
In January 2017, four world-class poker players engaged in a three-week battle of heads-up no-limit Texas hold ’em.
They were not competing against each other. Instead, they were fighting against a common foe: an AI system called Libratus that was developed by Carnegie Mellon researchers Noam Brown and Tuomas Sandholm. The official competition between human and machine took place over three weeks, but it was clear that the computer was king after only a few days of play. Libratus eventually won[1] by a staggering 14.7 big blinds per 100 hands, trouncing the world’s top poker professionals with 99.98% statistical significance.
This was the first AI agent to beat professional players in heads-up no-limit Texas hold ’em.
Libratus is not the only game-playing AI to make recent news headlines, but it is uniquely impressive.
In 2015, DeepMind’s Deep Q-network mastered[2] a number of Atari games. A Deep Q-network learns how to play under the reinforcement learning framework, where a single agent interacts with a fixed environment, possibly with imperfect information.
Also in 2015, DeepMind's AlphaGo used similar deep reinforcement learning techniques to beat professionals at Go for the first time in history. Go is the opposite of Atari games to some extent: while the game has perfect information, the challenge comes from the strategic interaction of multiple agents.
Libratus, on the other hand, is designed to operate in a scenario where multiple decision makers compete under imperfect information. This makes it unique: poker is harder than games like chess and Go because of the imperfect information available. (On a chessboard, every piece is visible, but in poker no player can see another player’s cards.)
At the same time, it's harder than other imperfect information games, like Atari games, because of the complex strategic interactions involved in multi-agent competition. (In Atari games, there may be a fixed strategy to "beat" the game, but as we'll discuss later, there is no fixed strategy to "beat" an opponent at poker.)
This combined uncertainty in poker has historically been challenging for AI algorithms to deal with. That is, until Libratus came along. Libratus used a game-theoretic approach to deal with the unique combination of multiple agents and imperfect information, and it explicitly considers the fact that a poker game involves both parties trying to maximize their own interests.

Theory of Games
The poker variant that Libratus can play, no-limit heads up Texas Hold'em poker, is an extensive-form imperfect-information zero-sum game. We will first briefly introduce these concepts from game theory.
A normal form game
For our purposes, we will start with the normal form definition of a game. In this two-player game, each player has a collection of available actions: $A_1$ for Player 1, and $A_2$ for Player 2. The two players simultaneously choose actions $a_1 \in A_1$, $a_2 \in A_2$ and receive rewards $r_1(a_1, a_2)$ and $r_2(a_1, a_2)$ respectively. The game concludes after a single turn. These games are called normal form because they only involve a single action. An extensive form game, like poker, consists of multiple turns. Before we delve into that, we need to first have a notion of a good strategy.
The Nash equilibrium
Multi-agent systems are far more complex than single-agent games. An optimal policy always exists in a single-agent decision process, but with multiple agents, optimal play depends on your opponent’s strategy. To account for this, mathematicians use the concept of the Nash equilibrium.
A Nash equilibrium is a scenario where none of the game participants can improve their outcome by changing only their own strategy. Formally, a Nash equilibrium consists of strategies $\sigma_1$ and $\sigma_2$ such that if Player 1 chooses another strategy $\sigma_1'$, we have
$$
r_1(\sigma_1, \sigma_2) \geq r_1(\sigma_1', \sigma_2)
$$
This is because a rational player will change their actions to maximize their own game outcome. When the strategies of the players are at a Nash equilibrium, none of them can improve by changing his own. Thus this is an equilibrium. When allowing for mixed strategies (where players can choose different moves with different probabilities), Nash proved that all normal form games with a finite number of actions have Nash equilibria, though these equilibria are not guaranteed to be unique or easy to find.

Zero-sum games
While the Nash equilibrium is an immensely important notion in game theory, it is not unique. Thus, is hard to say which one is the optimal. Many two player games that people play (including poker) have an additional feature that one player’s reward is the negative of their opponent’s. Such games are called zero-sum.
