
Two years after BERT was unveiled to the world, Transformers are still dominating the leaderboards and have spawned numerous follow-up studies.
The first version of our attempt to survey BERTology literature (Rogers et al. 2020) provided an overview of about 40 papers in February 2020. By June, there were over a hundred. The final TACL camera-ready version has about 150 BERT-related citations, and no illusions of completeness: we ran out of journal-allotted pages in August 2020.
But even with all that research, it is still not clear why BERT works so well. Many studies (Hewitt and Manning 2019; Liu et al. 2019; Clark et al. 2019; Htut et al. 2019) suggest that BERT has a lot of information about language, which should explain its high performance. However, the majority of BERT analysis papers focus on different kinds of probes: direct probes of the masked language model (Ettinger 2020; Goldberg 2019), or various tasks (POS-tagging, NER, syntactic parsing etc), for which a supervised classifier is trained on top of full BERT or some part of it (Htut et al. 2019; Tenney, Das, and Pavlick 2019). The former does not actually tell us much about fine-tuned BERT, which is how it is most commonly used, and the latter adds extra parameters, which makes it hard to unambiguously assign credit to the underlying BERT representations. Furthermore, it is now clear that many current NLP datasets have all kinds of biases and artifacts (Gururangan et al. 2018; Geva, Goldberg, and Berant 2019), and BERT does exploit them (T. McCoy, Pavlick, and Linzen 2019; Jin et al. 2020; Sugawara et al. 2018; Rogers et al. 2020).
The recent work provides hints for an alternative direction of research:
- the Lottery Ticket Hypothesis proposes that randomly initialized neural networks contain subnetworks that could be re-trained alone to reach (and sometimes exceed) the performance of the full model (Frankle and Carbin 2019);
- most of BERT’s self-attention heads can be pruned based on importance scores derived from the model’s gradients (Michel, Levy, and Neubig 2019);
- for the Base-Transformer models, trained for machine translation, the heads pruned last tended to have syntactic functions (Voita et al. 2019).
Given all that: if BERT is so overparameterized, could we make it more interpretable by pruning it down to its most essential components? If they are indeed crucial for the model’s performance, then their functions should tell us something about how the whole thing actually works. Under this approach, we would use pruning as a technique for model analysis rather than model compression.
In a joint project with Sai Prasanna (Zoho) and Anna Rumshisky (UMass Lowell), we found that unstructured pruning of BERT weights, based on their magnitude, is consistent with the core Lottery Ticket Hypothesis’s predictions, and yields stable subnetworks. However, pruning BERT heads and MLPs based on their importance scores does not yield 'good' subnetworks that are consistent across fine-tuning initializations or even similar tasks (which would indicate consistent reasoning strategies). Neither do these subnetworks preferentially contain self-attention heads that encode potentially interpretable patterns. For most GLUE tasks, the 'good' subnetworks can be retrained to reach performance close to that of the full model, but so can randomly sampled subnetworks of the same size. This is good news for BERT compression (it's a lottery you can't lose), but bad news for interpretability.
Pruning BERT
Once again, the Lottery Ticket Hypothesis predicts that randomly initialized neural networks contain subnetworks that could be re-trained alone to reach the performance of the full model (Frankle and Carbin 2019). We use two pruning methods to find such subnetworks and to test whether the hypothesis holds: unstructured magnitude pruning and structured pruning.
The classical Lottery Ticket Hypothesis was mostly tested with unstructured pruning, specifically magnitude pruning (m-pruning) where the weights with the lowest magnitude are pruned irrespective of their position in the model. We iteratively prune 10% of the least magnitude weights across the entire fine-tuned model (except the embeddings) and evaluate on dev set, for as long as the performance of the pruned subnetwork is above 90% of the full model.
We also experiment with structured pruning (s-pruning) of entire components of BERT architecture based on their importance scores: specifically, we 'remove' the least important self-attention heads and MLPs by applying a mask. In each iteration, we prune 10% of BERT heads and 1 MLP, for as long as the performance of the pruned subnetwork is above 90% of the full model. To determine which heads/MLPs to prune, we use a loss-based approximation: the importance scores proposed by Michel, Levy and Neubig (2019) for self-attention heads, which we extend to MLPs. Please see our paper and the original formulation for more details.
