
The next wave of AI will be powered by the democratization of data. Open-source frameworks such as TensorFlow and Pytorch have brought machine learning to a huge developer base, but most state-of-the-art models still rely on training datasets which are either wholly proprietary or prohibitively expensive to license [1]. As a result, the best automated speech recognition (ASR) models for converting speech audio into text are only available commercially, and are trained on data unavailable to the general public. Furthermore, only widely-spoken languages receive industry attention due to market incentives, limiting the availability of cutting-edge speech technology to English and a handful of other languages.
Over the last year, we at MLCommons.org set out to create public datasets to ease two pressing bottlenecks for open source speech recognition resources. The first is prohibitive licensing: Several free datasets do exist, but most of sufficient size and quality to make models truly shine are barred from commercial use. As a response, we created The People’s Speech, a massive English-language dataset of audio transcriptions of full sentences (see Sample 1). With over 30,000 hours of speech, this dataset is the largest and most diverse freely available English speech recognition corpus today. The second is that these datasets are heavily English-centric. We also present the Multilingual Spoken Words Corpus (MSWC): a 50-language, 6000-hour dataset of individual words (Sample 2 contains random examples of “hello” in multiple languages). Single-word transcriptions are useful for training keyword spotting (KWS) models, such as the ones used to activate Google Voice Assistant, Alexa, or Siri. This dataset provides a significant leap in diversity of available keyword spotting datasets. Together, these datasets greatly improve upon the depth (TPS) and breadth (MSWC) of speech recognition resources licensed for researchers and entrepreneurs to share and adapt.
These datasets target the emerging field of data-centric AI [2], a paradigm which shifts the focus of machine learning from better modelling to better data. Industry practitioners frequently observe that the same performance improvements achieved through hundreds of engineering-hours spent in model iteration can often be equaled or surpassed through a fraction of the time spent in collecting more representative data. We open-source the tools we used to build The People’s Speech and the Multilingual Spoken Words Corpus in order to empower others in constructing their own high quality speech recognition datasets.
The People’s Speech
The People’s Speech is the first large-scale, permissively licensed ASR dataset that includes diverse forms of speech (interviews, talks, sermons, etc.) and acoustic environments. That’s the one-line summary of what makes it great. To break it down, let’s go over what we believe are the most important attributes of a monolingual ASR dataset today.
- Permissive licensing: Significant legal uncertainty remains about whether copyright applies to AI training data [3]. Since the code to most state-of-the-art models is permissively licensed, it’s usually the data that sets legal limits. Public datasets are often licensed for academic purposes only. Companies can’t use that data to create new products or features that ultimately allow society to reap the benefits of cutting-edge tech. The People’s Speech is licensed for academic and commercial usage under CC-BY-SA (with a CC-BY subset; see Table 2 for the breakdown).
- Total audio duration: More hours of speech mean that models trained on this data will be exposed to a wider variety of expressions, intonations, and environments. Wider variety in the training data will make the model more robust to those variations.
- Diversity of speech: We speak differently depending on the context. We might be reading out loud, in conversation, praying, yelling, or talking to a toddler. Thus, a dataset that is representative of how we speak must include several different forms of speech. This attribute makes downstream systems applicable to a wider range of real-world scenarios.
- Diversity of acoustic environments: Noisy environments make it much harder to listen to and decipher what somebody’s saying. It’s something we humans have to deal with so our ASR systems should learn to deal with it too. If they can, they will be far more robust and users will come to trust them to work anytime, thereby driving adoption.
Table 1 summarizes where contemporary ASR datasets stand with respect to the attributes outlined above. The People’s Speech is unique in that it excels in all four attributes. Suitability for commercial use is extremely significant.
| Dataset | Commercial Use Allowed | Total Hours | Diversity of Speech | Controlled Acustic Environment |
|---|---|---|---|---|
| The People's Speech | Yes | 30,000 | Diverse Speech | No |
| Gigaspeech | No | 10,000 | Diverse Speech | Sometimes |
| Librispeech | Yes | 1,000 | Audiobooks | Yes |
| Common Voice (English) | Yes | 1,700 | Read Speech | Somewhat |
| MLS (English) | Yes | 32,000 | Audiobooks | Yes |
Building The People's Speech
Our audio and transcriptions come from The Internet Archive, a self-described “digital library of Internet sites and other cultural artifacts in digital form”. They keep a very wide variety of audio beyond just audiobooks, including movies, TV, local news, music, and historical documentaries (recall that we love variety!). Not only this, the curators request each uploader to provide the license of each particular piece of media, which is then indexed for fast lookup. In the Internet Archive, we found 52,500 hours of audio with transcripts which were suitable for commercial use. We also looked at Vimeo and YouTube, but we estimated the former had only a few thousand hours of transcribed audio with appropriate licenses, and the latter has a prohibitive end user license agreement clause against downloading even commercially-licensed data. The audio transcriptions in The Internet Archive (and almost anywhere) come in SubRip format, which looks like this:
Unfortunately, we cannot train directly on the contents of the audio and the transcript. First, modern speech recognition systems cannot train on more than about 15 seconds of audio without running out of memory. While we could ostensibly use the timestamps of the SubRip file to chunk up the audio into small segments, these timestamps, which are usually intended for closed captioning of videos, in practice do not align very precisely with when words are actually said. Therefore, we had to throw out these timestamps and align the raw text in the SubRip files to the corresponding audio on our own, a process called forced alignment.