Importantly, the Nash equilibria of zero-sum games are computationally tractable and are guaranteed to have the same unique value.
Consider a zero-sum game. For all $a_1 \in A_1$ and $a_2 \in A_2$, we have:
$$
r_1(a_1, a_2) + r_2(a_1, a_2) = 0
$$
Zero-sum games are interesting since any Nash equilibrium can be computed efficiently using the minmax theorem.
We define the maxmin value for Player 1 to be the maximum payoff that Player 1 can guarantee regardless of what action Player 2 chooses:
$$
\max\min_1 = \max_{a_1}(\min_{a_{2}} r_1(a_1, a_{2}))
$$
The corresponding minmax value of Player 1 is then the minimum payoff that Player 2 can force Player 1 into taking, if Player 2 chooses their action first:
$$
\min\max_1 = \min_{a_2}(\max_{a_{1}} r_1(a_1, a_{2}))
$$
The minmax theorem states that minmax and maxmin are equal for a zero-sum game (allowing for mixed strategies) and that Nash equilibria consist of both players playing maxmin strategies. As an important corollary, the Nash equilibrium of a zero-sum game is the optimal strategy. Crucially, the minmax strategies can be obtained by solving a linear program in only polynomial time.
More Complex Games - Extensive Form Games
While many simple games are normal form games, more complex games like tic-tac-toe, poker, and chess are not. In normal form games, two players each take one action simultaneously. In contrast, games like poker are usually studied as extensive form games, a more general formalism where multiple actions take place one after another.
See Figure 1 for an example. Player 1 first decides between $L$ and $R$. The action $R$ ends the game with payoff $(5,2)$, while $L$ continues the game, offering Player 2 choice between $l$ and $r$ (and the corresponding rewards). All the possible games states are specified in the game tree.
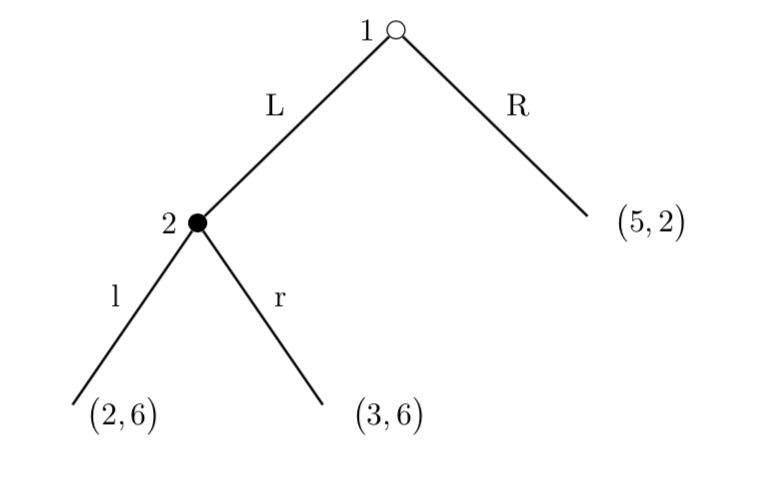
The good news about extensive form games is that they reduce to normal form games mathematically. Since poker is a zero-sum extensive form game, it satisfies the minmax theorem and can be solved in polynomial time. However, as the tree illustrates, the state space grows quickly as the game goes on. Even worse, while zero-sum games can be solved efficiently, a naive approach to extensive games is polynomial in the number of pure strategies and this number grows exponentially with the size of game tree. Thus, finding an efficient representation of an extensive form game is a big challenge for game-playing agents. AlphaGo[3] famously used neural networks to represent the outcome of a subtree of Go. In a similar vein, many of Libratus’s innovations boil down to novel ways to abstract the game to a reasonable size while preserving the essential information.
Knowing What You Do Not Know - Imperfect Information
While Go and poker are both extensive form games, the key difference between the two is that Go is a perfect information game, while poker is an imperfect information game. In a game of Go, the state of the game is determined entirely by the player’s moves, which both players see. In poker however, the state of the game depends on how the cards are dealt, and only some of the relevant cards are observed by every player. To illustrate the difference, we look at Figure 2, a simplified game tree for poker.