For both methods the masks are determined with respect to full model performance on a specific dataset. We are interested in finding the subnetworks that enable BERT to perform well on the full set of 9 GLUE tasks (Wang et al. 2018). GLUE test sets are not publicly available, and we use the dev sets to both find the pruning masks and to test the model. Since we are interested in BERT's 'reasoning strategies' rather than generalization, this approach lets us see the best/worst possible subnetworks for this specific data.
How stable are the “good” subnetworks across random initialization?
Recent work showed that there is considerable variation in BERT performance across random initializations of the task-specific layer (Dodge et al., 2020), to the extent that different initializations result in dramatically different generalization performance (R. T. McCoy, Min, and Linzen, 2019).
We estimate the stability of the “good” subnetworks by running each experiment on each GLUE task with 5 random initializations of BERT’s task-specific layer (the same set of seeds is used across all experiments). Here are examples of the “good” subnetworks found with both pruning methods:
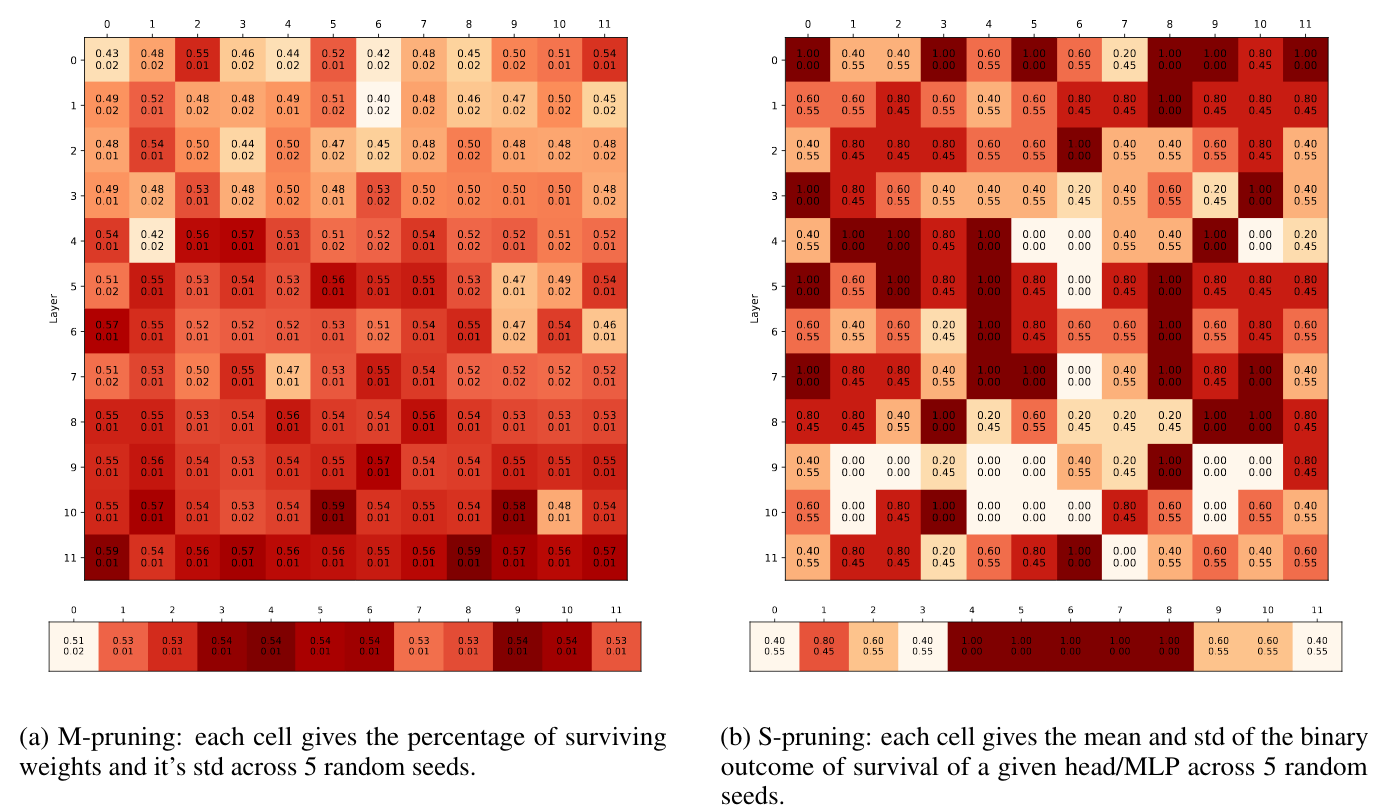
Clearly, the m-pruned subnetworks are quite stable (std mostly around 0.01). But the same cannot be said for s-pruning: there are a few heads are “super-survivors” (i.e. they survive in all random seeds), and some never survive the pruning, but for about 70% of the heads the standard deviation is in the 0.45-0.55 range. The Fleiss’ kappa for head/MLP survival masks across random seeds is also low, in the range of 0.1-0.3.
