
The unprecedented interest, investment, and deployment of machine learning across many aspects of our lives in the past decade has come with a cost. Although there has been some movement towards moderating machine learning where it has been genuinely harmful, it’s becoming increasingly clear that existing approaches suffer significant shortcomings. Nevertheless, there still exist new directions that hold potential for meaningfully addressing the harms of machine learning. In particular, new approaches to licensing the code and models that underlie these systems have the potential to create a meaningful impact on how they affect our world.
This is Part II of a two-part essay; Part I can be found here.
Open source software, freedom zero, and machine learning
Software is licensed in a fundamentally different way compared to other forms of intellectual property. Compare, for example, every Free/Open Source Software (FOSS) license to a relatively common open license used for artwork and other media: the Creative Commons Non-Commercial, or CC-NC license. Like other Creative Commons licenses, this license is supposed to “give everyone from individual creators to large institutions a standardized way to grant the public permission to use their creative work under copyright law.”
These standards are defined by the Free Software Definition and Open Source Definition, or FSD and OSD, respectively. Although there are some important variations between the two, both end up requiring a concept often referred to as “Freedom Zero”, or “The freedom to run the program as you wish, for any purpose” (the OSD phrases this as “no discrimination against field of endeavor”).
In a 2012 essay regarding the use of the CC-BY-NC(-SA) licenses, Richard Stallman, (founder of the GNU Project), justifies the difference as follows:
When a work is made for doing a practical job, the users must have control over the job, so they need to have control over the work. [...] In my view, nonfree licenses that permit sharing are ok for works of art/entertainment, or that present some party's viewpoint (such as this article itself). Those works aren't meant for doing a practical job, so the argument about the users' control does not apply.
In some ways, this view is taken even more to an extreme in Open Source, where permissive licenses don’t even leave a metaphorical fingerprint like the copyleft requirements for downstream contributors and users. In a 2016 essay, Nadia Eghbal quotes Karl Fogel, an early open source advocate:
In open source, you can only have “my” in the associative sense. There is no “my” in open source.
Practically, this is partially necessitated by the contribution structure of many open source projects. As projects grow in numbers of contributors, each one of them agrees to contribute under the project’s existing license. As a result, if each contributor attempted to add their own use restrictions, the project would almost certainly end up bogged down under the copyright restrictions of each individual. By defaulting to open use for users, this can largely be avoided.
While this is true for certain megaprojects like the Linux kernel, it’s far less applicable to many open source software projects, which often instead rely on one or few contributors to do the lion’s share of the work, both in terms of code contribution and overall management. To see this in machine learning, we can look to the FastAI library, a popular open source Python library (licensed under the permissive Apache 2.0) that wraps around PyTorch with an accompanying textbook. While FastAI doesn’t have as many contributors as the PyTorch (639 vs. 1811), the primary difference between the two is the stark drop-off in the actual code contributions among the top-listed contributors. Whereas in PyTorch, that group of top contributors has a relatively varied spread in terms of total additions and deletions, the FastAI group’s contributions drops off precipitously after even the first three.
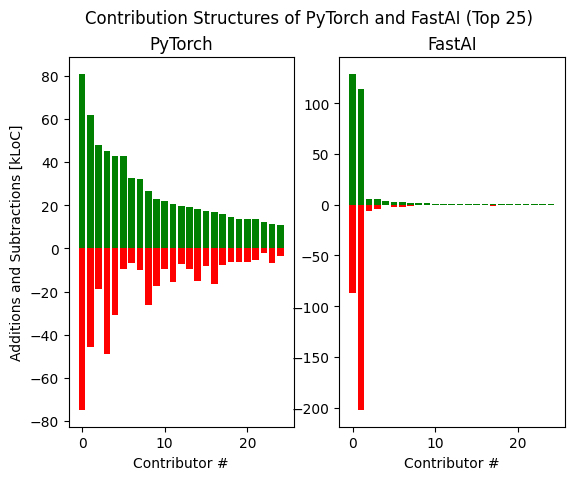
Figure 1: Contribution Structure of PyTorch and FastAI Libraries, January 2020 - April 2021
But this is not an isolated example; it’s a common feature in many open source repositories. In other words, many of projects end up functionally resembling the contribution structure of standard content, yet the standardization on FOSS licenses means that developers who want to share their work are left without the ability to strike a balance between openness and control that creators in other domains have.