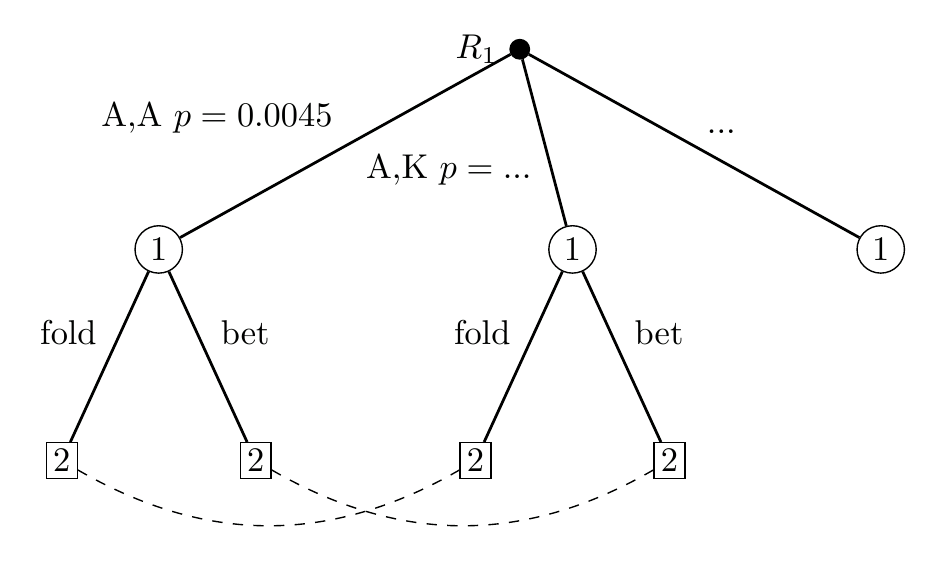
In this simplified game tree, a random card is first dealt to Player 1 with some probability specified at chance node $R_1$. Then, another random card is dealt to Player 2 at chance node $R_2$. Here, randomness is depicted by the white chance nodes $R_1$ and $R_2$, where no player takes action but a random event decides the possible outcomes. After receiving the two cards, it is Player 1’s turn to bet, who can choose to bet or to fold.
Note that players do not have perfect information and cannot see what cards have been dealt to the other player.
Let's suppose that Player 1 decides to bet. Player 2 sees the bet but does not know what cards player 1 has. In the game tree, this is denoted by the information set, or the dashed line between the two states. An information set is a collection of game states that a player cannot distinguish between when making decisions, so by definition a player must have the same strategy among states within each information set.
Thus, imperfect information makes a crucial difference in the decision-making process. A Go-playing agent asks itself the question: “based on the current state of the game, what should I do?” But a poker agent has to make a decision based on an estimate: “based on my current observations, what is the estimated distribution of all possible ground truth states of the game, and what is the best action based on that distribution?”
To decide their next action, player 2 needs to evaluate the possibility of all possible underlying states (which means all possible hands of player 1). Because the player 1 is making decisions as well, if player 2 changes strategy, player 1 may change as well, and player 2 needs to update their beliefs about what player 1 would do.
Libratus
Now we know what are some of the main challenges of poker:
- While theoretically solvable in polynomial time as a massive extensive form game, poker contains a tremendous amount of states that forbids a naive approach.
- Imperfect information complicates the decision-making process and makes solving poker even harder.
Libratus tackles poker's difficulty through three main modules:
- Creating and solving an abstraction of poker in advance
- Subgame solving during the contest
- Self improvement after each day of competition
Game abstraction
Libratus played a poker variant called heads up no-limit Texas Hold’em. Heads up means that there are only two players playing against each other, making the game a two-player zero sum game.
