
Suppose you had a device that buzzed quietly in the corner of your room, obstructing the NSA's ability to snoop in on your conversations. Straight out of science fiction? Perhaps not for long.
This past January, Berkeley AI researchers Nicholas Carlini and David Wagner invented a novel attack against speech recognition AI. With the addition of an imperceptible amount of noise, the attack can trick speech-recognition systems into producing any output the attacker wants.
While this paper provides the first targeted attack on speech recognition, other adversarial attacks on systems like image recognition models have also demonstrated serious security vulnerabilities in deep learning algorithms.
Why deep learning is insecure
In 2013, Szegedy et al. introduced the first adversarial examples, inputs that appear normal to humans but trick algorithms into confidently outputting wrong predictions. Szegedy’s paper described an attack on image recognition systems that works by adding small amounts of specifically designed noise—say, to an image of a snail. Despite the new image appearing unchanged to a human eye, the added noise can trick the image recognition model into classifying the snail as a completely different object, like ‘mitten.’ Further research has discovered that the threat from adversarial attacks is very real: they can happen in the physical world, and they require changing as little as a single pixel. They can even work universally across all images.

Adversarial examples like these strike at the Achilles’ heel of deep learning. If it’s possible to disrupt self-driving car traffic just by slapping stickers on stop signs, we have little reason for confidence in automation. Thus, before we feel safe using deep learning in mission critical applications, we need to understand such weaknesses and how to defend against them.
Two types of adversarial attacks
There are two kinds of adversarial attack: non-targeted attacks and targeted attacks.
A non-targeted adversarial attack merely tricks the model into an incorrect prediction, without specifying what that incorrect prediction is. For speech recognition, this usually produces harmless mistakes, like transforming “I’m taking a walk in Central Park” to “I am taking a walk in Central Park.”
A targeted adversarial attack, however, is a more dangerous attack that tricks the model into producing a particular target prediction. This attack would allow a hacker to use small amounts of imperceptible noise to transform audio that should be interpreted as “I’m taking a walk in Central Park” into random gibberish, complete silence, or even a sentence like “Call 911 immediately!”.

The adversarial attack algorithm
Carlini & Wagner’s algorithm generates the first targeted adversarial attacks against speech recognition models. It works by generating a noisy “baseline” distortion of the original audio in order to trick the model, then using a custom-built loss function to shrink the distortion until it’s inaudible.
The baseline distortion is generated through a standard adversarial attack, which can be viewed as a variation on the supervised learning task. In supervised learning, the input data remains fixed, while the model is updated to maximize the probability of making the right prediction. In a targeted adversarial attack, however, the model remains fixed, while the input data is updated to maximize the probability of a specific incorrect prediction. Thus, supervised learning produces a model that effectively transcribes the given audio, while adversarial attacks produce input audio samples that effectively trick the given model.
But how do we calculate the probability that the model outputs a certain classification?

In speech recognition, the probability of the correct classification is calculated using a function called the Connectionist Temporal Classification (CTC) loss. The key motivation behind CTC loss is that it’s hard to define boundaries in audio: unlike written language which is usually separated by spaces, audio data is provided as a continuous waveform. Because there are many possible “alignments” of where the gaps between words can be, it’s difficult to maximize the probability that a certain sentence is recognized correctly. CTC gets around this issue by computing the total probability of the desired output over all possible alignments.
Carlini and Wagner’s improvement
But while this initial baseline attack is successful in tricking the target model, any human would be able to recognize that the audio has been altered. This is due to the tendency of CTC loss optimizers to add unnecessary distortion in segments of the audio where the target model has already been tricked, instead of focusing on the more resilient parts of the target model.
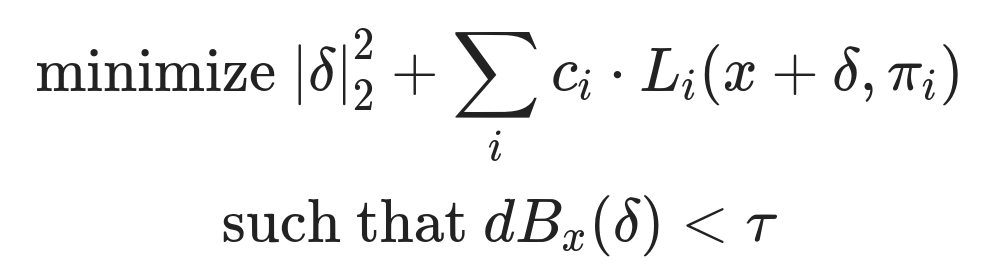
Carlini & Wagner’s custom loss function. $\pi$ is the calculated alignment, $\delta$ is the learned adversarial distortion, $\tau$ is the max acceptable volume, $c_i$ is a parameter that trades off minimizing distortion and further deceiving the model, $L_i$ is the loss for the $i$th output token.
Since a targeted attack is only as strong as its weakest link, Carlini and Wagner introduce a custom-designed loss function which penalizes unnecessary distortion that bolsters only the strongest parts of the attack. Starting with the baseline distortion, the algorithm then iteratively minimizes this function, preserving the distortion’s adversarial nature while gradually lowering its volume until it is too quiet for a human to hear. The end result is an audio sample that sounds identical to the original, but causes the target speech recognition model to output whatever the attacker desires 100% of the time.
Adversarial Attacks in the Real World
Though alarming, malicious adversarial attacks on speech recognition models are likely to be less dangerous than attacks on other applications. Unlike computer vision for self-driving cars, for instance, speech recognition is rarely the sole control point for critical applications. Voice activated controls can easily afford to spend an extra ten seconds and confirm proper understanding of the command before execution.
In addition, adversarial attacks can even theoretically be used to ensure privacy. A clever engineer may soon create a device that tricks mass surveillance systems into mistaking surrounding conversations as complete silence just by emitting soft background noise. For even if an eavesdropper manages to record your conversations, efficiently searching through petabytes of unstructured raw audio requires automatic conversion into written language: exactly the process that these adversarial attacks aim to disrupt.
We are not quite there yet. Carlini & Wagner’s attack does not work when played over the air, because speakers distort the subtle noise patterns that comprise the attack. In addition, unlike their counterpart for image recognition, the attacks against speech-to-text models must be customized for each segment of audio, a process that cannot yet be done in real time. All the same, it only took a few years of research to extend Szegedy’s initial image-recognition attacks into significantly more powerful deceptions. If adversarial attacks for speech develop as quickly as they did for images, Carlini and Wagner's results might be a cause for concern.
Citation
For attribution in academic contexts or books, please cite this work as
Hugh Zhang, "Speech recognition systems are now vulnerable to adversarial attacks", The Gradient, 2018.
BibTeX citation:
@article{hzhang2018adversarialspeech,
author = {Zhang, Hugh},
title = {Speech recognition systems are now vulnerable to adversarial attacks},
journal = {The Gradient},
year = {2018},
howpublished = {\url{https://thegradient.pub/adversarial-speech/ } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}