduces runtime by estimating the task relationships using results from the early stage of training and then training the chosen network configuration until convergence. HOA calculates per-task loss estimates (based on the individual tasks) and uses this estimate to approximate the performance of network configurations.
Limitations: Since the optimal solution is based on the branch-and-bound algorithm, it has a runtime that may be infeasible as the number of tasks increases. In ESA, the correlation between the early training and final training performance is not necessarily high and hence gives misleading results for the task relationships. HOA completely ignores task interactions and nonlinear effects associated with grouping tasks together. As a consequence, both ESA and HOA suffer a degradation in prediction performance.
Conclusion and Future Work
Because of the increased importance of multi-task learning, a large number of methods have been proposed to automatically learn which tasks should be jointly learned. However, these methods have not been exhaustively evaluated, especially on large numbers of tasks and on domains outside of computer vision. New methods may be needed to scale these methods to tens or hundreds of tasks and on other domains where multitasking is important, such as natural language processing and biomedical data.
References
[1] Alex Kendall, Yarin Gal, Roberto Cipolla (2018). Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018.
[2] Sun, X., Panda, R., Feris, R., & Saenko, K. (2020). Adashare: Learning what to share for efficient deep multi-task learning. Annual Conference on Neural Information Processing Systems, NeurIPS, December 6-12, 2020.
[3] Jang, E., Gu, S., & Poole, B. (2016). Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144.
[4] Liu, S., Johns, E., & Davison, A. J. (2019). End-to-end multi-task learning with attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1871-1880).
[5] Standley, T., Zamir, A., Chen, D., Guibas, L., Malik, J., & Savarese, S. (2020). Which tasks should be learned together in multi-task learning?. In International Conference on Machine Learning (pp. 9120-9132). PMLR.
[6] Zamir, A. R., Sax, A., Shen, W. B., Guibas, L. J., Malik, J.,and Savarese, S. Taskonomy: Disentangling task transfer learning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
Author Bios
Aminul Huq is a Master's degree student at Tsinghua University. His research interest lies in computer vision and adversarial machine learning.
Mohammad Hanan Gani is an ML Engineer at Harman International Inc. where he works in the R&D team to build AI solutions to solve the challenging problems in the domain of automation. His research interests lie in the unsupervised deep learning, Few shot learning and Multi-task learning in computer vision.
Ammar Sherif is a Teaching and Research Assistant at Nile University. He is doing research related to learning efficiently including topics from Multi-Task Learning and Uncertainty Estimation.
Abubakar Abid is the CEO/cofounder of Gradio, where he builds tools to explore and explain machine learning models. He also researches applications of machine learning to medicine as a researcher at Stanford University.
Acknowledgements
The banner image for this post was taken from flickr
Citation
For attribution in academic contexts or books, please cite this work as:
Aminul Huq, Mohammad Hanan Gani, Ammar Sherif, Abubakar Abid, "How to Do Multi-Task Learning Intelligently", The Gradient, 2021.
BibTeX citation:
@article{aminulmultitask2021,
author = {Huq, Aminul and Gani, Mohammad Hanan, and Sherif, Ammar and Abid, Abubakar},
title = {How to Do Multi-Task Learning Intelligently},
journal = {The Gradient},
year = {2021},
howpublished = {https://thegradient.pub/how-to-do-multi-task-learning-intelligently},
}






{kind=link}
{kind=link}
{kind=link}
{kind=link}