Finding the timestamps of each word actually requires the usage of a pre-trained speech recognition system. The purpose of running the speech recognizer is to find when each word was said. This process is surprisingly hard using existing open-source tools. For example, we found that the DSAlign [4] forced alignment tool’s built-in CPU-based speech recognizer processed about 2 hours of audio in one hour of wallclock time. Given that we had to rerun the job multiple times as we tuned the pipeline, this wouldn’t work. Instead, we forked DSAlign to incorporate a GPU-accelerated speech recognizer built into kaldi [5], which can transcribe 250 hours of audio per one hour of wallclock time on one NVIDIA T4 GPU, though the number could increase greatly with tuning. Using just four T4 GPUs, we were able to timestamp our data in just 52.5 hours.
While forced alignment creates suitably chunked data for training, we discovered that many samples were lower quality than others. This is straightforward to measure via the character error rate between the pre-trained speech recognizer’s output and the ground truth transcripts. Several ground truth transcripts were translations to another language or non-verbal annotations (e.g., applause). Other fun pieces of data we found were an audio book created via speech synthesis, as well as Mandarin language audio to which a speech recognizer had been applied to create English “ground truth” transcripts. Needless to say, these had to be removed. We settled for providing a “clean” subset of about 20,000 hours, whose data had a less than 20% character error rate, and a “noisy” subset of about 10,000 hours, whose data had a character error rate between 20% and 38%. Everything else was thrown out. This is summarized in Table 2 below. Between removal of silence and removal of low quality transcripts, this is why our 52,500 hours of source files shrunk to 30,000 hours in the final dataset.
| Subset | CC-BY + Public Domain | CC-BY-SA | Total |
|---|---|---|---|
| Clean | 17,186h | 2,241h | 19,427h |
| Noisy | 10,515h | 898h | 11,413h |
| The People's Speech | 27,701h | 3,139h | 30,840h |
While this is not done in other large-scale speech recognition datasets, we did take time to investigate whether or not duplicate records existed in our dataset [6]. This is understudied today, but we think it should get more recognition for two reasons:
- Without deduplication of our source data, it is exceedingly possible for the same document to appear in both the test and training sets, which reduces the reliability of the test set. This is very bad for benchmarking.
- Duplication of training data is known to make generative language models worse [7]. While this may not be true for discriminative speech recognition models, it behooves the field of speech recognition to investigate this further.
For The People’s Speech, we used MinHash-based locality sensitive hashing of our ground truth transcripts to identify about 600 hours of source audio that were replicated in the dataset. We would have liked to apply this to the audio as well, e.g., to ensure that the same speaker does not appear in both the training and the testing sets, but that did not make the cut for the release of the dataset. Hashing of continuous data like audio (or embeddings of audio) is not straightforward compared to hashing of textual data.
As noted earlier, we do open source our dataset creation pipeline. This is worth calling out for a few reasons. One is that, as far as we know, we are the first to release publicly the exact code used to create a speech recognition dataset. We hope this starts a precedent, given past personal observations of some data in common benchmark datasets being incorrect. While this is to be expected, there is generally no mechanism for people to report that some part of a dataset is wrong and get it updated. To take an example, colleagues at NVIDIA have noted the benefit of cleaning existing dataset like Multilingual Librispeech (MLS) [8], but there is no easy way to get these fixes upstreamed given that MLS’s data creation pipeline is closed source. We don’t expect the first version of The People’s Speech to be the last. Secondly, data engineering pipelines are often not shared because they are deeply intertwined with proprietary systems inside of companies. Ours was developed as a workflow of Apache Spark jobs on top of Google Cloud. It should be straightforward for anyone familiar with cloud computing to reuse our work. Finally, real-world data engineering pipelines have long been outside the purview of performance optimization, because so few exist in public. It is conceivable that systems and high performance computing researchers can identify meaningful workloads to accelerate in these real-world pipelines.