The reason for that appears to be that the importance scores for most BERT heads are equally low. Here is an example of importance score distribution for CoLA at pruning iteration 1: most heads are equally unimportant and can all be pruned with about the same effect.

How stable are the “good” subnetworks across tasks?
Since for m-pruning the key factor is the magnitude of pre-trained BERT weights, the m-pruned subnetworks are quite similar both across random seeds and across tasks. But that is not the case for s-pruning, where the “good” subnetworks are quite different across tasks:
It does not seem to be the case that the related tasks consistently have more in common in terms of “good” subnetworks. The following diagram shows the average amount of “shared” self-attention heads, in the subnetworks for all GLUE tasks pairs. For instance, QQP and MRPC are closer in terms of task formulation than QQP and MNLI, but the “good” subnetworks share 52-55 heads in both cases.

Lottery Ticket Hypothesis for BERT?
We consider three experimental settings:
- the “good” subnetworks: the elements selected from the full model by either s-pruning or m-pruning;
- the “random” subnetworks: the elements randomly sampled from the full model to match the “good” subnetwork size;
- the “bad” subnetworks: the elements that did *not* survive the pruning, plus a few elements sampled from the remaining elements so as to match the good subnetwork size.
In all the three settings, we measure the performance of the pruned subnetworks as well as the performance of the same subnetwork re-fine-tuned, with the remainder of the model masked. Once again, the prediction of the Lottery Ticket Hypothesis is that the “good” subnetworks should be able to achieve the full model performance when re-fine-tuned.
We do find this to be the case for m-pruning: pruned and re-fine-tuned “good” subnetworks reach the full model performance in 8/9 GLUE tasks (except for WNLI, where the model generally fails to learn). These results are consistent with concurrent work on magnitude-pruned BERT (Chen et al. 2020). The “random” and “bad” subnetworks also generally perform better when re-fine-tuned, but the “bad” subnetworks are consistently worse than “random”.

However, for s-pruned subnetworks the trend is not the same. For most tasks the s-pruned subnetworks do not quite reach the full model performance, although for many tasks the difference is within 2 points. However, the “random” subnetworks can be re-trained almost as well as the “good” ones, which is consistent with the observation that the importance scores for the majority of heads are equally low. As for the “bad” subnetworks, note that since we evaluate on the dev sets of GLUE, which we also use to select the masks, the “bad” subnetworks are the worst possible selection of BERT elements for this particular data. Yet even they remain highly trainable, and on average they match the biLSTM+GloVe GLUE baseline.

Our takeaway from this is that s-pruned BERT could be said to have no “losing” tickets. It does not quite reach the full model performance, but for most GLUE tasks a random subset of the full model does nearly as well as the subnetwork selected by importance scores. This suggests that either most BERT components are redundant (in which case most random subsets would still contain the same information), or that there are genuine differences in the information content of different components, but the importance scores are not sensitive enough to them.
How linguistically informative are the “good” subnetworks?
In this experiment, we consider specifically the “super-survivors”: BERT components that survived s-pruning across 5 random seeds. If the success of BERT subnetworks is attributable to the linguistic knowledge they encode, the “super-survivors” should contain considerably more of it.
We focus on the self-attention heads, as they have been the focus of numerous BERTology studies showing that they encode specific linguistic knowledge (Htut et al. 2019; Clark et al. 2019), as well as the interpretability debate (Brunner et al. 2019; Jain and Wallace 2019; Wiegreffe and Pinter 2019). Instead of using probing to identify potential functions of BERT heads, we opt for direct analysis of their attention patterns, of which there are 5 types (Kovaleva et al. 2019):

Since the “heterogeneous” pattern is the only one that could potentially encode linguistically interpretable relations, the ratio of the self-attention heads with such patterns provides an upper bound for the interpretable patterns. Following (Kovaleva et al. 2019), we train a CNN classifier on the manually annotated set of 400 self-attention maps provided by the authors. We also consider the weight-normed attention maps (Kobayashi et al. 2020), which should reduce the attention to special tokens, and for which we annotate 600 more attention map samples. Then we encode 100 examples from each GLUE task, generate the attention maps for each BERT head, and use our trained classifiers to estimate how many patterns of each type we get. On the annotated data, the classifiers yield F1 of 0.81 for the raw attention maps and 0.74 for the weight-normed maps.