In machine learning, the practical application cannot be separated from the code that is used to implement it. As a result, the way that software is licensed is fundamental to how we might consider both ownership and responsibility in machine learning. Permissive open source licensing prevents developers from even attempting to achieve downstream moderation of the way their work is used, because the licenses are deliberately written to uphold Freedom Zero and maintain the rights of the public to use that code for any purpose.
An alternative approach: custom software licensing for machine learning projects
However, a potential alternative approach has been quietly building momentum for some time now. In a discussion on the Codeberg platform, Florian Gilcher wrote
We have, over the last years, seen growing frustration from maintainers about their situation and abuse. This has led to a number of people to completely lock down their code - particularly people with low resources and privilege. I find that sad, but most importantly, it opened an interesting discussion space: the acceptance of Freedom Zero as an axiomatic rule is smaller than one might think.
Similarly, in a 2019 essay entitled The culture war at the heart of open source, Steve Klabnik, a prominent member of the Rust community, wrote
In the same way that the open source movement said “we’re like free software, but with these changes,” I think we’ll end up with a new movement. For the same reasons that “open source” came up with a new name, I think the movement that will arise from today’s developers will also need a new name. I’m not sure what that movement will look like, and I’ll explore why in another post. To give you a teaser: the problem is in the way that both Free Software and Open Source are formulated. The rot is in the roots, and I’m not yet sure what will replace it.
In the time since that was written, it’s become more clear what at least some parts of that new movement will look like: software licenses that apply some level of explicit enforcement on what the copyright owner views as proper use, while maintaining many of the procedural benefits of open code like open development and source code access.
There are several subcategories to these special software licenses. “Cloud protection licenses,” for example, attempt to restrict the ability of competitors (and by “competitors”, they usually mean Amazon) to take their company’s open code and offer it as a hosted service, directly competing with the organization who spends their resources developing the initial code. Another growing category falls under what is broadly being called “Ethical Source.” Ethical Source software focuses on reducing harm through various angles, which include respecting human rights, protection of privacy, fair compensation, and more. Some of the licenses in this vein represent some really interesting iterations on the idea of building accountability within the end user base of projects under an Ethical Source license. For example, the Hippocratic License seeks to tie alleged human rights abuses where HL-licensed code is used to a binding arbitration agreement, where either a refusal to engage in arbitration or losing the arbitration itself will result in loss of license after a 3-month grace period.
There’s also been exciting experimentation for machine learning specifically. The ml5.js Javascript library, developed by a group aiming to make machine learning accessible to a wider audience, has proposed a custom license tied to a stand-alone, evolving Code of Conduct document that is maintained by a committee which will act as a judgement board in cases of evaluating potential license violations. This approach offers some meaningful improvement, in terms of the ability to thoughtfully address grey areas in conduct by informed experts and the ability to adapt to new situations without necessarily requiring re-licensing. It does, however, require a trust in the community and the processes responsible for upholding the license’s spirit. Without it, there is an avenue to potential social engineering attacks on the license through the membership of this committee (to the group’s credit, when asked about it, they acknowledged this trade-off).
Also notable is the Responsible AI License (RAIL). Based on the very common permissive open source Apache 2.0 license, the RAIL for source code adds a section of “Restrictions” which requires that users of the library abide by a set of prohibitions against specific actions in the domains of surveillance, computer-generated media, health care, and criminal proceedings (e.g. “Detect or infer any legally protected class or aspect of any person, as defined by U.S. Federal Law”). There’s an accompanying End User License Agreement that incorporates these clauses into some additional user agreement boilerplate.
