
Artificial Intelligence has been experiencing a renaissance in the past decade, driven by technological advances and open sourced datasets. Much of this advancement has focused on areas like Computer Vision and Natural Language Processing (NLP). ImageNet made a corpus of 20,000 images with content labels publicly available in 2010. Google released the Trillion Word Corpus in 2006 along with the n-gram frequencies from a huge number of public webpages. The resulting evolution in NLP has led to massive improvements in the quality of machine translation, rapid expansion in uptake of digital assistants and statements like “AI is the new electricity” and “AI will replace doctors”.
Advancements in NLP have also been made easily accessible by organizations like the Allen Institute, Hugging Face, and Explosion releasing open source libraries and models pre-trained on large language corpora. Recently, NLP technology facilitated access and synthesis of COVID-19 research with the release of a public, annotated research dataset and the creation of public response resources.
However, the field of AI has been here before. In 1950, Alan Turing posited the idea of the “thinking machine”, which reflected research at the time into the capabilities of algorithms to solve problems originally thought too complex for automation (e.g. translation). In the following decade, funding and excitement flowed into this type of research, leading to advancements in translation and object recognition and classification. By 1954, sophisticated mechanical dictionaries were able to perform sensible word and phrase-based translation. In constrained circumstances, computers could recognize and parse morse code. However, by the end of the 1960s, it was clear these constrained examples were of limited practical use. A paper by mathematician James Lighthill in 1973 called out AI researchers for being unable to deal with the “combinatorial explosion” of factors when applying their systems to real-world problems. Criticism built, funding dried up and AI entered into its first “winter” where development largely stagnated.
The past few decades, however, have seen a resurgence in interest and technological leaps. Much of the recent excitement in NLP has revolved around transformer-based architectures, which dominate task leaderboards. However, the question of practical applications is still worth asking as there’s some concern about what these models are really learning. A study in 2019 used BERT to address the particularly difficult challenge of argument comprehension, where the model has to determine whether a claim is valid based on a set of facts. BERT achieved state-of-the-art performance, but on further examination it was found that the model was exploiting particular clues in the language that had nothing to do with the argument’s “reasoning”.
Due to the authors’ diligence, they were able to catch the issue in the system before it went out into the world. But often this is not the case and an AI system will be released having learned patterns it shouldn’t have. One major example is the COMPAS algorithm, which was being used in Florida to determine whether a criminal offender would reoffend. A 2016 ProPublica investigation found that black defendants were predicted 77% more likely to commit violent crime than white defendants. Even more concerning is that 48% of white defendants who did reoffend had been labeled low risk by the algorithm, versus 28% of black defendants. Since the algorithm is proprietary, there is limited transparency into what cues might have been exploited by it. But since these differences by race are so stark, it suggests the algorithm is using race in a way that is both detrimental to its own performance and the justice system more generally.

This type of high-profile failure in AI is not uncommon. Amazon recently scrapped an AI hiring algorithm after finding it was more likely to recommend males for technical roles, likely exploiting historical hiring patterns. Top-of-the-line machine translation has generally been found to struggle with gender and with under-resourced languages.
There’s a number of possible explanations for the shortcomings of modern NLP. In this article, I will focus on issues in representation; who and what is being represented in data and development of NLP models, and how unequal representation leads to unequal allocation of the benefits of NLP technology.
Bigger is not always better
Generally, machine learning models, particularly deep learning models, do better with more data. Halevy et. al. (2009) explain that simple models trained on large datasets did better on translation tasks than more complex probabilistic models that were fit to smaller datasets. Sun et. al. (2017) revisited the idea of the scalability of machine learning in 2017, showing that performance on vision tasks increased logarithmically with the amount of examples provided.
AI practitioners have taken this principle to heart, particularly in NLP. The advent of self-supervised objectives like BERT’s Masked Language Model, where models learn to predict words based on their context, has essentially made all of the internet available for model training. The original BERT model in 2019 was trained on 16 GB of text data, while more recent models like GPT-3 (2020) were trained on 570 GB of data (filtered from the 45 TB CommonCrawl). Bender et. al. (2021) refer to the adage “there’s no data like more data” as the driving idea behind the growth in model size. But their article calls into question what perspectives are being baked into these large datasets.
