
What do AI researchers, and more specifically AI researchers who focus on robotics, do? That is the question this article addresses, by summarizing my experience of going to the 2018 Robotics: Science and Systems conference. In particular, this article will focus more on summarizing the exciting technical work relevant to my background presented in the conference. But first, a non-technical look at the conference itself and the overall experience of attending it:
Background
So, as said in the video: RSS is one of the top three conferences in robotics (the others being ICRA and IROS). This year, it took place on June 26-30th and had roughly 1000 attendees, 230 paper submissions, 71 accepted papers, and 78 total talks: 71 session talks (5 minute talks explaining one of the papers that was accepted), 4 keynote talks (1 hour talks summarizing a notable researcher’s work and thoughts), and 3 early career talks (summarizing the ongoing work of a promising young academic). It was a single-track conference, meaning all attendees saw the same talks and that all these talks were given on just one stage:
Thank you to everyone who helped make #RSS2018 a big success. The videos of keynotes and spotlight presentations are now on the RSS website:https://t.co/M1MZ7wLEkS
— Robotics: Science and Systems (@RoboticsSciSys) July 16, 2018
And also on Youtube:https://t.co/4Mcar6Jycf@RoboticsSciSys Organising Committee
(photo by @markus_with_k) pic.twitter.com/hp9LkdzhE6
This article will primarily, though not exclusively, summarize content relevant to my background as a grad student focusing on the intersection of Computer Vision and Robotics. In particular, I will highlight the increased presence (relative to prior iterations of RSS) of learning-based methods that incorporate ideas from Computer Vision (CV), Natural Language Processing (NLP), and generally Machine Learning.
This increased presence of such work is notable not only as an isolated trend for this conference, but as an example of a broader trend in the field of AI; the CV and robotics communities growing closer. Since about the 1990s robotics as a subfield of AI grew very distinct from Computer Vision and Machine learning, and there was little collaboration or flow of ideas from one community to the other. Now, more and more vision labs are beginning to do work in robotics, and likewise robotics labs are starting to use techniques from CV. Just a few examples of this trend include: the development of ideas such as Grasp Quality Convolutional Neural Network by Berkeley’s Autolab, SE3-Nets by UW’s Robotics and State Estimation Lab, and Learned Task-Oriented Grasping for Robotic Tool Manipulation from my very own Stanford Vision and Learning lab.
So that’s where we are -- an exciting place to be. And to further see this trend in practice, we shall summarize the learning related papers from the RSS conference.
The Problems and the Papers
Grasping
Grasping -- the problem of reliably picking up and holding on to objects with a robotic gripper -- is one of the longstanding problems in robotics. Though there have long existed many algorithms based on physics to decide on the best way to grasp a given object, they have typically assumed having access to a 3D model of the object. This assumption may be reasonable for very organized settings such as factories, but in general is unrealistic. Then, about a decade ago CV started being applied to the problem of grasping, and this trend really took off several years ago as deep learning enabled much better performance. This year’s papers extended on the deep learning work of the past several years in two ways: by moving to closed loop rather than open loop grasping (continuously deciding on the best grasp, and so reacting to changes in the environment), and by introducing the notion of grasping for the purpose of using the grasped object as a tool rather than just to pick it up.
Closing the Loop for Robotic Grasping: A Real-time, Generative Grasp Synthesis Approach
Douglas Morrison, Peter Corke and Jurgen Leitner
Australian Centre for Robotic Vision, Queensland University of Technology
“[We propose] a Generative Grasping Convolutional Neural Network (GG-CNN) predicts the quality and pose of grasps at every pixel ... The light-weight and single-pass generative nature of our GG-CNN allows for closed-loop control at up to 50Hz, enabling accurate grasping in non-static environments where objects move and in the presence of robot control inaccuracies.”
Learning Task-Oriented Grasping for Tool Manipulation with Simulated Self-Supervision
Kuan Fang, Yuke Zhu, Animesh Garg, Andrey Kurenkov, Viraj Mehta, Li Fei-Fei, Silvio Savarese
Stanford Vision and Learning Lab, Stanford University
Localization
Perhaps the foremost emerging AI technology of today is autonomous cars, and at its basis is this problem - localization. Given sensor readings as well as control over its own movement, localization enables a robot to both know its location and create a map of the surroundings. Unsurprisingly, ideas from CV have been increasingly helpful in this domain as well, and this year’s papers on this topic made use of state of art techniques to solve very complex localization problems.