Evaluating the Result
The output of the pipeline above is The People’s Speech. To gauge its usefulness, we decided to train a model on the data, and then assess its performance. The most common metric for this kind of model is the word error rate, a measure of how closely the speech recognizer’s output matches the ground truth transcript.
The model we trained on The People’s Speech, a variant of the Conformer [9], achieved a 9.98% word error rate on Librispeech’s [10] test-clean set: a dataset composed of audiobook transcriptions. It’s the go-to test set for speech recognition models. For reference, human transcriptionists score 5.83% [11]. The original conformer scored 1.9% [9], but it’s trained on Librispeech’s training set, which comes from essentially the same distribution as its test set. It’s hard to compare these results directly; our intention is actually to show that you can use TPS to train a model that falls within the ballpark of good speech-to-text models.
Multilingual Spoken Words Corpus
We now introduce our second dataset, the Multilingual Spoken Words Corpus, a large dataset of individual spoken words in 50 languages for voice interfaces. Voice-based interaction holds promise to democratize access to technology, but state-of-the-art solutions currently target only a handful of high-resource languages such as English. In particular, keyword spotting (KWS) has become ubiquitous for enabling voice interfaces on smartphones (such as Apple’s Siri and Google Voice Assistant) and smart devices (e.g., Amazon Alexa). Keyword spotters are lightweight wake-word machine learning models which can continuously run on low-cost, low-power microcontrollers in order to listen for one or more specific key phrases. State-of-the-art neural network models provide high classification accuracy sufficient for wide-scale deployment across a plethora of “smart” consumer-facing devices including phones, watches, speakers, and televisions [12].
However, voice interaction is not available worldwide. The aforementioned commercial deployments only support very small vocabularies in a limited number of languages. For example, as the Mozilla Foundation notes [13], there are no native African languages currently supported by the voice assistants from Amazon, Apple, or Google. This is due to the significant data requirements of keyword spotting models, which require tens of thousands to millions of training examples [14], precluding the ability to extend keyword spotting technology across the world, especially for under-represented languages.