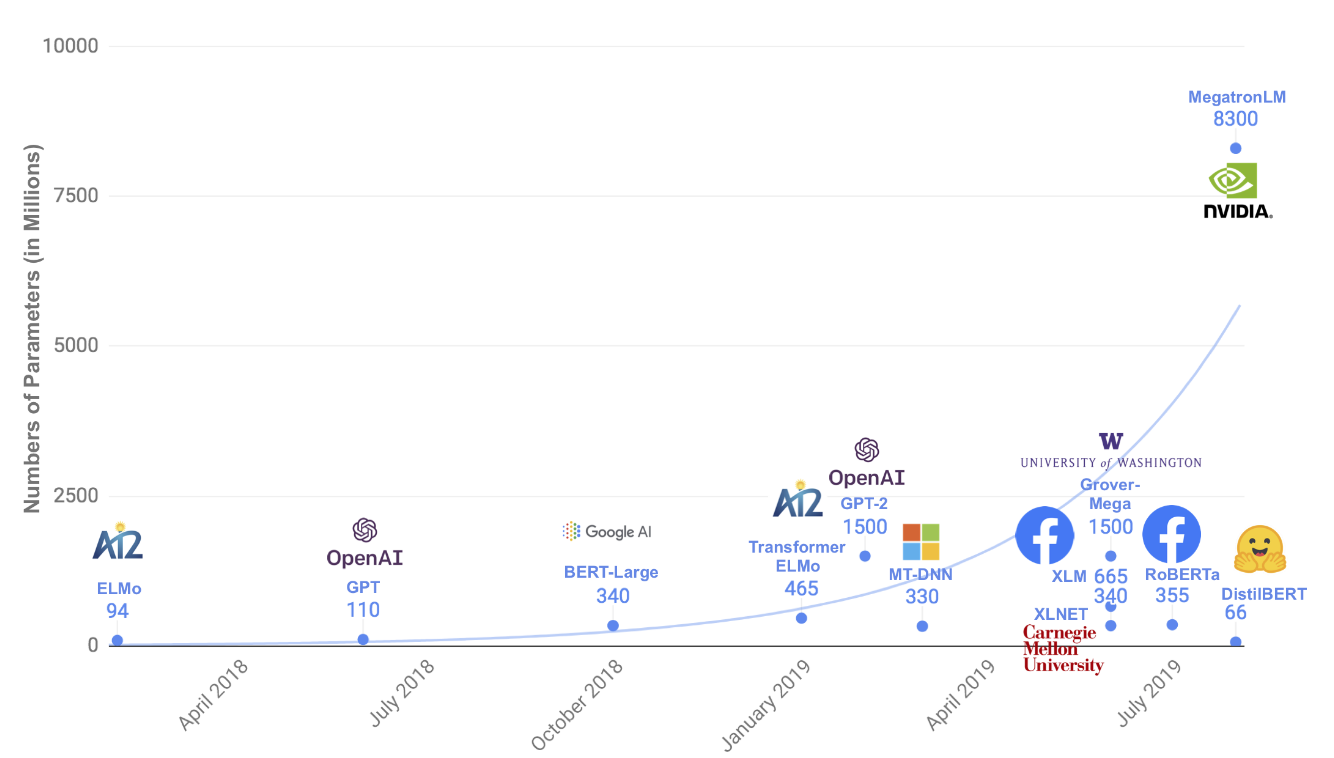
Wikipedia serves as a source for BERT, GPT and many other language models. But Wikipedia’s own research finds issues with the perspectives being represented by its editors. Roughly 90% of article editors are male and tend to be white, formally educated, and from developed nations. This likely has an impact on Wikipedia's content, since 41% of all biographies nominated for deletion are about women, even though only 17% of all biographies are about women.
Another major source for NLP models is Google News, including the original word2vec algorithm. But newsrooms historically have been dominated by white men, a pattern that hasn’t changed much in the past decade. The fact that this disparity was greater in previous decades means that the representation problem is only going to be worse as models consume older news datasets.
Additionally, internet users tend to skew younger, higher-income and white. CommonCrawl, one of the sources for the GPT models, uses data from Reddit, which has 67% of its users identifying as male, 70% as white. Bender et. al. (2021) point out that models like GPT-2 have inclusion/exclusion methodologies that may remove language representing particular communities (e.g. LGBTQ through exclusion of potentially offensive words).
Much of the current state of the art performance in NLP requires large datasets and this data hunger has pushed concerns about the perspectives represented in the data to the side. It’s clear from the evidence above, however, that these data sources are not “neutral”; they amplify the voices of those who have historically had dominant positions in society.