LoST? Appearance-Invariant Place Recognition for Opposite Viewpoints using Visual Semantics
Sourav Garg, Niko Suenderhauf, Michael Milford
Australian Centre for Robotic Vision , Queensland University of Technology

“We develop a suite of novel semantic-and-appearance-based techniques to enable for the first time high performance place recognition in this challenging scenario. We first propose a novel Local Semantic Tensor (LoST) descriptor of images using the convolutional feature maps from a state-of-the-art dense semantic segmentation network. Then, to verify the spatial semantic arrangement of the top matching candidates, we develop a novel approach for mining semantically-salient keypoint correspondences.”
Full-Frame Scene Coordinate Regression for Image-Based Localization
Xiaotian Li, Juha Ylioinas, Juho Kannala
Aalto University
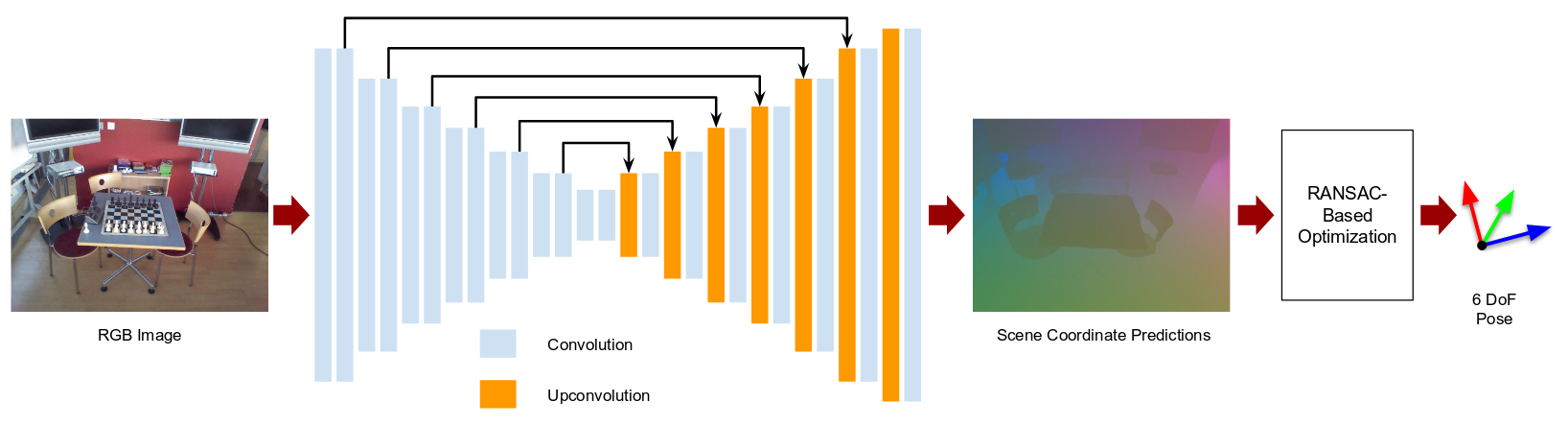
“In this paper, instead of in a patch-based manner, we propose to perform the scene coordinate regression in a full-frame manner to make the computation efficient at test time and, more importantly, to add more global context to the regression process to improve the robustness. To do so, we adopt a fully convolutional encoder-decoder neural network architecture which accepts a whole image as input and produces scene coordinate predictions for all pixels in the image.””
Sim2Real
Much of the complexity of robotics comes from one thing -- reality. As a field its basic aim to control robots to interact with the world so as to solve various problems. And so, unlike CV or NLP problems in robotics can rarely be reduced to the processing of data; learning must be accomplished with a robot interacting with the world, which quite obviously presents inumerable challenges not found when just working with data. But, as computing has improved both in power and sophistication, there is now an alternative to having a robot learning in the real world: having a simulated robot learning in a simulated world. This is great and makes things much easier, except for one snag: how to make a model trained in simulation be useful in the real world? That is the key question of Sim2Real Transfer, and several papers this year showcased the usefulness of this idea and advanced new ideas for it.
