
The development of Large Language Models, or LLMs, has led to a paradigm shift in NLP: trained on copious amounts of text drawn from the Internet, LLMs can learn in context to do new tasks. This means that instead of training the model to perform a task with parameter updates, NLP practitioners write prompts for the LLM that demonstrate desired behavior with instructions or a few completed examples. These prompts are passed into the model as an input context (hence, in-context learning), and the model uses the information in the prompt to answer similar questions [1].
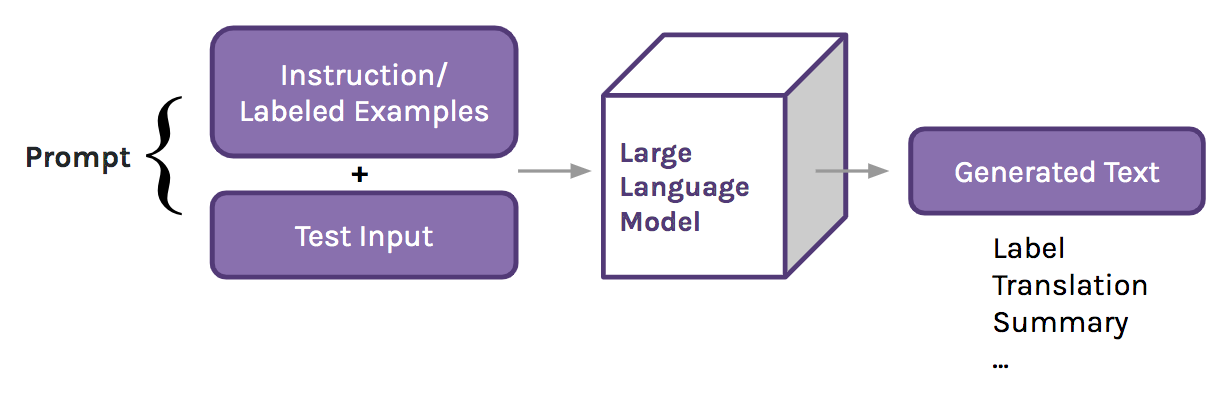
For example, let’s say we want to use an LLM to translate the sentence “Je te verrai demain.” from French into English. We prompt the model to do this by inputting a prompt containing an instruction and the sentence – The translation of "Je te verrai demain.." in English is __ – into the LM. The model would then return the text “I will see you tomorrow” to answer the prompt.

However, LLMs are highly sensitive to how the prompt is written. Their performance can vary greatly when only slight changes to the prompting format are made -- even when these changes mean the same thing to a human. When translating into English, prompting the same model with slight variations in the input text, including formatting and phrasing of the instruction, can lead to drastically different outputs. We explore the phenomenon of LLM sensitivity to prompting choices through two core linguistic tasks and categorize how specific prompting choices can affect the model's behavior.
Linguistic Analysis in the Era of LLMs
While en vogue, the in-context learning paradigm currently focuses on two types of NLP tasks: generation, where the output is a string of free-form text, and classification problems with a single label, or answer.
This setup overlooks an entire language-motivated side of core NLP, where the models produce linguistic analyses of text, such as a syntax tree. This area of NLP, which often falls under the structured prediction class of machine learning tasks, requires the model to produce many outputs that are then composed into the underlying linguistic structure.
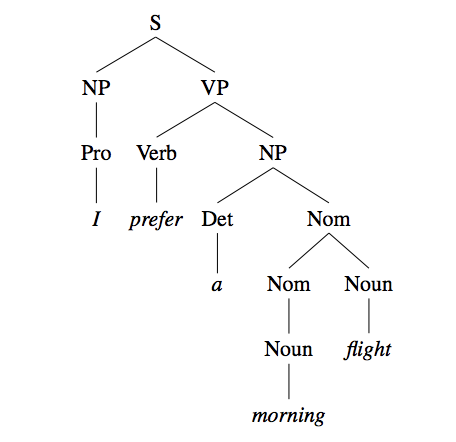
Understanding what LLMs learn about linguistics from large-scale pretraining is a good framework for understanding how they work in general. It can be difficult to reason about the behavior of LLMs, especially when it is unclear whether they actually encode the information being tested. However, linguistic structure is well-defined and implicit in all natural language texts, and the fluency of LM-generated text indicates that they have largely captured these underlying structures. We want to tap into this knowledge in order to test their behaviors in a controlled fashion.