Traditionally, these keyword datasets require enormous effort to collect and validate many thousands of utterances for each keyword of interest. Thus, much of the current academic KWS research relies on existing keyword datasets such as Google Speech Commands [15] and Hey Snips [16]. These datasets are usually monolingual and contain only a handful of keywords. Moreover, KWS must be robust to a wide range of speaker characteristics (e.g. accents, genders, tone, pitch and stress) and environmental settings. This presents an additional challenge in sourcing a corpus that is rich and diverse, and the lack of large multilingual datasets has prevented the proliferation of KWS technology to low-resource languages.
Our primary aim is to make voice interfaces available in all languages. We address this challenge by leveraging crowdsourced, general-purpose multilingual speech corpora in order to assemble keyword spotting datasets for under-resourced languages. We have developed and released the Multilingual Spoken Words Corpus (MSWC), a large and growing audio dataset of spoken words in 50 languages, with over 340,000 words and 23 million training examples, as a key step in achieving global reach for speech technology. For many languages, our corpus is the first available keyword dataset. Our dataset is licensed under CC-BY 4.0 and is free to use for academic research and commercial applications. Our ultimate objective is to make keyword spotting voice-based interfaces available for any keyword in any language.
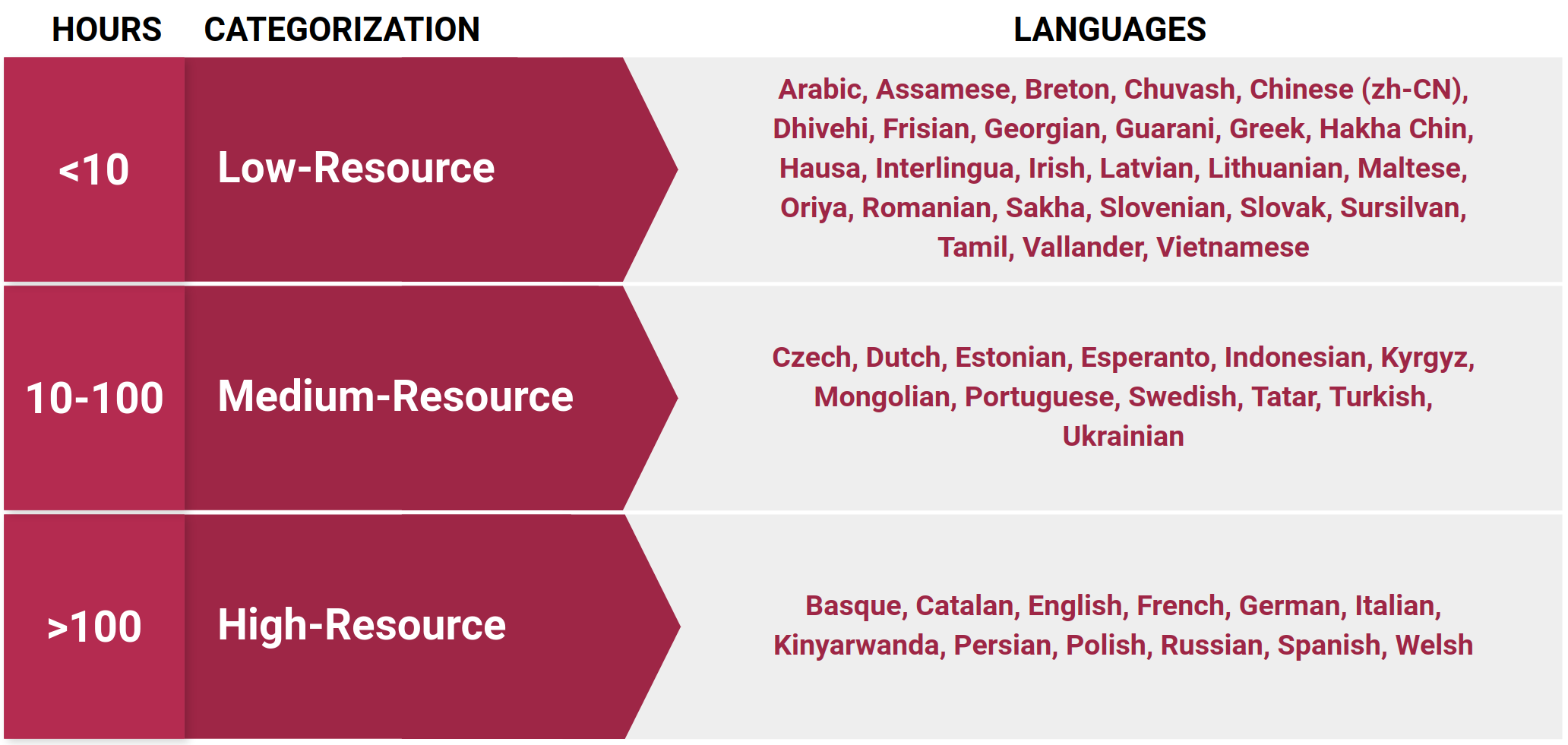
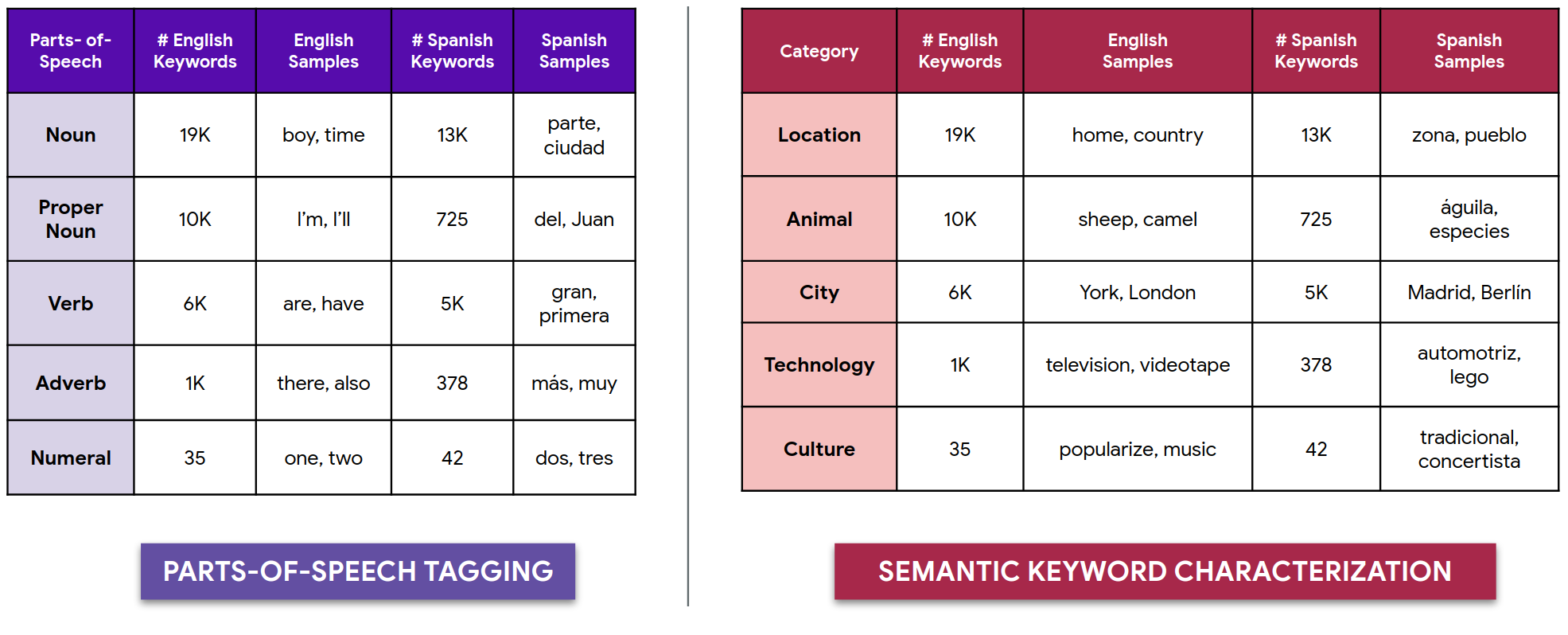
Our dataset contains over 6,000 hours of 1-second spoken word examples in 50 languages. As a gauge of potential reach, these 50 languages are estimated to be spoken by over 5 billion people worldwide [17]. We categorize each language in our dataset based on the number of hours present. For instance, we currently have over 100 hours of keyword data in each of the 12 languages categorized as high-resource in the figure above. On average, each low-resource language in our dataset has over 500 unique keywords and a total of 10,000 audio samples. For each high-resource language, we have on average over 23 thousand unique keywords available, and 1.8 million audio clips per language. We include open-source tools for exploring the types of keywords present in our dataset in multiple languages. We show random samples here in English and Spanish characterized by parts-of-speech and semantic classification [18], [19]. We also include predefined train, dev, and test splits for each keyword in our dataset, and we optimize for balanced genders and minimal speaker overlap between the train and test sets.