But even flawed data sources are not available equally for model development. The vast majority of labeled and unlabeled data exists in just 7 languages, representing roughly 1/3 of all speakers. This puts state of the art performance out of reach for the other 2/3rds of the world. In an attempt to bridge this gap, NLP researchers have explored using BERT models pre-trained on a high-resource language with low-resource fine-tuning (referred to usually as Multi-BERT) and using “adapters” to transfer learnings across languages. However, in general these cross-language approaches perform worse than their mono-lingual counterparts.
The fact that it’s difficult for these models to generalize across languages may point to a bigger problem than just one of representation. Joshi et. al. (2021) explain it this way:
“The handful of languages on which NLP systems are trained and tested are often related...leading to a typological echo-chamber. As a result, a vast majority of typologically diverse linguistic phenomena are never seen by our NLP systems.”

As discussed above, these systems are very good at exploiting cues in language. Therefore, it is likely that these methods are exploiting a specific set of linguistic patterns, which is why the performance breaks down when they are applied to lower-resource languages.
Garbage in, garbage out
Above, I described how modern NLP datasets and models represent a particular set of perspectives, which tend to be white, male and English-speaking. But every dataset must contend with issues of its provenance. ImageNet’s 2019 update removed 600k images in an attempt to address issues of representation imbalance. But this adjustment was not just for the sake of statistical robustness, but in response to models showing a tendency to apply sexist or racist labels to women and people of color.
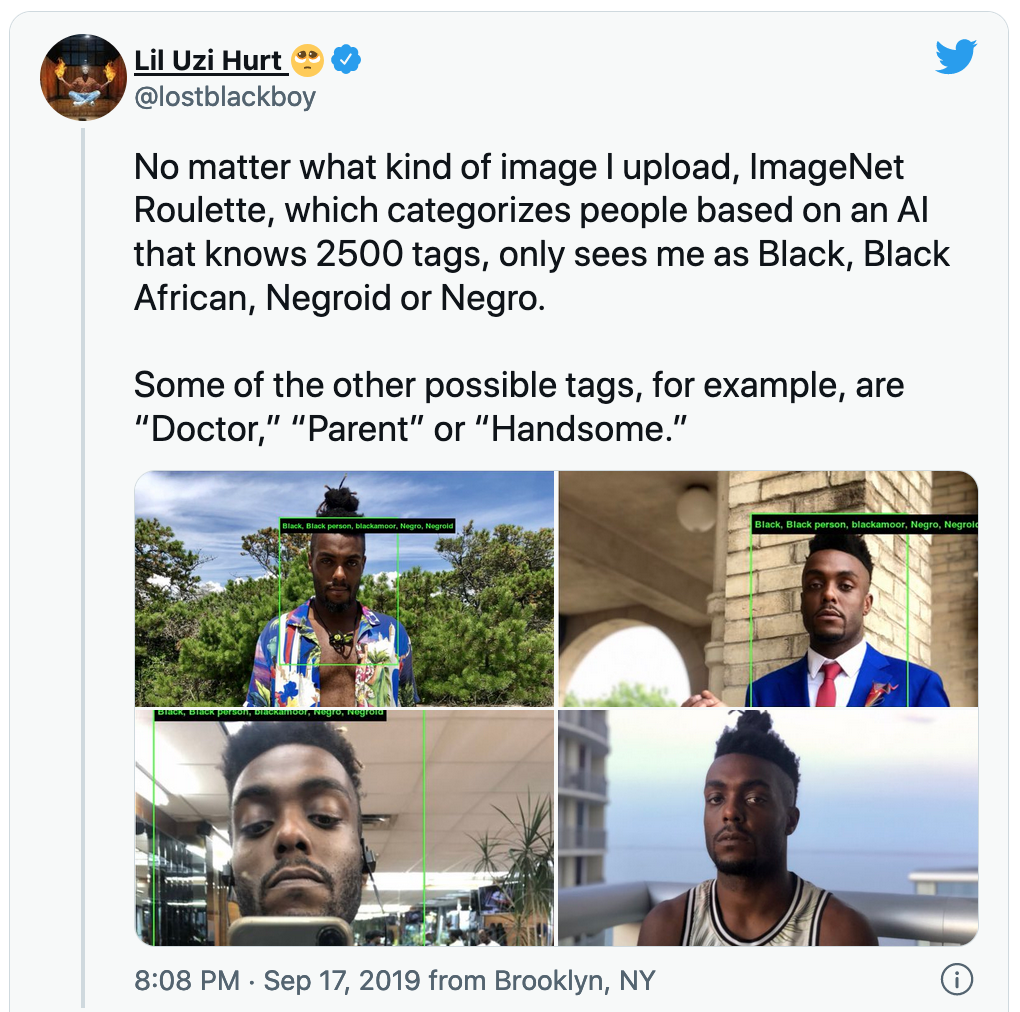
All models make mistakes, so it is always a risk-benefit trade-off when determining whether to implement one. To facilitate this risk-benefit evaluation, one can use existing leaderboard performance metrics (e.g. accuracy), which should capture the frequency of “mistakes”. But what is largely missing from leaderboards is how these mistakes are distributed. If the model performs worse on one group than another, that means that implementing the model may benefit one group at the expense of another.