Structured Prompting: Prompting LLMs to Probe for Linguistics
Since prompting only provides instructions or a few examples to the model, almost all knowledge about any task the model can perform via prompting must already be inside the model. Because of this, we can think of prompting the LLM as a way to probe the model, or test for information stored in the model's weights [3].
Probing is a helpful tool for understanding the behavior of NLP models. However, standard prompting methods produce one output for each example, while structured prediction tasks generally require many labels to be predicted. If we want to use prompting as probing for linguistic structure, we need to change the prompting setup so it can handle more complex tasks.
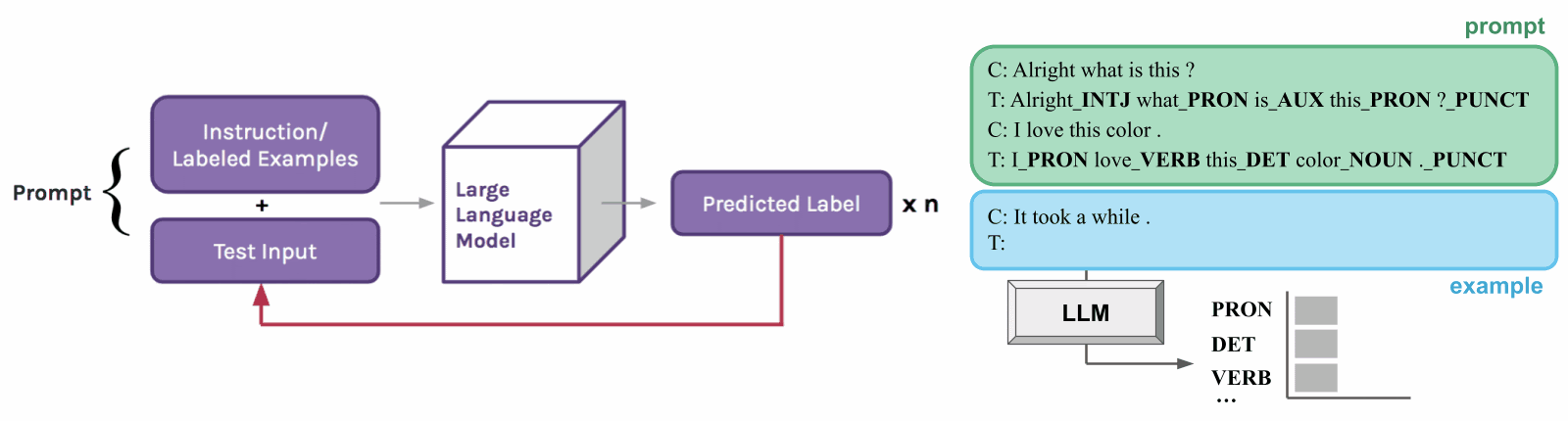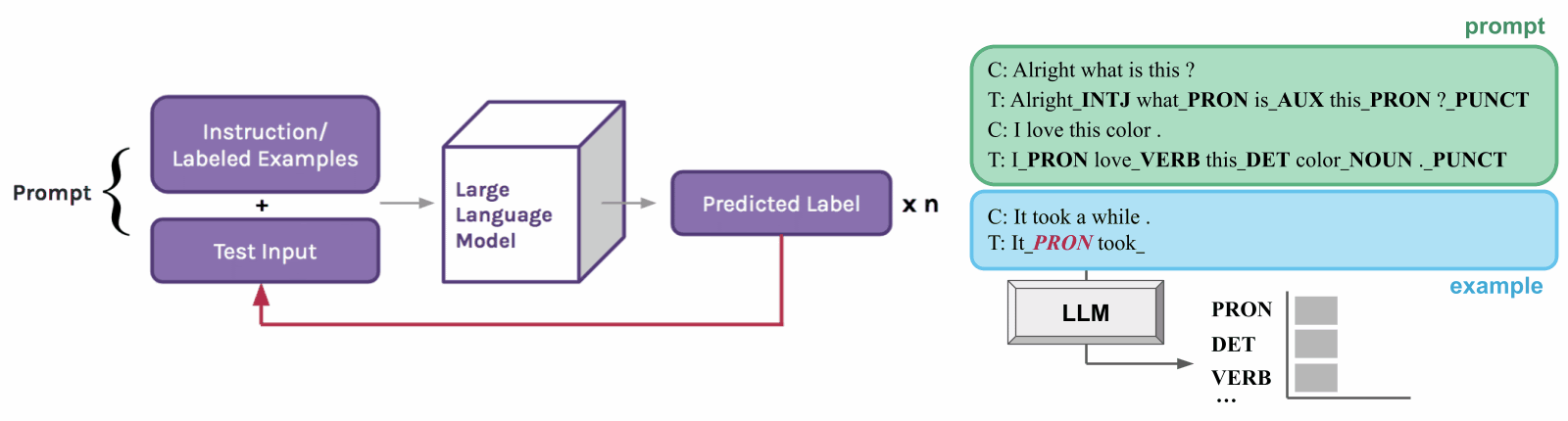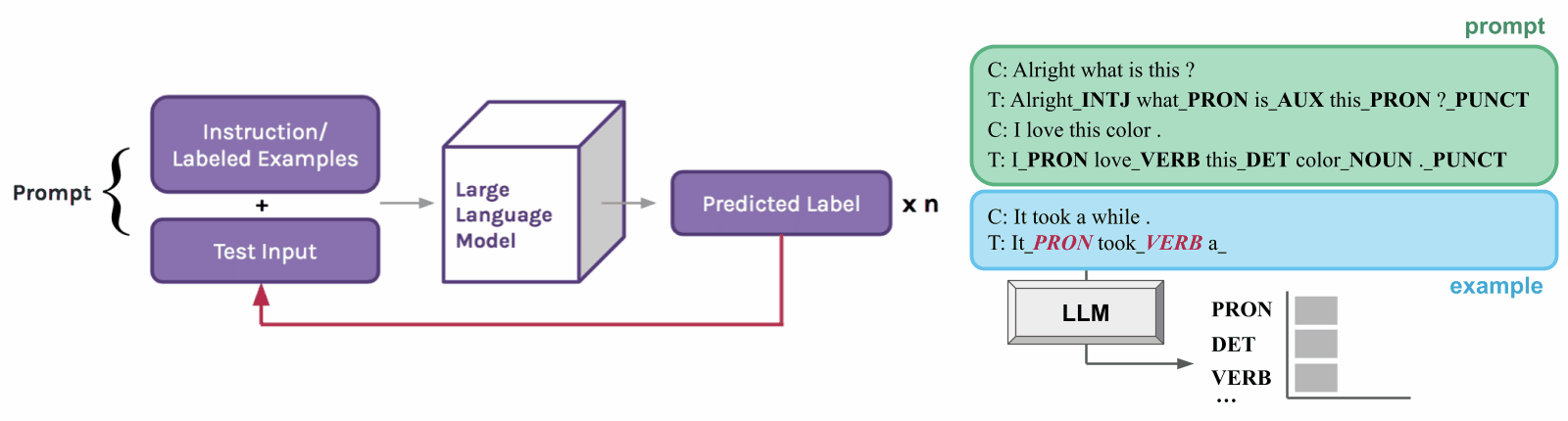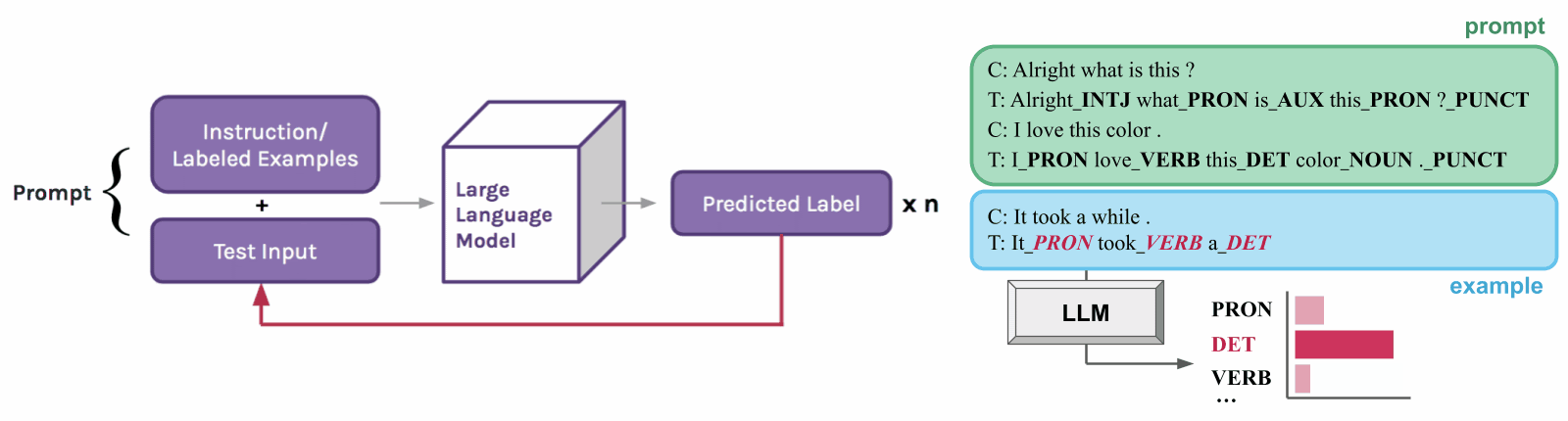
To do this, we develop an extension of in-context learning called structured prompting [2]. Instead of only generating one answer per example, we repeatedly prompt the LLM for linguistic tags (or labels) over each word in the example text. We also provide the model with its prediction history in context to help it produce more consistent structures.
LLMs Can Perform Linguistic Annotation with Structured Prompting
We applied structured prompting to the GPT-Neo LLM series, which are open-source models from EleutherAI [4, 5, 6], and looked at whether these models can use the approach to perform two linguistic annotation tasks:
- Part-of-speech (POS) tagging, which is the task of identifying the part-of-speech (such as noun, verb, etc.) of each word in a sentence; and
- Named-entity recognition (NER), which entails identifying and labeling named entities (such as people, locations, etc.) in the example.
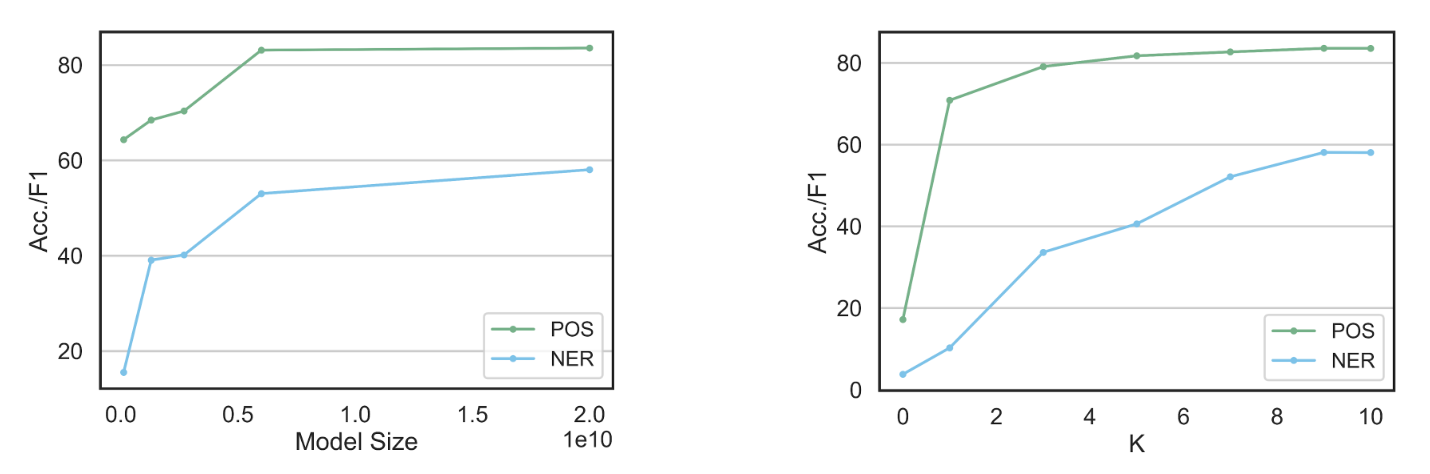
Probing the GPT-Neo models with the structured prompting method shows that these LLMs can perform linguistic annotations from just a few examples. Like other types of prompting, models with more parameters are typically better at in-context learning for structure than the smaller ones (e.g., [7]). The models also perform better when they see more examples in the prompt.