However, a number of these licenses fall into what I like to refer to as The “Good, Not Evil” Trap. This is a reference to an early attempt at an ethical license, called the JSON License which amended the permissive MIT License with the words “The Software shall be used for Good, not Evil.” (Interestingly, this is also an excellent example of how ethical licenses can force consideration even in the case of a power imbalance, when IBM felt compelled to ask the author of a Javascript code quality library for an exemption from this clause to use his library). Like the JSON License, licenses that fall into the “Good, Not Evil” trap suffer from being too broad, with potential ramifications ranging from the impossibility of fair adoption, even by well-meaning groups or individuals, to ultimately being unenforceable should the copyright owner attempt to take enforcement action against what they perceived as a violation. Rather, in order to be effective, licenses including ethical clauses need to be specifically focused and opinionated in order to avoid ambiguity and ease both compliance for users and enforcement by the copyright owner.
For example, there is growing evidence that convolutional neural networks can be critical parts of state-of-the-art malware detection systems. However, if a library for writing these neural networks was licensed under, for example, the Do No Harm License, this capability would be unavailable to organizations that “lobbies for, promotes, or derives a majority of income from actions that support or contribute to [...] nuclear energy [or] warfare.” One would have to imagine that this would probably apply to many organizations that work as defense or energy contractors, and to the military itself. To me, this feels like a problem--if there are any organizations where it is in the public interest to have superb malware detection, the ones operating nuclear reactors and maintaining a nuclear arsenal should probably be at the top of the list.
As a result, I see narrow-domain, generally permissive, purpose-specific prohibition licenses like the RAIL to be the most likely candidates for meaningful adoption: rather than posing a philosophical question to those looking to adopt them, licenses of this type offer a checklist instead.
This domain-specific approach, therefore, is much more enforceable; eventually, the measure of a license’s effectiveness will be determined by its ability to be upheld as valid in the adversarial context of a courtroom. In that situation, the ability of a copyright holder to clearly demonstrate violation of license terms is paramount, and where the narrowness and specificity of a claim works to the one’s benefit.
Notably, domain-specific licenses have already been recognized outside of machine learning. For example, the Cryptographic Autonomy License was created by Holochain in 2019 for use in their open source code to enforce some protections around the way that cryptographic keys are handled. It has even been reviewed and approved by the Open Source Initiative.
Domain-specific licensing for machine learning
This domain-specific approach is particularly promising for machine learning, in part because of several key areas where machine learning diverges heavily from other software.
1. The code vs the useful artifact
The (monetary) value of most software is inherent to the source code itself--even for large, important code bases like the Linux kernel, once you have access to the source code, it’s (relatively) trivial to move from the source to the valuable end product of a binary executable. Therefore, access to the original source (and granting freedoms around it) has taken primacy in licensing for most general-purpose software.
In machine learning, however, the source code is not necessarily the most important aspect of the system. Instead, the source only acts as a sort of framework around training for the correct weights, the actual valuable artifact.. And finding those weights can be enormously expensive; GPT-3, for example, was estimated to have cost around $4.6 million. Even smaller models like those commonly found in computer vision for object detection are very rarely trained from scratch. Instead, pre-trained versions of the most common architectures are downloaded and fine-tuned, which drastically reduces the overall cost in terms of time and compute hardware for end users. As a result, unlike most other software, the marginal cost of production for useful machine learning software is rarely close to zero.
Furthermore, the trained model’s copyright is not by default inherited from the license of the code that trained it. A good analogy for this might be the GNU Image Manipulation Program, or GIMP. This is a commonly used piece of free software for editing or creating images; the software itself is licensed under GPLv3. However, when an artist creates a piece of artwork using the program, they’re free to license that artwork under whatever they see fit--GIMP is only a tool used by the artist in the process.
2. The data
The data used to construct machine learning models creates similarly complex considerations for copyright. In a landmark decision in early 2021, the company Everalbum was required as part of a Federal Trade Commission settlement to delete not only data gathered from individuals without their consent, but also the models that were trained with that data. Although the Ever service eventually folded, this is something that organizations will have to account for in the future: not just how their models are being used, but also the provenance of the data that those models were trained on.