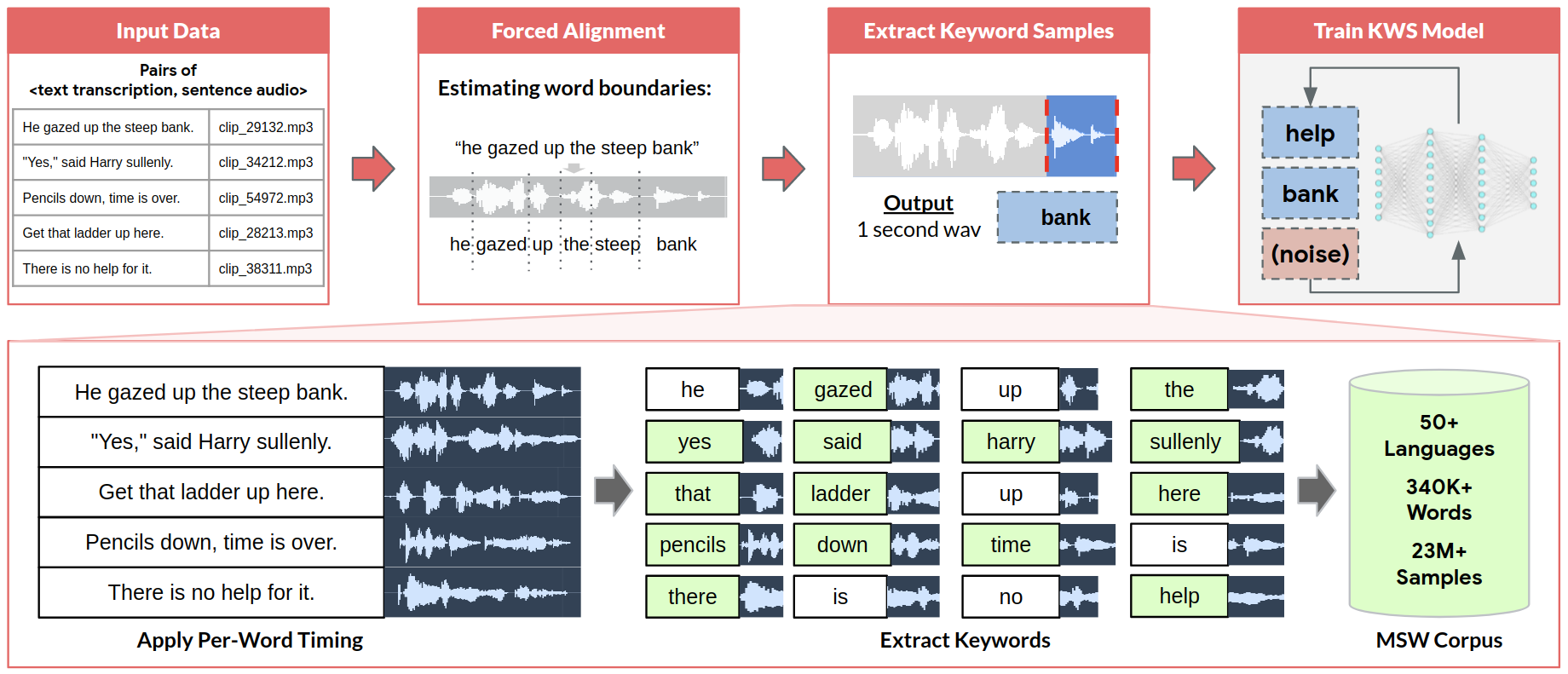
We construct our dataset on top of Common Voice [20], a massive crowdsourced speech resource. We extract individual keywords by applying forced alignment on Common Voice’s crowd-sourced sentence audio to produce per-word timing estimates for each word. Forced alignment is a well-established technique in speech processing to time-align recorded speech with a provided text transcription. We use the Montreal Forced Aligner [21] to produce alignments, and we include alignments for all of Common Voice in our dataset. We bootstrap our alignments directly by alternating training and aligning on the data in Common Voice (this procedure is a variant of Generalized Expectation Maximization), instead of using external acoustic or language models. We apply a minimum character length of three (two for Chinese) as a coarse stopword filter for our inclusion criteria - this avoids short words such as “a,” “of,” “an,” etc. which are challenging to estimate alignments for and provide limited use for keyword spotting. We also ensure a minimum of five audio clips per word. Our keyword extraction pipeline ingests pairs of sentence audio and text transcripts. Using the estimated per word timing boundaries from forced alignment, we apply our inclusion criteria and extract keywords into our dataset. These isolated keywords can then be used to train keyword spotting models.
Prior work [22], [23] has used forced alignment for keyword spotting research (primarily in English), but there are several potential sources of error in automated keyword extraction, such as transcript mismatches and incorrectly estimated word boundaries, which make it difficult to construct a dataset from the results of forced alignment extraction. Thus, we also provide a self-supervised nearest neighbor anomaly detection algorithm to automatically filter out erroneous samples using a distance metric. Evaluated on 75 keywords in English, Spanish, and German, we observe through manual listening tests that an average of 23.5% of the furthest 50 clips sorted by distance, are erroneous, whereas only 2.9% of the nearest 50 clips contain errors. Users of our dataset can tune their desired filtering threshold.
What’s the potential value of enabling keyword spotting in any language? The current generation of TinyML-capable microcontrollers [24], [25] provide cheap, low-power, always-on hardware support for keyword spotting. These microcontrollers often cost less than a dollar and can be powered for days, weeks, or even months on a small battery. Voice interfaces can thus potentially be added to any device, with the potential to enable broader access to technology for visually impaired, physically impaired, and illiterate or semi-literate users in communities across the world.