No-limit means that there are no restrictions on the bets you are allowed to make, meaning that the number of possible actions is enormous. In no-limit Texas Hold’em, bet sizes that differ by just one dollar cause different game states. In contrast, limit poker forces players to bet in fixed increments and was solved in 2015[4]. Nevertheless, it is quite costly and wasteful to construct a new betting strategy for a single-dollar difference in the bet. Libratus abstracts the game state by grouping the bets and other similar actions using an abstraction called a blueprint. In a blueprint, similar bets are be treated as the same and so are similar card combinations (e.g. Ace and 6 vs. Ace and 5).
Solving the blueprint
The blueprint is orders of magnitude smaller than the possible number of states in a game. Libratus solves the blueprint using counterfactual regret minimization (CFR), an iterative, linear time algorithm that solves for Nash equilibria in extensive form games. In CFR, two agents play against each other and try to minimize their own counterfactual regret with respect to the other agent’s current strategy. Libratus uses a Monte Carlo-based variant that samples the game tree to get an approximate return for the subgame rather than enumerating every leaf node of the game tree.
Nested safe subgame solving
While it’s true that the blueprint simplifies the game state, Libratus doesn’t let a bad approximation get in the way of winning. It expands the game tree in real time and solves that subgame, going off the blueprint if the search finds a better action.
Solving the subgame is more difficult than it may appear at first since different subtrees in the game state are not independent in an imperfect information game, preventing the subgame from being solved in isolation. “Unsafe” subgame solving refers to the naive approach where one assumes that the opponent’s strategy is fixed. This decouples the problem and allows one to compute a best strategy for the subgame independently. However, the assumption makes the algorithm exploitable as it does not adjust its play against changes to its opponent’s strategy.
A “safe” subgame solving method, on the other head, augments the subgame by giving the opponent some alternatives where they can modify their play to not enter the subtree being solved. In short, this ensures that for any possible situation, the opponent is no better-off reaching the subgame after the new strategy is computed. Thus, it is guaranteed that the new strategy is no worse than the current strategy. This approach, if implemented naively, while indeed "safe", turns out to be too conservative and prevents the agent from finding better strategies. Libratus therefore uses “reach” subgame solving which gives slightly weaker guarantees that the opponent is no better off for those cases where he is likely to reach this subgame instead of accounting for all possible strategy changes. The new method[5] is able to find better strategies and won the best paper award of NIPS 2017.
Self improvement
In addition, while its human opponents are resting, Libratus looks for the most frequent off-blueprint actions and computes full solutions. Thus, as the game goes on, it becomes harder to exploit Libratus for only solving an approximate version of the game.
Final words
While poker is still just a game, the accomplishments of Libratus cannot be understated. Bluffing, negotiation, and game theory used to be well out of reach for artificial agents, but we may soon find AI being used for many real-life scenarios like setting prices or negotiating wages. Soon it may no longer be just humans at the bargaining table.
Correction: A previous version of this article incorrectly stated that there is a unique Nash equilibrium for any zero sum game. The statement has been corrected to say that any Nash equilibria will have the same value. Thanks to Noam Brown for bringing this to our attention.
Citation
For attribution in academic contexts or books, please cite this work as
Jiren Zhu, "Libratus: the world's best poker player", The Gradient, 2018.
BibTeX citation:
@article{zhu2018libratus,
author = {Zhu, Jiren}
title = {Libratus: the world's best poker player},
journal = {The Gradient},
year = {2018},
howpublished = {\url{https://thegradient.pub/libratus-poker// } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.
Brown, Noam, and Tuomas Sandholm. "Superhuman AI for heads-up no-limit poker: Libratus beats top professionals." Science (2017): eaao1733. ↩︎
Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529. ↩︎
Silver, David, et al. "Mastering the game of go without human knowledge." Nature 550.7676 (2017): 354. ↩︎
Bowling, Michael, et al. "Heads-up limit hold’em poker is solved." Science 347.6218 (2015): 145-149. ↩︎
Brown, Noam, and Tuomas Sandholm. "Safe and nested subgame solving for imperfect-information games." Advances in Neural Information Processing Systems. 2017. ↩︎



{kind=link}
{kind=link}
{kind=link}