More generally, the LLMs are also able to handle the most difficult cases of choosing the correct part-of-speech for ambiguous words who’s meaning depends on the rest of the sentence. For instance, GPT-NeoX is able to correctly label words like “end,” “walk,” and “plants” (all of which can be a verb or a noun) 80% or more of the time. We also find that when the LLMs make a mistake during structured prompting, the kinds of errors are reasonable: most POS tagging errors of the largest LLM, GPT-NeoX, come from confusing proper nouns with regular nouns and auxiliary verbs (i.e.,, “helping” verbs like “be” and “may”) for verbs. In other words, the LLM’s errors are usually on tags that are closely related to each other, which is similar to the kinds of errors humans make when annotating the parts-of-speech in a sentence.
Our experiments show that structured prompting performs similarly to other prompting approaches and that the kinds of errors the models make demonstrate an understanding of the relationship between similar categories of labels. Overall, structured prompting can consistently generate the linguistic structure underlying text from LLMs, confirming that these models have implicitly learned these structures during pretraining.
How Does Structured Prompting Work?
While we are able to use structured prompting to probe LLMs and to show that it behaves similarly to other prompting methods, how and when in-context learning works remains an open question. We know that how you phrase the instruction is critical [8] and that, in some cases, the prompt doesn't even need to describe the correct task [9]! Moreover, when the model is given examples of how to do the task, the demonstration labels don't need to be correct for the model to learn from them [10]. Since the elements that decide whether or not in-context learning works are unintuitive to LLM users, it's impossible to understand our models' behavior from task performance alone.
This leads us to ask: what factors of structured prompting allow LLMs to annotate linguistic structure? We test three label settings with the GPT-NeoX model to see how the choice of labels affects structured prompting performance. If the model is only learning in-context (i.e., not using prior knowledge about the task), then changing these labels should have little impact on the model's abilities.
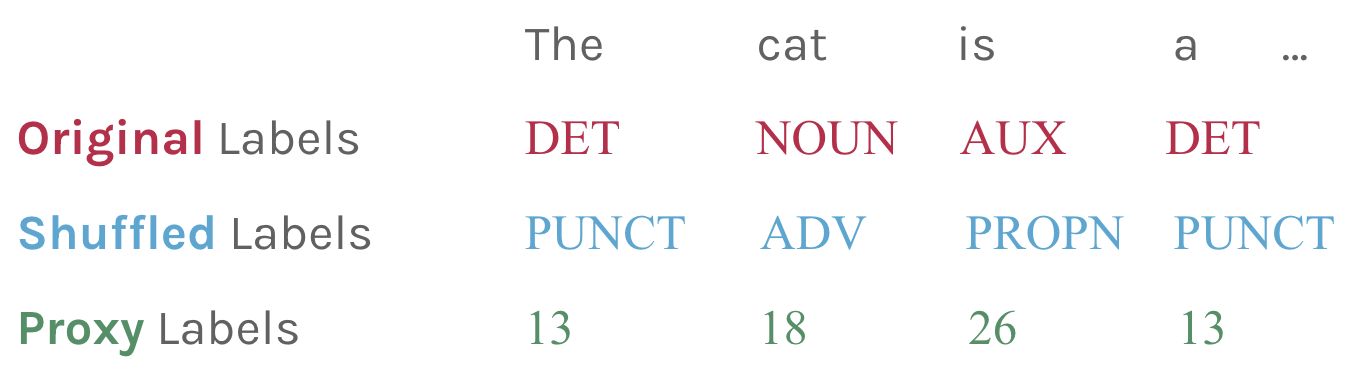
We consider (a) the original labels that came with the dataset we evaluate the models on, (b) shuffled labels, where each category we are classifying is represented by a different, random label (but making sure that the labels are still consistent across examples in the same category), and (c) proxy labels, where each category is instead represented by an integer so that the meaning of the label is no longer a factor.