I’ll refer to this unequal risk-benefit distribution as “bias”. Statistical bias is defined as how the “expected value of the results differs from the true underlying quantitative parameter being estimated”. There are many types of bias in machine learning, but I’ll mostly be talking in terms of “historical” and “representation” bias. Historical bias is where already existing bias and socio-technical issues in the world are represented in data. For example, a model trained on ImageNet that outputs racist or sexist labels is reproducing the racism and sexism on which it has been trained. Representation bias results from the way we define and sample from a population. Because our training data come from the perspective of a particular group, we can expect that models will represent this group’s perspective.
One well-studied example of bias in NLP appears in popular word embedding models word2vec and GloVe. These models form the basis of many downstream tasks, providing representations of words that contain both syntactic and semantic information. They are both based on self-supervised techniques; representing words based on their context. If these representations reflect the true “meaning” of the word, we’d imagine that words related to occupation (e.g. “engineer” or “housekeeper”) should be gender and race neutral, since occupations are not exclusive to particular populations.
However, Garg et. al. (2019) found occupation word representations are not gender or race neutral. Occupations like “housekeeper” are more similar to female gender words (e.g. “she”, “her”) than male gender words while embeddings for occupations like “engineer” are more similar to male gender words. These issues also extend to race, where terms related to Hispanic ethnicity are more similar to occupations like “housekeeper” and words for Asians are more similar to occupations like “Professor” or “Chemist”.

These issues are also present in large language models. Zhao et. al. (2019) showed that ELMo embeddings include gender information into occupation terms and that that gender information is better encoded for males versus females. Sheng et. al. (2019) showed that using GPT-2 to complete sentences that had demographic information (i.e. gender, race or sexual orientation) showed bias against typically marginalized groups (i.e. women, black people and homosexuals).

The word embedding models, ELMo and GPT-2 are all trained on different sets of data derived from internet sources. As described above, the perspectives represented on the internet tend to come from those who have historically been advantaged and granted more media attention. It’s likely that these perspectives are at the root of these problems, since the models have internalized this biased set of perspectives. As Ruha Benjamin puts it in his book Race After Technology (repeated in Bender et. al (2021)): “Feeding AI systems on the world’s beauty, ugliness, and cruelty, but expecting it to reflect only the beauty is a fantasy”.
Not only do these NLP models reproduce the perspective of advantaged groups on which they have been trained, technology built on these models stands to reinforce the advantage of these groups. As described above, only a subset of languages have data resources required for developing useful NLP technology like machine translation. But even within those high-resource languages, technology like translation and speech recognition tends to do poorly with those with non-standard accents.
For example, Koenecke et. al. (2020) found that the speech recognition software by companies like Amazon and Google have almost twice the error rate with African American speakers compared with white speakers. This can cause inconvenience by making Google Assistant or Alexa less useful for users with non-standard accents. Or it can cause major impacts on one’s life as with migrant workers struggling to communicate with border control. As might be expected from the biases represented in training data, the performance of these applications benefits groups that have a data “advantage” over other groups.
Aside from translation and interpretation, one popular NLP use-case is content moderation/curation. It’s difficult to find an NLP course that does not include at least one exercise involving spam detection. But in the real world, content moderation means determining what type of speech is “acceptable”. Moderation algorithms at Facebook and Twitter were found to be up to twice as likely to flag content from African American users as white users. One African American Facebook user was suspended for posting a quote from the show “Dear White People”, while her white friends received no punishment for posting that same quote.
From the above examples, we can see that the uneven representation in training and development have uneven consequences. These consequences fall more heavily on populations that have historically received fewer of the benefits of new technology (i.e. women and people of color). In this way, we see that unless substantial changes are made to the development and deployment of NLP technology, not only will it not bring about positive change in the world, it will reinforce existing systems of inequality.