Additionally, in collaboration with Makerere University, we are currently using our dataset to develop tools which will aid with COVID-19 response through monitoring Ugandan public radio broadcasts for COVID-19 keywords in low-resource languages such as Luganda. Tools for automated radio monitoring of spoken terms can help healthcare providers and organizations such as the United Nations find relevant community discussions to aid in decision support [26]. Public sentiment can aid in understanding the impact and reach of public health interventions—in particular, radio call-in shows often reflect public sentiment in areas where internet connectivity is sparse and where online social media is infrequently or not used. We are applying our dataset towards training a multilingual keyword feature extraction model [27], which in turn allows us to search for keywords in Luganda with only a few seconds of training data as opposed to thousands of examples.
Conclusion and Future Work
The mission of MLCommons™ is to accelerate machine learning innovation and increase its positive impact on society. Our contribution to that end is twofold: On the one hand, The People’s Speech and the Multilingual Spoken Words Corpus put much needed data in the hands of engineers and researchers around the world, who will drive that impact. And on the other, we are releasing the software pipelines that constructed each dataset. Time and again, we’ve seen the power of open-source software to drive innovation.
- The People’s Speech codebase is available here.
- The Multilingual Spoken Words Corpus codebase is available here.
So, what’s next? The People’s Speech opens a path to many research and business applications in English. We’re keen on opening that path in other languages. One key challenge we expect to face is the lack of appropriately licensed audio with transcriptions in other languages. Our hunch is that self-supervised training of audio representations [28] could play a big part in enabling ASR in low-resource languages, which would make collecting transcription-less audio worthwhile. As for the Multilingual Spoken Words Corpus, MLCommons will continue to update and expand the dataset. MSWC will grow to include more languages and more words per language, to contain alignments for new versions of Common Voice and eventually to include new sources of speech data beyond Common Voice.
