
Some objects grab our attention when we see them, even when we are not exactly looking for them. How precisely does this happen? And, more importantly, how can we incorporate this phenomena to improve our computer vision models? In this article, I will explain the process of paying attention to salient (i.e. noticeable) objects in the visual scene and their applications in Machine Learning as an AI researcher (or not only from the neuroscience perspective).
Visual perception, saliency, and attention have been active research topics in neuroscience for decades. The discoveries and advancements that these researchers have made have helped AI researchers understand and mimic the process(es) in the human brain. Indeed, saliency and attention are active research topics in the AI community, too. The outcome is a wide spectrum of applications ranging from better language understanding to autonomous driving. But before we can understand the AI perspective on attention, we’ll first have to understand it from the neuroscience perspective.
Visual Attention in Human Brain
Although attention has been well studied throughout the decades, prominent research scientist Grace Lindsay has described attention as being “far from a clear or unified concept" [1]. However, all researchers agree on some attributes of attention and its effects on informa- tion processing in the brain. Therefore we can generalize that attention is a control process that efficiently utilizes limited computational resources. This control process is demonstrated either overtly or covertly.
In overt attention, one can see how a person locates fovea (i.e. the area on the retina of the eye where visual acuity is highest) on a visually perceived area through saccades (i.e. the quick, simultaneous movement of both eyes between two or more phases of fixation in the same direction) as explained by Yarbus in 1967 [2]. In covert attention, the brain weighs some information it perceives more than others without moving fovea [3]. Classical theory of attention claims attention is a separate control mechanism from sensory input control [4], [5]. On the other hand, the premotor theory of attention claims these attention and sensory input control originated from the same process [6].
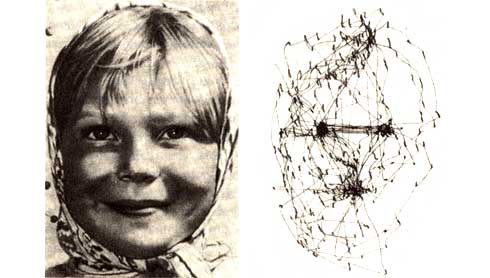
The debate continues (e.g. [7]), and we can continue to go deep in exploring how the brain forms attention. However, from an AI perspective, we have enough material to play with. We have attention as to how the brain selects a subset of the information it perceives to process using importance. And, the importance is described by saliency (i.e. the quality of being particularly noticeable).
We can construct saliency from bottom-up, i.e. a region that stimulates us through color, direction, and intensity and we put our fovea onto that region, or top-down, i.e. we select to attend a subset of input based on its importance. The importance is defined by the context of the task. For more details please see Koch and Ullman’s seminal work [8] or [9].
Attention in Machine Learning
The importance weighing process of attention is intuitive from a machine learning perspective. Not all parts of the input (or encoded input, extracted features, embedding, etc.) have the same importance in generating (decoding) expected output.
The very first example of the application of this concept is Bahdanau et al. [10]. In this paper, we see extracted features are not directly fed into the decoding network. Instead, features are scored and a context vector is set up with weighted features based on that score. The resulting network is "attending" some words in a sentence, more than other words, based on the context of the expected word. Sounds similar to what we learned from neuroscience, but there is no vision involved here. Let’s see some examples of attention mechanisms in computer vision applications.
In the computer vision field, one of the pioneering works of attention mechanism is Mnih et al. [11]. This paper is more likely what we read before, selecting and processing a subset of the input, yet achieving to predict the correct output. Indeed, what they developed is a glimpse sensor that mimics saccades (i.e. eyes quick changes of gaze between fixations). The glimpse sensor stochastically selects smaller subregions of the input image as a sequence. The extracted regions are fed into a recurrent network to come up with a prediction. The model is trained with Reinforcement Learning.
The problem of stochastic selection of subregions is that it requires sampling and as many readers will know it is harder to train sampling-based models than deterministic and differentiable models. This form of attention mechanism is known as "hard-attention". The deterministic method to compute attention is called "soft-attention".
One of the earliest deterministic attention mechanism examples is Xu et al. [12]. Indeed, they have demonstrated both hard-attention and soft-attention mechanisms in their paper. In this work, they generated a caption of an image by attending parts of the image. They also used Bahdanau’s attention mechanism, i.e. computing weights of all extracted input features by scoring and forming a context vector by the weighted sum of these features. The resulting network with a soft-attention mechanism is trained with back-propagation since the attention mechanism is differentiable.