We observe that for the raw attention maps the super-survivor heads have more block and vertical+diagonal patterns, but the number of heterogeneous patterns does not increase. In weight-normed condition the ratio of diagonal patterns decreases, but for most tasks the super-survivors still have 30-40% diagonal patterns. In both conditions, two paraphrase detection tasks (MRPC and QQP) have a notable increase in the amount of vertical attention patterns, which usually indicates attention to SEP, CLS, and punctuation (Kovaleva et al., 2019).
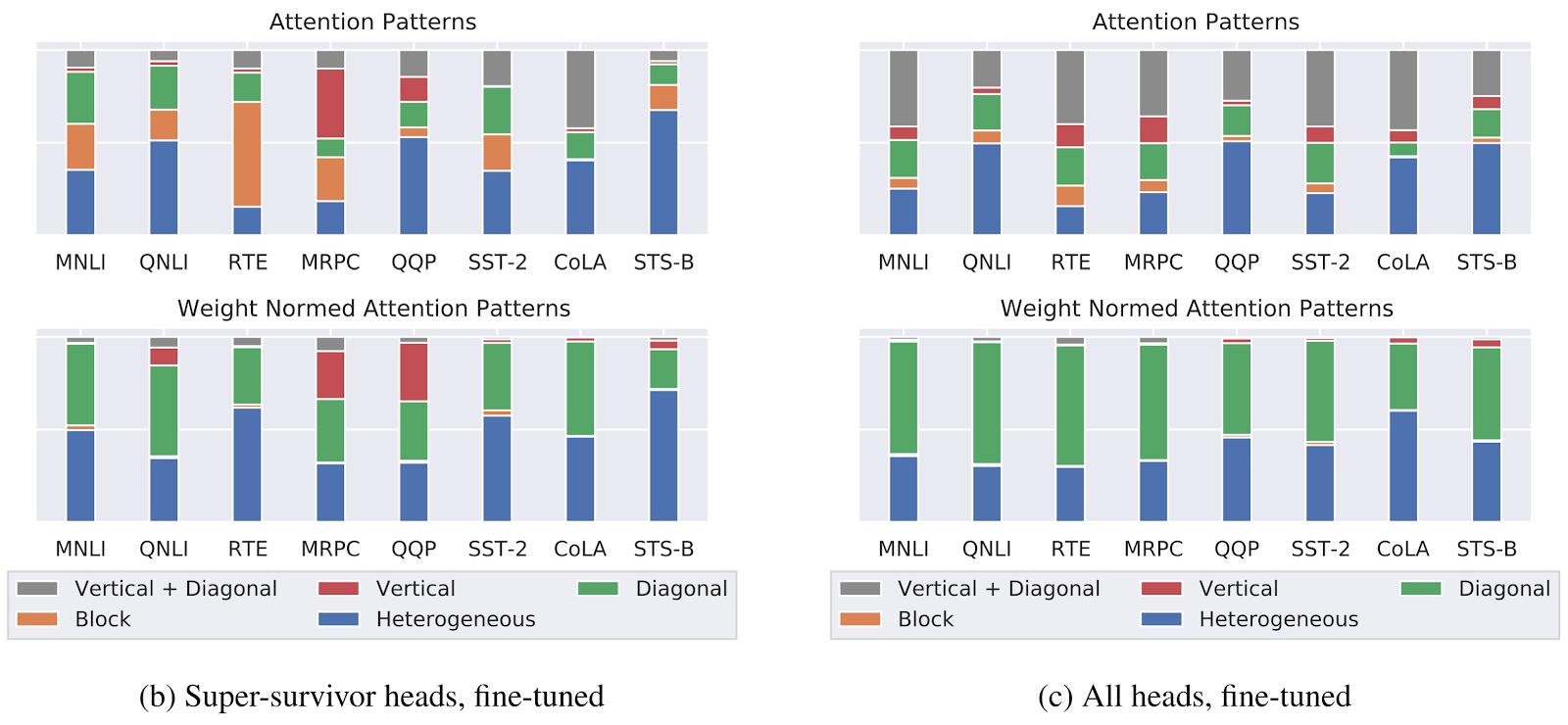
Overall, it does not seem to be the case that the super-survivor subnetworks consist predominantly of the potentially meaningful self-attention patterns. This result contrasts with the previous report of the self-attention heads that do the “heavy lifting” (Voita et al. 2019); however, the two studies explore different architectures (BERT vs the full Transformer), and they rely on different methods for pruning and interpreting self-attention heads.