Asymmetric Actor Critic for Image-Based Robot Learning
Lerrel Pinto, Marcin Andrychowicz, Peter Welinder, Wojciech Zaremba, Pieter Abbeela
OpenAI, CMU
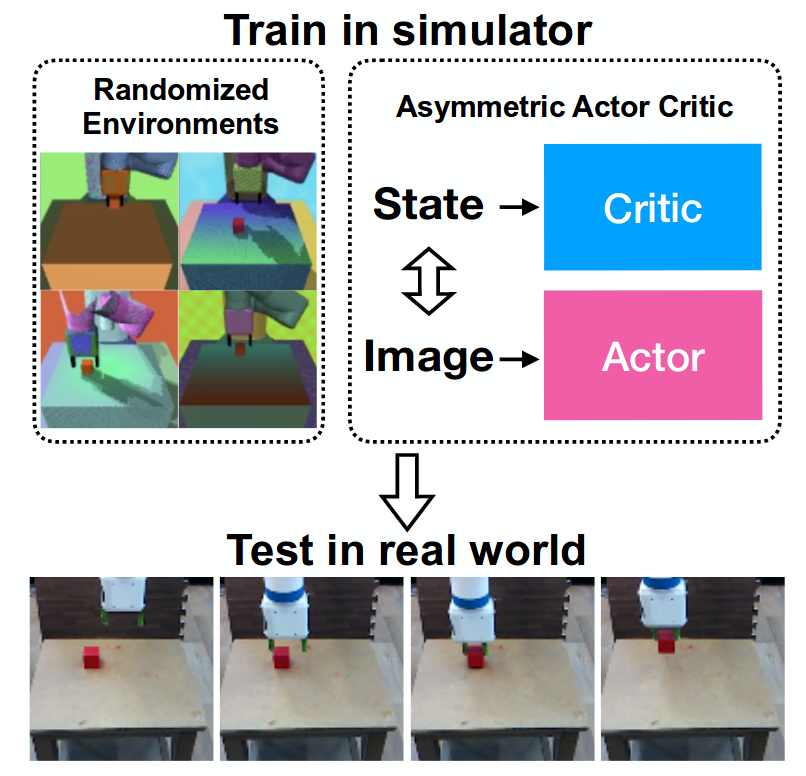
“In this work, we exploit the full state observability in the simulator to train better policies which take as input only partial observations (RGBD images). We do this by employing an actor-critic training algorithm in which the critic is trained on full states while the actor (or policy) gets rendered images as input ... Finally, we combine this method with domain randomization and show real robot experiments for several tasks like picking, pushing, and moving a block. ””
Sim-to-Real: Learning Agile Locomotion For Quadruped Robots
Jie Tan, Tingnan Zhang, Erwin Coumans, Atil Iscen, Yunfei Bai, Danijar Hafner, Steven Bohez, Vincent Vanhoucke
Google Brain, X, DeepMind
“In this work, we exploit the full state observability in the simulator to train better policies which take as input only partial observations (RGBD images). We do this by employing an actor-critic training algorithm in which the critic is trained on full states while the actor (or policy) gets rendered images as input ... Finally, we combine this method with domain randomization and show real robot experiments for several tasks like picking, pushing, and moving a block. ”
Imitation
Simulation is not the only way to leverage the unique aspects of robotics as a field to simplify things a bit. Much as it is possible to label data for many problems in AI, in robotics it is possible to provide “demonstrations” -- literally demonstrate the skill the robot ought to perform. Research in Learning from Demonstrations -- also known as imitation learning --- has been a topic in robotics for decades. But much like the above fields, the recent integrations of ideas from Deep Learning has led to these techniques becoming significantly more powerful.
Agile Autonomous Driving using End-to-End Deep Imitation Learning
Yunpeng Pan, Ching-An Cheng, Kamil Saigol, Keuntaek Lee, Xinyan Yan, Evangelos Theodorou, Byron Boots
Institute for Robotics and Intelligent Machines, Georgia Institute of Technology
JD.com American Technologies Corporation
“We present an end-to-end imitation learning system for agile, off-road autonomous driving using only low-cost on-board sensors. By imitating a model predictive controller equipped with advanced sensors, we train a deep neural network control policy to map raw, high-dimensional observations to continuous steering and throttle commands ... Built on these insights, our autonomous driving system demonstrates successful high-speed off-road driving, matching the state-of-the-art performance.”