We’ll end this piece by inviting you to check out our datasets (The People's Speech and the Multilingual Spoken Words Corpus) and our pipelines, make someone’s life better with them, or simply make something cool. Also be sure to reach out to us at [email protected] if you have questions, or if you have ideas for improving and extending our datasets.
References
[1] V. J. Reddi, G. Diamos, P. Warden, P. Mattson, and D. Kanter, “Data Engineering for Everyone,” ArXiv210211447 Cs, Feb. 2021, Accessed: Nov. 23, 2021. [Online]. Available: http://arxiv.org/abs/2102.11447
[2] Ng, Andrew, “AI Doesn’t Have to Be Too Complicated or Expensive for Your Business,” Harvard Business Review, Jul. 29, 2021. [Online]. Available: https://hbr.org/2021/07/ai-doesnt-have-to-be-too-complicated-or-expensive-for-your-business
[3] B. Vézina and S. Hinchliff Pearson, “Should CC-Licensed Content be Used to Train AI? It Depends,” Creative Commons, Mar. 04, 2021. https://creativecommons.org/2021/03/04/should-cc-licensed-content-be-used-to-train-ai-it-depends/ (accessed Nov. 23, 2021).
[4] DSAlign. Mozilla. [Online]. Available: https://github.com/mozilla/DSAlign
[5] H. Braun, J. Luitjens, R. Leary, T. Kaldewey, and D. Povey, “GPU-Accelerated Viterbi Exact Lattice Decoder for Batched Online and Offline Speech Recognition,” ArXiv191010032 Cs Eess, Feb. 2020, Accessed: Nov. 24, 2021. [Online]. Available: http://arxiv.org/abs/1910.10032
[6] D. Haasler et al., “First extragalactic detection of a phosphorus-bearing molecule with ALCHEMI: phosphorus nitride (PN),” ArXiv211204849 Astro-Ph, Dec. 2021, Accessed: Dec. 10, 2021. [Online]. Available: http://arxiv.org/abs/2112.04849
[7] K. Lee et al., “Deduplicating Training Data Makes Language Models Better,” ArXiv210706499 Cs, Jul. 2021, Accessed: Nov. 24, 2021. [Online]. Available: http://arxiv.org/abs/2107.06499
[8] E. Bakhturina, V. Lavrukhin, and B. Ginsburg, “NeMo Toolbox for Speech Dataset Construction,” ArXiv210404896 Cs Eess, Apr. 2021, Accessed: Nov. 24, 2021. [Online]. Available: http://arxiv.org/abs/2104.04896
[9] A. Gulati et al., “Conformer: Convolution-augmented Transformer for Speech Recognition,” ArXiv200508100 Cs Eess, May 2020, Accessed: Nov. 23, 2021. [Online]. Available: http://arxiv.org/abs/2005.08100
[10] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Queensland, Australia, Apr. 2015, pp. 5206–5210. doi: 10.1109/ICASSP.2015.7178964.
[11] D. Amodei et al., “Deep Speech 2: End-to-End Speech Recognition in English and Mandarin,” ArXiv151202595 Cs, Dec. 2015, Accessed: Nov. 24, 2021. [Online]. Available: http://arxiv.org/abs/1512.02595
[12] Y. Zhang, N. Suda, L. Lai, and V. Chandra, “Hello Edge: Keyword Spotting on Microcontrollers,” ArXiv171107128 Cs Eess, Feb. 2018, Accessed: Nov. 23, 2021. [Online]. Available: http://arxiv.org/abs/1711.07128
[13] Mozilla, “Mozilla Common Voice Receives $3.4 Million Investment to Democratize and Diversify Voice Tech in East Africa,” Mozilla Foundation, May 25, 2021. https://foundation.mozilla.org/en/blog/mozilla-common-voice-receives-34-million-investment-to-democratize-and-diversify-voice-tech-in-east-africa/ (accessed Nov. 23, 2021).
[14] R. Alvarez and H.-J. Park, “End-to-end Streaming Keyword Spotting,” 2019 IEEE Int. Conf. Acoust. Speech Signal Process. ICASSP, 2019, doi: 10.1109/ICASSP.2019.8683557.