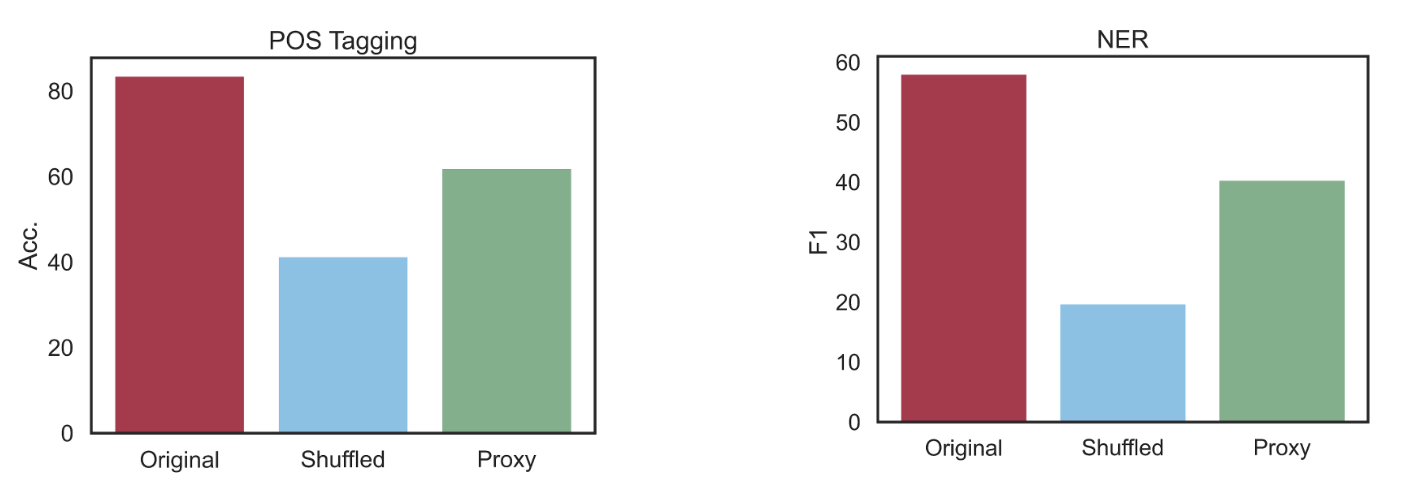
Shuffling the labels confuses the model and greatly hurts performance. Interestingly, the errors in the shuffled setting often come from predicting the original label of the category for the task. This means that in these cases, the model ignores the shuffled labels from the in-context examples because it already knows the correct label for that category. More generally, this tells us that the model will ignore our instructions if they conflict with what it learned from pretraining.
However, representing the categories with proxy labels hurts performance much less than shuffling. This result shows us that LLMs can in-context learn from examples, even when the labels aren't related to the task. For prompting to work, though, the in-context examples can't contradict things that the model has already learned.
Data Contamination: What About the (Pre)training Corpus?
In order to learn to in-context learn, LLMs need to be trained on extremely large amounts of diverse text data. Since there is too much text in the pretraining data for even the creators of an LLM to know exactly what the model saw during training, dataset contamination -- or including labeled data for evaluation tasks in the pretraining text -- is an open problem. Dataset contamination provides the model with supervised training for a task that the users assume it has never seen before. When this happens, it leads to a false estimate of how well pretrained LMs can generalize from pretraining on natural language text.
Some language modeling papers test for data contamination from their chosen test sets [6, 10], but usually, LLM users do not check if other examples of their task are in the pretraining data. Often, this is because testing for data contamination is impossible when the pretraining data is not public, such as for popular closed-source models like those from OpenAI.
However, anecdotal evidence has shown that data contamination likely affects the performance of models like OpenAI’s GPT-4 on tasks including coding interview problems and drawing animals with the TikZ latex package. Since we find that the LLMs already know a lot about the tasks we tested them on, a reasonable hypothesis is that this information came from task examples that leaked into the model’s pretraining dataset.
Luckily, GPT-NeoX was pretrained on the Pile, a publicly available collection of text documents from the Internet, books, news articles, and many other domains [4], which means we can check the pretraining data directly for contamination. To find examples of data contamination, we search the Pile for contexts where the task labels occur. By searching for labels instead of full examples, we can find task examples even if they are not in our particular datasets.