One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
Tianhe Yu, Chelsea Finn, Annie Xie, Sudeep Dasari, Tianhao Zhang, Pieter Abbeel, Sergey Levine
University of California, Berkeley
“We present an approach for one-shot learning from a video of a human by using human and robot demonstration data from a variety of previous tasks to build up prior knowledge through meta-learning. Then, combining this prior knowledge and only a single video demonstration from a human, the robot can perform the task that the human demonstrated.”
Imitation + RL
But imitation alone is clearly insufficient -- it would take lifetimes to demonstrate all the variations needed to encompass how a particular skill should be done in various contexts. And so people combined the idea of using demonstrations with good ol’ reinforcement learning. And once again, Deep Learning has come to the fore to empower this idea. Multiple papers at this year’s RSS demonstrated this can be used to learn very complicated things, such as diverse visuomotor skills (controlling a robot using only vision as input) and the dexterous use of a human-like robotic hand.
Reinforcement and Imitation Learning for Diverse Visuomotor Skills
Yuke Zhu, Ziyu Wang, Josh Merel, Andrei Rusu, Tom Erez, Serkan Cabi, Saran Tunyasuvunakool, János Kramár, Raia Hadsell, Nando de Freitas, Nicolas Heess
Stanford Vision and Learning Lab, Stanford University
DeepMind
“We propose a model-free deep reinforcement learning method that leverages a small amount of demonstration data to assist a reinforcement learning agent. We apply this approach to robotic manipulation tasks and train end-to-end visuomotor policies that map directly from RGB camera inputs to joint velocities. A brief visual description of this work can be viewed in this https URL”
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, Sergey Levine
University of California, Berkeley
“In this work, we show that model-free DRL can effectively scale up to complex manipulation tasks with a high-dimensional 24-DoF hand, and solve them from scratch in simulated experiments. Furthermore, with the use of a small number of human demonstrations, the sample complexity can be significantly reduced, which enables learning with sample sizes equivalent to a few hours of robot experience. The use of demonstrations result in policies that exhibit very natural movements and, surprisingly, are also substantially more robust.”
Language
There is another alternative to plain imitation beyond learning -- instruction. That is, making it possible for robots to simply be told what to do by humans instead of needing to figure it out on their own. And, once again, Deep Learning has enabled some monumental progress on this problem. For instance, it can enable robots to understand what objects people refer to or instructions of where to go.
Interactive Visual Grounding of Referring Expressions for Human-Robot Interaction
Mohit Shridhar, David Hsu
School of Computing, National University of Singapore
“Thispaper presents INGRESS, a robot system that follows human natural language instructions to pick and place everyday objects. The core issue here is the grounding of referring expressions: infer objects and their relationships from input images and language expressions. INGRESS allows for unconstrained object categories and unconstrained language expressions. Further, it asks questions to disambiguate referring expressions interactively. To achieve these, we take the approach of grounding by generation and propose a two-stage neural-network model for grounding. “
Following High-level Navigation Instructions on a Simulated Quadcopter with Imitation Learning
Valts Blukis, Nataly Brukhim, Andrew Bennett, Ross A. Knepper, Yoav Artzi