Conclusion
Both our study and concurrent work (Chen et al. 2020) confirm that the Lottery Ticket Hypothesis holds when using magnitude pruning on BERT: “good” subnetworks can be retrained to reach full model performance.
Structured pruning tells a different story: we find that pruning most of the subnetworks of BERT using this method results in similar performance between “good”, “random” and “bad” networks, and that none of them can quite achieve the performance of the original network. Thus it could be said that with structured pruning BERT has no “losing” tickets, even if it does not fully “win”.
Our experiments also suggest that BERT’s high performance does not seem to come from specific linguistic knowledge uniquely encoded in pre-trained weights of specific BERT’s components (self-attention heads and MLPs): otherwise the “good” subnetworks would have been stable across random seeds. They are also not stable across GLUE tasks, and the “good” subnetworks for tasks of the same type do not necessarily have more in common. Finally, even the self-attention heads that survive the most consistently do not have predominantly the self-attention patterns that are potentially interpretable.
All this means that we still have more questions than answers about how BERT achieves its remarkable performance. If so many of the important self-attention heads are not even potentially interpretable, should we give up on the idea that some knowledge is encoded in specific architecture components, rather than spread across the whole network? How can we study such distributed representations? Do we generally attribute high performance on GLUE to linguistic knowledge of BERT or dataset artifacts? Do we expect them to be manifest in the same way in self-attention weights? Is it about encoding linguistic knowledge at all, or does it perhaps have more to do with the match between the initialization of the task-specific layer and the optimization surface of the pre-trained weights? There are LSTM results suggesting that performance on linguistic tasks could benefit from non-linguistic pre-training (Papadimitriou and Jurafsky 2020).
The one thing that we know for sure is that BERTology research is far from over.
Author Bio
Anna Rogers is a post-doctoral associate at the University of Copenhagen. Her research interests lie at the intersection of natural language processing, machine learning, and social data science.
To cite the paper:
@inproceedings{prasanna-etal-2020-bert,
title = "{W}hen {BERT} {P}lays the {L}ottery, {A}ll {T}ickets {A}re {W}inning",
author = "Prasanna, Sai and
Rogers, Anna and
Rumshisky, Anna",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.259",
doi = "10.18653/v1/2020.emnlp-main.259",
pages = "3208--3229"
}
References
Brunner, Gino, Yang Liu, Damián Pascual, Oliver Richter, and Roger Wattenhofer. 2019. “On the Validity of Self-Attention as Explanation in Transformer Models.” arXiv:1908.04211 [Cs], August. http://arxiv.org/abs/1908.04211.
Chen, Tianlong, Jonathan Frankle, Shiyu Chang, Sijia Liu, Yang Zhang, Zhangyang Wang, and Michael Carbin. 2020. “The Lottery Ticket Hypothesis for Pre-Trained BERT Networks.” arXiv:2007.12223 [Cs, Stat], July. http://arxiv.org/abs/2007.12223.
Clark, Kevin, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. 2019. “What Does BERT Look at? An Analysis of BERT’s Attention.” In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 276–86. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/W19-4828.
Dodge, Jesse, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah Smith. 2020. “Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping.” arXiv:2002.06305 [Cs], February. http://arxiv.org/abs/2002.06305.
Ettinger, Allyson. 2020. “What BERT Is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models.” Transactions of the Association for Computational Linguistics 8: 34–48. https://doi.org/https://doi.org/10.1162/tacl_a_00298.
Frankle, Jonathan, and Michael Carbin. 2019. “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks.” In International Conference on Learning Representations. https://openreview.net/forum?id=rJl-b3RcF7.
Geva, Mor, Yoav Goldberg, and Jonathan Berant. 2019. “Are We Modeling the Task or the Annotator? An Investigation of Annotator Bias in Natural Language Understanding Datasets.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 1161–6. Hong Kong, China: Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1107.