After searching the Pile for the labels, we see that it contains many examples of both POS tagging and NER. The POS tagging examples, in particular, are widespread in the Pile because many datasets with the same set of POS tags (Universal Dependencies) are hosted on GitHub, which is included in the Pile. There are also examples for both tasks from many other kinds of text, including Stack Overflow and arXiv papers. Many of these examples were written as one-off descriptions of the task and did not come from a formal dataset. Because of this, it is hard to prevent data contamination just by filtering a single data source or exact matches from your chosen benchmark.
Revisiting Labels for Structured Prompting
Now that we know that the GPT-NeoX model has seen examples of both tasks with the corresponding labels, the large drop in performance when we alter those labels makes sense – the model learned about the task and its tags during pretraining. This leads us to ask: can LLMs perform these linguistic annotations accurately if we give them different but still relevant labels for the task? This would control for the data contamination we found while still allowing the model to use other knowledge about the task it learned from pretraining.

To test this, we added another label set to our previous label perturbation experiment, where each category is instead represented by the full name of that category, not the abbreviation used in the dataset. For example, the PROPN POS tags are rewritten as "proper noun," and the "LOC" named entity is instead "location."
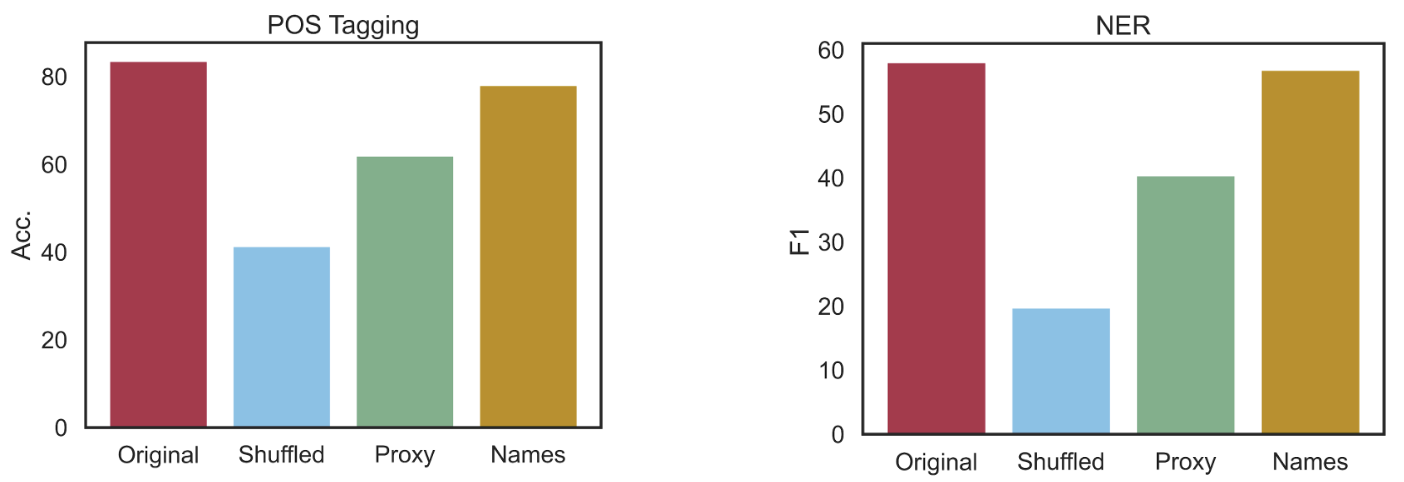
When we give the LLM the names as labels in the in-context examples, performance is almost as good as with the original labels. On NER, the names score is even within the standard error of the original across multiple runs, which means there is no significant difference between the two label sets. However, the decrease in POS tagging accuracy is significant: this is probably because the Universal Dependencies benchmarks in the Pile basically "trained" the model for POS tagging during pretraining.
In summary, changing the labels used during ICL significantly influences whether the model can produce linguistic structures for given sentences. Unsurprisingly, the best performance comes from using the existing task labels. While pretrained LMs are also robust to specific, semantically relevant prompt variations -- such as using category descriptions as labels -- they remain vulnerable to many other types of variation, particularly when those variants conflict with prior knowledge encoded by the model.