Department of Computer Science, Cornell University, Ithaca, New York, USA
Cornell Tech, Cornell University, New York, New York, USA
Tel Aviv University, Tel Aviv-Yafo, Israel
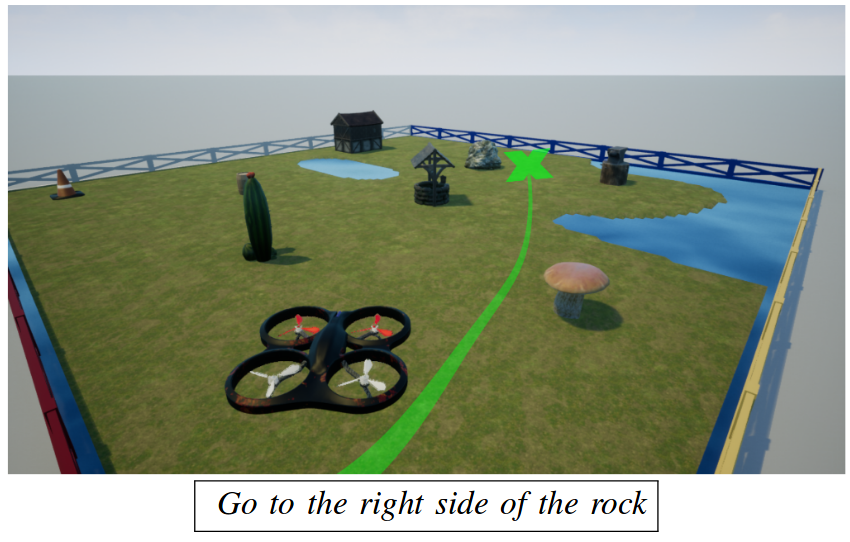
“We introduce a method for following high-level navigation instructions by mapping directly from images, instructions and pose estimates to continuous low-level velocity commands for real-time control. The Grounded Semantic Mapping Network (GSMN) is a fully-differentiable neural network architecture that builds an explicit semantic map in the world reference frame by incorporating a pinhole camera projection model within the network. The information stored in the map is learned from experience, while the local-to-world transformation is computed explicitly. We train the model using DAggerFM, a modified variant of DAgger that trades tabular convergence guarantees for improved training speed and memory use. We test GSMN in virtual environments on a realistic quadcopter simulator and show that incorporating an explicit mapping and grounding modules allows GSMN to outperform strong neural baselines and almost reach an expert policy performance. Finally, we analyze the learned map representations and show that using an explicit map leads to an interpretable instruction-following model.“
Learning New Stuff
Robotics does not emphasize learning as much as other AI subfields such as Computer Vision; in fact, to this day the majority of work in robotics involves developing algorithms and systems that solve problems relevant to robotics without any aspect of learning. But, recent work has shown that algorithms that have existed for decades can be made faster or more accurate by involving learning. At this conference, two such works were shown: one for Inverse Kinematics (figuring out how to make a complicated robotic arm reach a particular point in space), and one for Particle Filters (a method for tracking an estimate for some value over time given sense data and noise).
RelaxedIK: Real-time Synthesis of Accurate and Feasible Robot Arm Motion
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, Sergey Levine
Department of Computer Science, Cornell University, Ithaca, New York, USA
Cornell Tech, Cornell University, New York, New York, USA
Tel Aviv University, Tel Aviv-Yafo, Israel

“We present a real-time motion-synthesis method for robot manipulators, called RelaxedIK, that is able to not only accurately match end-effector pose goals as done by traditional IK solvers, but also create smooth, feasible motions that avoid joint-space discontinuities, self-collisions, and kinematic singularities. To achieve these objectives on-the-fly, we cast the standard IK formulation as a weighted-sum non-linear optimization problem, such that motion goals in addition to end-effector pose matching can be encoded as terms in the sum. “
Differentiable Particle Filters: End-to-End Learning with Algorithmic Priors
Rico Jonschkowski, Divyam Rastogi, Oliver Brock
Robotics and Biology Laboratory,
Technische Universiẗ at Berlin
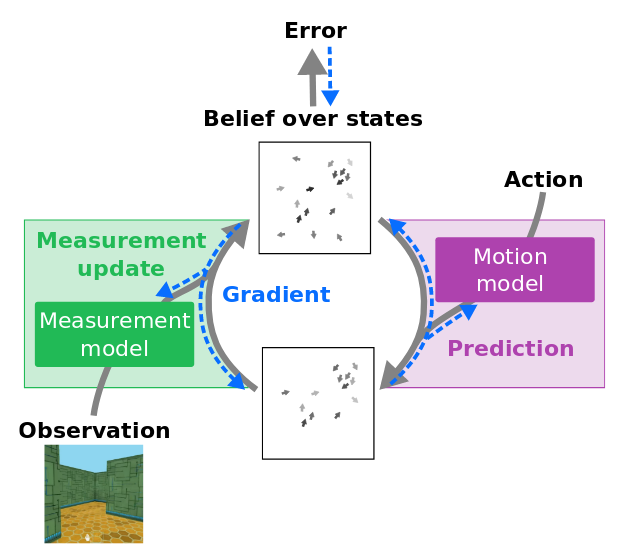
“We present differentiable particle filters (DPFs): a differentiable implementation of the particle filter algorithm with learnable motion and measurement models. Since DPFs are end-to-end differentiable, we can efficiently train their models by optimizing end-to-end state estimation performance, rather than proxy objectives such as model accuracy. “
Some cool non-learning papers
So, learning is being increasingly explored in the context of robotics for many problems. But of course, all the above work is only about a sixth of the papers presented at RSS, and there are plenty of exciting papers that involved no learning whatsoever. For the sake of variety, let’s take a look at a few of those.