Goldberg, Yoav. 2019. “Assessing BERT’s Syntactic Abilities.” arXiv:1901.05287 [Cs], January. http://arxiv.org/abs/1901.05287.
Gururangan, Suchin, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel Bowman, and Noah A. Smith. 2018. “Annotation Artifacts in Natural Language Inference Data.” In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), 107–12. New Orleans, Louisiana: Association for Computational Linguistics. https://doi.org/10.18653/v1/N18-2017.
Hewitt, John, and Christopher D. Manning. 2019. “A Structural Probe for Finding Syntax in Word Representations.” In, 4129–38. https://aclweb.org/anthology/papers/N/N19/N19-1419/.
Htut, Phu Mon, Jason Phang, Shikha Bordia, and Samuel R. Bowman. 2019. “Do Attention Heads in BERT Track Syntactic Dependencies?” arXiv:1911.12246 [Cs], November. http://arxiv.org/abs/1911.12246.
Jain, Sarthak, and Byron C. Wallace. 2019. “Attention Is Not Explanation.” In, 3543–56. https://aclweb.org/anthology/papers/N/N19/N19-1357/.
Jin, Di, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. 2020. “Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment.” In AAAI 2020. http://arxiv.org/abs/1907.11932.
Kobayashi, Goro, Tatsuki Kuribayashi, Sho Yokoi, and Kentaro Inui. 2020. “Attention Module Is Not Only a Weight: Analyzing Transformers with Vector Norms.” arXiv:2004.10102 [Cs], April. http://arxiv.org/abs/2004.10102.
Kovaleva, Olga, Alexey Romanov, Anna Rogers, and Anna Rumshisky. 2019. “Revealing the Dark Secrets of BERT.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 4356–65. Hong Kong, China: Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1445.
Liu, Nelson F., Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. 2019. “Linguistic Knowledge and Transferability of Contextual Representations.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 1073–94. Minneapolis, Minnesota: Association for Computational Linguistics. https://www.aclweb.org/anthology/N19-1112/.
McCoy, R. Thomas, Junghyun Min, and Tal Linzen. 2019. “BERTs of a Feather Do Not Generalize Together: Large Variability in Generalization Across Models with Similar Test Set Performance.” arXiv:1911.02969 [Cs], November. http://arxiv.org/abs/1911.02969.
McCoy, Tom, Ellie Pavlick, and Tal Linzen. 2019. “Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 3428–48. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/P19-1334.
Michel, Paul, Omer Levy, and Graham Neubig. 2019. “Are Sixteen Heads Really Better Than One?” Advances in Neural Information Processing Systems 32 (NIPS 2019), May. http://papers.nips.cc/paper/9551-are-sixteen-heads-really-better-than-one.
Papadimitriou, Isabel, and Dan Jurafsky. 2020. “Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models.” arXiv:2004.14601 [Cs], September. http://arxiv.org/abs/2004.14601.
Rogers, Anna, Olga Kovaleva, Matthew Downey, and Anna Rumshisky. 2020. “Getting Closer to AI Complete Question Answering: A Set of Prerequisite Real Tasks.” In Proceedings of the AAAI Conference on Artificial Intelligence, 8722–31. https://aaai.org/ojs/index.php/AAAI/article/view/6398.
Rogers, Anna, Olga Kovaleva, and Anna Rumshisky. 2020. “A Primer in BERTology: What We Know About How BERT Works.” (Accepted to TACL), February. http://arxiv.org/abs/2002.12327.
Sugawara, Saku, Kentaro Inui, Satoshi Sekine, and Akiko Aizawa. 2018. “What Makes Reading Comprehension Questions Easier?” In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 4208–19. Brussels, Belgium: Association for Computational Linguistics. https://doi.org/10.18653/v1/D18-1453.
Tenney, Ian, Dipanjan Das, and Ellie Pavlick. 2019. “BERT Rediscovers the Classical NLP Pipeline.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 4593–4601. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/P19-1452.
Voita, Elena, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. 2019. “Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 5797–5808. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/P19-1580.
Wang, Alex, Amapreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2018. “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding.” In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 353–55. Brussels, Belgium: Association for Computational Linguistics. http://aclweb.org/anthology/W18-5446.
Wiegreffe, Sarah, and Yuval Pinter. 2019. “Attention Is Not Not Explanation.” In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 11–20. Hong Kong, China: Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1002.
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.



{kind=link}
{kind=link}
{kind=link}
{kind=link}