Course correction
I mentioned earlier in this article that the field of AI has experienced the current level of hype previously. In the 1950s, Industry and government had high hopes for what was possible with this new, exciting technology. But when the actual applications began to fall short of the promises, a “winter” ensued, where the field received little attention and less funding. Though the modern era benefits from free, widely available datasets and enormous processing power, it’s difficult to see how AI can deliver on its promises this time if it remains focused on a narrow subset of the global population.
For NLP, this need for inclusivity is all the more pressing, since most applications are focused on just seven of the most popular languages. To that end, experts have begun to call for greater focus on low-resource languages. Sebastian Ruder at DeepMind put out a call in 2020, pointing out that “Technology cannot be accessible if it is only available for English speakers with a standard accent”. The Association for Computational Linguistics (ACL) also recently announced a theme track on language diversity for their 2022 conference.
Inclusiveness, however, should not be treated as solely a problem of data acquisition. In 2006, Microsoft released a version of Windows in the language of the indigenous Mapuche people of Chile. However, this effort was undertaken without the involvement or consent of the Mapuche. Far from feeling “included” by Microsoft’s initiative, the Mapuche sued Microsoft for unsanctioned use of their language. Addressing gaps in the coverage of NLP technology requires engaging with under-represented groups. These groups are already part of the NLP community, and have kicked off their own initiatives to broaden the utility of NLP technologies. Initiatives like these are opportunities to not only apply NLP technologies on more diverse sets of data, but also engage with native speakers on the development of the technology.
As I referenced before, current NLP metrics for determining what is “state of the art” are useful to estimate how many mistakes a model is likely to make. They do not, however, measure whether these mistakes are unequally distributed across populations (i.e. whether they are biased). Responding to this, MIT researchers have released StereoSet, a dataset for measuring bias in language models across several dimensions. The result is a set of measures of the model’s general performance and its tendency to prefer stereotypical associations, which lends itself easily to the “leaderboard” framework. A more process-oriented approach has been proposed by DrivenData in the form of its Deon ethics checklist.
However, we’re still dealing with some major issues that have always afflicted technology: advancements tend to benefit the powerful and reinforce existing divisions. If NLP technology is going to be something revolutionary, it will need to be better and different. Bender et. al. (2021) suggest a more “value sensitive design”, where research is designed in a way that monitors which perspectives are being included, which are excluded, and the risk-benefit calculation of that mixture. “Success” then is not a matter of accuracy scores, but whether the technology is advancing stakeholder values.
This is a really powerful suggestion, but it means that if an initiative is not likely to promote progress on key values, it may not be worth pursuing. Paullada et. al. (2020) makes the point that “[s]imply because a mapping can be learned does not mean it is meaningful”. In one of the examples above, an algorithm was used to determine whether a criminal offender was likely to re-offend. The reported performance of the algorithm was high in terms of AUC score, but what did it learn? As discussed above, models are the product of their training data, so it is likely to reproduce any bias that already exists in the justice system. This calls into question the value of this particular algorithm, but also the use of algorithms for sentencing generally. One can see how a “value sensitive design” may lead to a very different approach.
Recent advancements in NLP have been truly astonishing thanks to the researchers, developers, and the open source community at large. From translation, to voice assistants, to the synthesis of research on viruses like COVID-19, NLP has radically altered the technology we use. But to achieve further advancements, it will not only require the work of the entire NLP community, but also that of cross-functional groups and disciplines. Rather than pursuing marginal gains on metrics, we should target true “transformative” change, which means understanding who is being left behind and including their values in the conversation.
Author Bio
Ben Batorsky is a Senior Data Scientist at the Institute for Experiential AI at Northeastern University. He has worked on data science and NLP projects across government, academia, and the private sector and spoken at data science conferences on theory and application. His prior work is available at his website and his GitHub.
Citation
For attribution in academic contexts or books, please cite this work as
Benjamin Batorsky, "New technology, old problems: The missing voices in Natural Language Processing", The Gradient, 2022.
BibTeX citation:
@article{batorsky2022NLP,
author = {Batorsky, Benjamin},
title = {New Technology, Old Problems: The Missing Voices in Natural Language Processing},
journal = {The Gradient},
year = {2022},
howpublished = {\url{https://thegradient.pub/nlp-new-old } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.




{kind=link}
{kind=link}
{kind=link}
{kind=link}