3. The deployment
Although there’s been advancement on both the hardware and software side of machine learning systems for deploying to smaller, low resource devices, most or all of the training and inference happen on dedicated remote servers--in the cloud. Models and the code that runs them are less likely to be shipped to users directly. The proliferation of cloud-native software, which by all indications is going to dominate real-world commercial machine learning applications, has meaningful implications. It was the driving factor in creating the Affero GPL license, which requires that source code for an application be made available to users even when they access it across the Internet (as opposed to on their own, local computer).
As a result, I believe any practical ethical license for machine learning needs to consider the cloud-native licensing implications as well, which licenses based on standard GPL or permissive Open Source ones don’t meaningfully address. That's not theoretical; for example, neither the RAIL nor Hippocratic License have language that addresses remote server use. Since that has become standard practice both for organization-internal systems and even publicly announced ones (for example, GPT-3 is not publicly available, only through an OpenAI private API waitlist), licensing requirements around network access is a key sticking point that machine learning in particular demands.
Additionally, there are practical concerns around the use of undisclosed machine learning systems behind APIs. For example, it was discussed in Part I that police departments are working around local facial recognition bans by using results given to them by sister agencies. One of the ways that this is enabled is by not asking if those results were generated by a machine learning program--there’s no requirement to represent that information as generated by a machine learning model, which limits the degree to which those systems can be held accountable.
Similar concerns will arise in other areas in the future, with technologies like chatbots. Many natural language generators are now somewhat capable of creating coherent, grammatically correct text, enabling applications of replacing actual human conversation. However, models don’t necessarily have the kind of context that a human usually does, and misrepresenting the output of a machine learning model as that of a human can have significant consequences in many fields from areas to news reporting to medical advice. Requirements around prominent disclosure, in a similar way that code must be made available, would help to reduce this risk and address a core challenge in addressing accountability of machine learning systems.
All of this means that for attempts to apply ethical restrictions to a machine learning library, the playbook that works for many other sorts of code are unlikely to succeed when simply applied to the this domain; instead, solutions targeted at addressing the unique problems posed towards open non-permissive licensing will be necessary in order to create a meaningful or lasting impact.
Conclusion
At its core, approaches to software licensing are all about trade-offs. There’s no doubt that a Free and Open Source approach to software has produced extraordinary returns, both in terms of utility and the ability for individuals to control their computing environments. It’s also an approach that dogmatically accepts the very real negative externalities of that code. The decision by many developers to accept that specific trade-off, whether implicit or consciously-decided, is a valid one. However, it’s not the only valid decision around that trade-off, and is clear that there are developers both in and outside of machine learning that are hoping to tweak that paradigm so that their software can be available for use by the community at large, except in ways that directly conflict with specific moral beliefs.
There can be little doubt that systems built using machine learning techniques are causing real harm. Especially in light of the proliferation of the technology due to open source libraries, relying on market systems to resolve and manage those harms is ineffective, and attempts to mitigate them through ethical codes of conduct and government regulation are falling short in many areas. A switch away from permissive open source licensing offers a potential solution by enabling developers to create clear boundaries within a system capable of enforcing them. It won’t be a catch-all, but it does offer the potential to be an additional tool for limiting the abuse of these tools, enabling developers and researchers to feel confident that their work will be used for a better tomorrow, and allowing machine learning to grow and mature ways that benefit everyone.
Part I of this essay can be found here.
Author Bio: Chris is an open source developer and contributor to the Rust-ML machine learning working group. He holds a B.S. in Mechanical Engineering and Physics from Northeastern University.
Note: The author has received partial funding from the U.S. Department of Defense for unrelated work.
Citation
For attribution in academic contexts or books, please cite this work as
Christopher Moran, "Machine Learning, Ethics, and Open Source Licensing (Part II/II)", The Gradient, 2021.
BibTeX citation:
@article{moranopensource22021,
author = {Moran, Christopher},
title = {Machine Learning, Ethics, and Open Source Licensing (Part II/II)},
journal = {The Gradient},
year = {2021},
howpublished = {thegradient.pub/machine-learning-ethics-and-open-source-licensing-2/},
}



){kind=link}
{kind=link}
{kind=link}
{kind=link}