[15] P. Warden, “Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition,” ArXiv180403209 Cs, Apr. 2018, Accessed: Nov. 23, 2021. [Online]. Available: http://arxiv.org/abs/1804.03209
[16] A. Coucke, M. Chlieh, T. Gisselbrecht, D. Leroy, M. Poumeyrol, and T. Lavril, “Efficient keyword spotting using dilated convolutions and gating,” ArXiv181107684 Cs Eess Stat, Feb. 2019, Accessed: Nov. 23, 2021. [Online]. Available: http://arxiv.org/abs/1811.07684
[17] D. Eberhard and G. F. Simons, “Ethnologue: Languages of the World. Twenty-fourth edition.,” Dallas, Texas: SIL International, 2021. [Online]. Available: http://www.ethnologue.com
[18] K. Toutanova, D. Klein, C. D. Manning, and Y. Singer, “Feature-rich part-of-speech tagging with a cyclic dependency network,” in Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology - NAACL ’03, Edmonton, Canada, 2003, vol. 1, pp. 173–180. doi: 10.3115/1073445.1073478.
[19] A. Conneau et al., “Unsupervised Cross-lingual Representation Learning at Scale,” ArXiv191102116 Cs, Apr. 2020, Accessed: Dec. 13, 2021. [Online]. Available: http://arxiv.org/abs/1911.02116
[20] R. Ardila et al., “Common Voice: A Massively-Multilingual Speech Corpus,” ArXiv191206670 Cs, Mar. 2020, Accessed: Dec. 10, 2021. [Online]. Available: http://arxiv.org/abs/1912.06670
[21] M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Sonderegger, “Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi,” Interspeech, 2017.
[22] J. Huang, W. Gharbieh, H. S. Shim, and E. Kim, “Query-by-Example Keyword Spotting system using Multi-head Attention and Softtriple Loss,” ArXiv210207061 Cs, May 2021, Accessed: Dec. 13, 2021. [Online]. Available: http://arxiv.org/abs/2102.07061
[23] A. Awasthi, K. Kilgour, and H. Rom, “Teaching keyword spotters to spot new keywords with limited examples,” ArXiv210602443 Cs Eess, Jun. 2021, Accessed: Dec. 13, 2021. [Online]. Available: http://arxiv.org/abs/2106.02443
[24] R. David et al., “TensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems,” ArXiv201008678 Cs, Mar. 2021, Accessed: Dec. 10, 2021. [Online]. Available: http://arxiv.org/abs/2010.08678
[25] C. Banbury et al., “Micronets: Neural network architectures for deploying tinyml applications on commodity microcontrollers,” Proc. Mach. Learn. Syst., 2021.
[26] R. Menon, H. Kamper, E. van der Westhuizen, J. Quinn, and T. Niesler, “Feature exploration for almost zero-resource ASR-free keyword spotting using a multilingual bottleneck extractor and correspondence autoencoders,” ArXiv181108284 Cs Eess Stat, Jul. 2019, Accessed: Dec. 10, 2021. [Online]. Available: http://arxiv.org/abs/1811.08284
[27] M. Mazumder, C. Banbury, J. Meyer, P. Warden, and V. J. Reddi, “Few-Shot Keyword Spotting in Any Language,” in Interspeech 2021, Aug. 2021, pp. 4214–4218. doi: 10.21437/Interspeech.2021-1966.
[28] A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations,” ArXiv200611477 Cs Eess, Oct. 2020, Accessed: Nov. 23, 2021. [Online]. Available: http://arxiv.org/abs/2006.11477
Author Bios
Mark Mazumder is a PhD student at Harvard University in the Edge Computing Lab, advised by Vijay Janapa Reddi. His research interests are in efficient machine learning techniques for small datasets. Prior to joining Harvard, Mark was an Associate Staff member at MIT Lincoln Laboratory, where his research spanned computer vision, robotics, and communications.
Daniel Galvez is a AI developer technology engineer at NVIDIA, where he focuses on accelerating speech recognition and machine learning workloads. He previously worked on the Kaldi Speech Recognition System in school, content recommendation systems at LinkedIn, and hardware-software co-design at Cerebras Systems. He holds a BS in Computer Science from Cornell University.
Juan Felipe Cerón is a Machine Learning Engineer at Factored. His recent work includes training speech recognition models alongside MLCommons and training language models to give good advice. He is commited to using his career to improving the wellbeing of people, animals, and beyond.
Daniel Galvez, Juan Felipe Cerón and Mark Mazumder are co-equal authors.
Citation
For attribution in academic contexts or books, please cite this work as
Juan Felipe Cerón, Mark Mazumder and Daniel Galvez, "New Datasets to Democratize Speech Recognition Technology", The Gradient, 2021.
BibTeX citation:
@article{cerón2021new,
author = {Cerón, Juan Felipe, Mazumder, Mark and Galvez, Daniel},
title = {New Datasets to Democratize Speech Recognition Technology},
journal = {The Gradient},
year = {2021},
howpublished = {\url{https://thegradient.pub/new-datasets-to-democratize-speech-recognition-technology/} },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.



{kind=link}
{kind=link}
{kind=link}
{kind=link}