HyP-DESPOT: A Hybrid Parallel Algorithm for Online Planning under Uncertainty
Panpan Cai, Yuanfu Luo, David Hsu, Wee Sun Lee
National University of Singapore
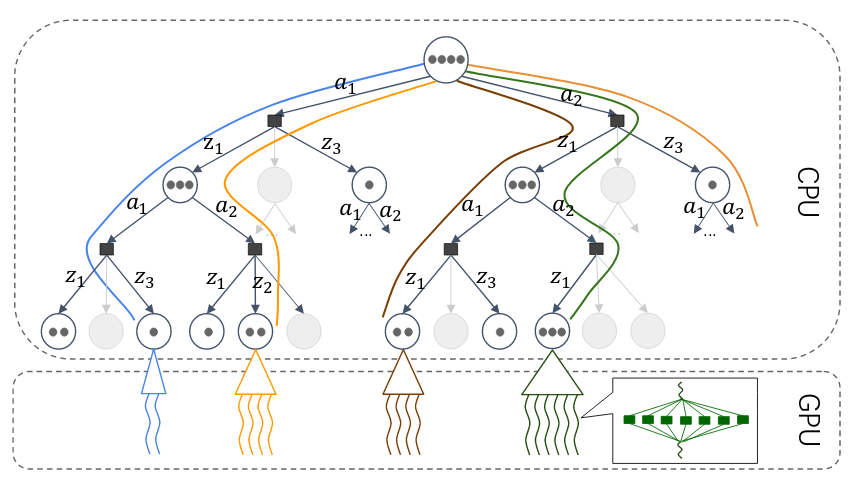
"Planning under uncertainty is critical for robust robot performance in uncertain, dynamic environments, but it incurs high computational cost. State-of-the-art online search algorithms, such as DESPOT, have vastly improved the computational efficiency of planning under uncertainty and made it a valuable tool for robotics in practice. This work takes one step further by leveraging both CPU and GPU parallelization in order to achieve near real-time online planning performance for complex tasks with large state, action, and observation spaces. Specifically, we propose Hybrid Parallel DESPOT (HyP-DESPOT), a massively parallel online planning algorithm that integrates CPU and GPU parallelism in a multi-level scheme.“
Probabilistically Safe Robot Planning with Confidence-Based Human Predictions
Jaime F. Fisac, Andrea Bajcsy, Sylvia L. Herbert, David Fridovich-Keil, Steven Wang, Claire J. Tomlin, Anca D. Dragan
University of California, Berkeley
“In this paper, we observe that how "rational" human actions appear under a particular model can be viewed as an indicator of that model's ability to describe the human's current motion. By reasoning about this model confidence in a real-time Bayesian framework, we show that the robot can very quickly modulate its predictions to become more uncertain when the model performs poorly. Building on recent work in provably-safe trajectory planning, we leverage these confidence-aware human motion predictions to generate assured autonomous robot motion.”