Conclusion
As LLMs become more mainstream, a huge hurdle for incorporating them into our lives is that we don’t actually know how they work, which makes their behavior difficult to predict. Through our experiments, we shed some light on when prompting works with two core NLP tasks: LLMs use both the in-context examples and things it already knows to perform a task via prompting, but they will ignore the examples you give it if they conflict with its prior knowledge. We also find that a lot of this “prior knowledge” comes from seeing labeled examples of these tasks during pretraining via dataset contamination. When we control for this, though, the LLM can still learn in-context from different sets of substitute labels.
Recently, the in-context label analyses we ran have been scaled up to more models and tasks, and they find that larger models (up to 540 billion parameters) are better at learning in-context from shuffled or substitute labels than smaller ones [12, 16]. Other work has found that the reliance on prior knowledge we uncovered also extends to code generation with LLMs [13].
There is also further evidence that the pretraining data can explain many of these in-context learning quirks, such as in the case of the frequency of numbers in the data correlating with better accuracy on math problems [15] or non-English text leaking into English pretrained models, allowing them to perform tasks in other languages [17]. While direct evaluation of the pretraining data is not possible for the many models trained on unreleased data, methods are being developed to circumvent this issue. One way to do this is by leveraging the perplexity of prompts as an estimate of the distribution of the pretraining data (and prompt performance) [14].
With the current promise of large language models towards many potential applications, further insights into how LLMs work are vital for using them safely and to their fullest potential. It’s increasingly important that we know what our models are trained on and how that affects our models as we begin applying LLMs to practical applications and encouraging mainstream users to incorporate them into their lives.
Author Bio
Terra Blevins is a Ph.D. student in the Natural Language Processing group at the University of Washington. Her research specializes in multilingual NLP and the analysis of language models, with a focus on explaining the behavior of pretrained systems through their training data. She graduated from Columbia University with a BA in Computer Science.
References:
BibTeX citation (the paper that this blog post is based on):
@inproceedings{blevins2023prompting,
title = {Prompting Language Models for Linguistic Structure},
author = {Blevins, Terra and Gonen, Hila and Zettlemoyer, Luke},
booktitle = {Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics},
year = {2023},
publisher = {Association for Computational Linguistics},
url = {https://arxiv.org/abs/2211.07830},
}
[1] Pretrain, Prompt, Predict https://arxiv.org/abs/2107.13586
[2] Prompting Language Models for Linguistic Structure https://arxiv.org/abs/2211.07830
[3] This is specifically a form of “behavioral” probing, there the model outputs are interpreted directly, rather than an “auxiliary” or “diagnostic” probe that instead interprets the intial representations of the model. A survey of this area can be found in this tutorial.
[4] The Pile + GPT-Neo Models https://arxiv.org/abs/2101.00027
[5] GPT-J https://arankomatsuzaki.wordpress.com/2021/06/04/gpt-j/
[6] GPT-NeoX https://aclanthology.org/2022.bigscience-1.9/
[7] Language Models are Few-shot Learners https://arxiv.org/abs/2005.14165
[8] Reframing Instructional Prompts to GPTk’s language https://aclanthology.org/2022.findings-acl.50/
[9] Do prompt-based models really understand the meaning of their prompts? https://aclanthology.org/2022.naacl-main.167/
[10] Rethinking the Role of Demonstrations https://arxiv.org/abs/2202.12837
[12] Large Language Models Do In-Context Learning Differently https://arxiv.org/abs/2303.03846
[13] The Larger They Are, the Harder They Fail: Language Models do not Recognize Identifier Swaps in Python https://arxiv.org/abs/2305.15507
[14] Demystifying Prompts in Language Models via Perplexity Estimation https://arxiv.org/abs/2212.04037
[15] Impact of Pretraining Term Frequencies on Few-Shot Reasoning https://arxiv.org/abs/2202.07206
[16] What In-Context Learning “Learns” In-Context: Disentangling Task Recognition and Task Learning https://arxiv.org/abs/2305.09731
[17] Language Contamination Helps Explain the Cross-lingual Capabilities of English Pretrained Models https://aclanthology.org/2022.emnlp-main.233
[18] BLOOM:A 176B-Parameter Open-Access Multilingual Language Model https://arxiv.org/abs/2211.05100



{kind=link}
{kind=link}
{kind=link}
{kind=link}