A Novel Whisker Sensor Used for 3D Contact Point Determination and Contour Extraction
Hannah M. Emnett, Matthew M Graff, Mitra J. Z. Hartmann
Northwestern University
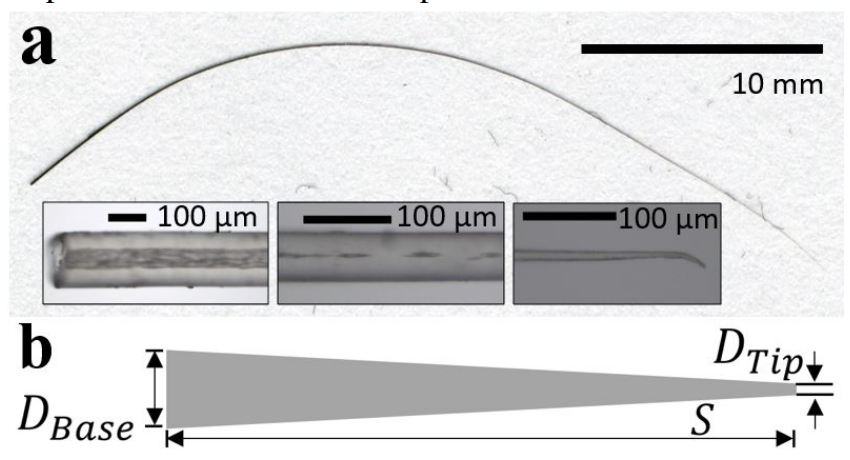
“We developed a novel whisker-follicle sensor that measures three mechanical signals at the whisker base. The first two signals are closely related to the two bending moments, and the third is an approximation to the axial force. Here we demonstrate hardware implementation of 3D contact point determination and then use continuous sweeps of the whisker to show proof-of principle 3D contour extraction.”
And, last but not least - the award winners
Lastly, this article would not be complete without highlighting the papers the conference itself highlighted -- the award winners. So, let us finish with that.
Best Student Paper Award: In-Hand Manipulation via Motion Cones
Nikhil Chavan-Dafle, Rachel Holladay, and Alberto Rodrigue
Massachusetts Institute of Technology
“In this paper we present the mechanics and algorithms to compute the set of feasible motions of an object pushed in a plane. This set is known as the motion cone and was previously described for non-prehensile manipulation tasks in the horizontal plane. We generalize its geometric construction to a broader set of planar tasks, where external forces such as gravity influence the dynamics of pushing, and prehensile tasks, where there are complex interactions between the gripper, object, and pusher. We show that the motion cone is defined by a set of low-curvature surfaces and provide a polyhedral cone approximation to it.“
Best Systems Paper Award: Embedded High Precision Control and Corn Stand Counting Algorithms for an Ultra-Compact 3D Printed Field Robot
Erkan Kayacan, Zhongzhong Zhang, Girish Chowdhary
Coordinated Science Laboratory, University of Illinois at Urbana-Champaign
Distributed Autonomous Systems Laboratory, University of Illinois at Urbana-Champaign
“This paper presents embedded high precision control and corn stands counting algorithms for a low-cost, ultracompact 3D printed and autonomous field robot for agricultural operations. Currently, plant traits, such as emergence rate, biomass, vigor and stand counting are measured manually. This is highly labor intensive and prone to errors. The robot, termed TerraSentia, is designed to automate the measurement of plant traits for efficient phenotyping as an alternative to manual measurement.”
Best Paper Award: Differentiable Physics and Stable Modes for Tool-Use and Manipulation Planning
Marc Toussaint, Kelsey R. Allen, Kevin A. Smith, Joshua B. Tenenbaum
Massachusetts Institute of Technology, Cambridge
Machine Learning & Robotics Lab, University of Stuttgart, Germany
“We consider the problem of sequential manipulation and tool-use planning in domains that include physical interactions such as hitting and throwing. The approach integrates a Task And Motion Planning formulation with primitives that either impose stable kinematic constraints or differentiable dynamical and impulse exchange constraints on the path optimization level.“
Conclusion
So there it is - a good chunk of the most exciting research from this year’s RSS. A commonly agreed upon notion was that the single track format and lack of overwhelming industry presence was a nice change from the likes of CVPR or even the bigger ICRA, as it allowed everyone to absorb the research presented more easily. Hopefully, this article and the video above let you experience a bit of that feeling vicariously.
Citation
For attribution in academic contexts or books, please cite this work as
Andrey Kurenkov, "Bringing Learning to Robotics: Highlights from RSS 2018", The Gradient, 2018.
BibTeX citation:
@article{KurenkovGradient2018RSS,
author = {Andrey, Kurenkov}
title = {Bringing Learning to Robotics: Highlights from RSS 2018},
journal = {The Gradient},
year = {2018},
howpublished = {\url{https://thegradient.pub/2018-rss-conference } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.
Andrey Kurenkov is a PhD student affiliated with the Stanford Vision and Learning Lab co-advised by Silvio Savarese and Ken Goldberg, and lead editor of Skynet Today. These opinions are solely his.




{kind=link}
{kind=link}
{kind=link}
{kind=link}