Later in 2017, we saw a breakthrough in the NLP field, by constructing a network just using an attention mechanism. This work is known by the name "transformers" by Vaswani et al. [13]. The title says enough: "attention is all you need". The concept gave birth to a family of transformers: BERT [14], GPT-2 [15] and GPT-3 [16]. The same transformer concept was also realized in computer vision by Jaderberg et al. [17]. Some more works in this early area of attention mechanism in ML can be found in [18] and [19].
Although saliency is a well-studied field in computer vision since Itti et al. [9:1] and saliency map definition made a while ago by Simonyan et al. [20], saliency prediction using attention mechanisms are new [21], [22].
Attention mechanism also finds its place in generative models. One of the earliest examples in generative models is DRAW [23] and AIR [24]. Then many other papers came out from the same line of work like RATM [25], HART [26] or more recently, SCALOR [27] and SPACE [28]. All of these papers involve spatial attention.
Last, as shameless self-promotion, I proposed a model that attended salient features in driving vision to predict braking in my Ph.D. thesis. My main motivation was to simplify autonomous driving or driver assistance systems with a holistic vision approach [29], [30].
Now let’s dive into how the attention mechanism evolved from inception to this day.
The Start
I assume the start of attention mechanisms in machine learning with the paper "Neural Machine Translation by Jointly Learning to Align and Translate" by Bahdanau, Cho and Bengio [10:1]. I will explain another attention mechanism approach in computer vision, but the mainstream attention mechanism (which is very popular nowadays) first appeared in this paper.
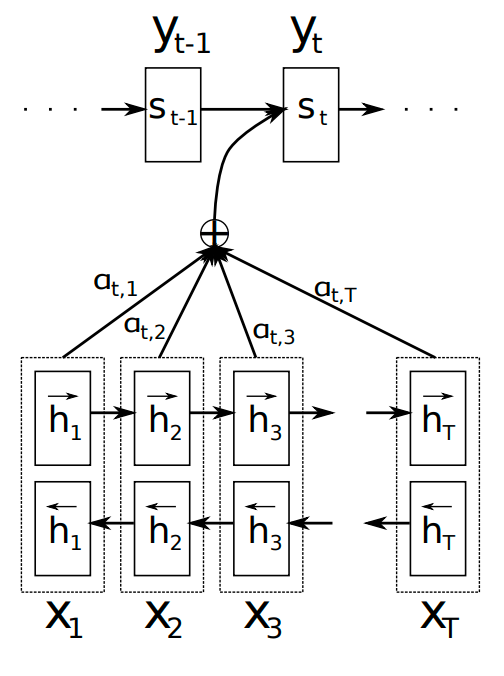
Neural Machine Translation models usually adopt a form of encoder-decoder architecture. An NMT model encodes input text into a fixed-length vector, then its decoder uses this vector to generate translation. The model then learns how to align this vector to desired translation.
In their paper, Bahdanau et al. proposed a new model that searches positions in the source sentence while generating a word in translation. The key here is how the search is done.
The paper uses the term "soft" regarding how this search is done. Let’s see what it means. We first encode input as usual to create annotations (or embedding) hi. Then, before decoding, we create something called context vector ci. The context vector is actually weighted sum of annotations:
$$
c_i = \sum_{j=1}^{T_x}{\alpha_i}{h_i}
$$
$\alpha_i$ computed using softmax of $e_{ij}$, where $e_{ij}$ is:
$$e_{ij} = a(s_i−1, h_i)$$
Here is the "soft" part: $a(.)$ is the scoring function and implemented as a feed-forward simple neural network. Therefore, the entire context vector ci can be trained by a back-propagating gradient from the cost function.
So this paper showed us how to attend to a subset of input. Moreover, the model can be trained using back-propagation. This form of attention is known as "soft" attention.
Attention in Computer Vision
In Computer Vision, the idea of attending subsets of input is tempting, since it is also biologically plausible. The very first paper containing the attention idea is Mnih et al. [11:1]. However, this form of attention is known as "hard" attention, and I have to explain it. This time, the key idea is saccade.
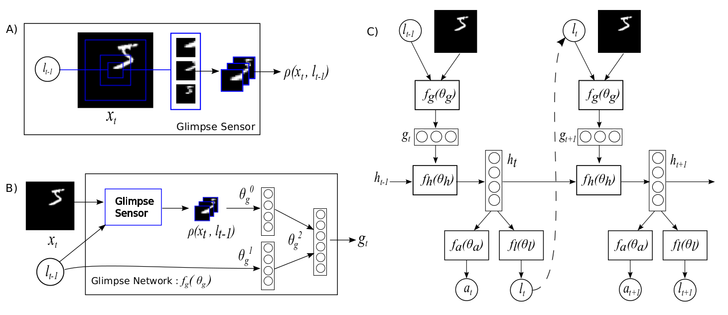
Biologically, we move our fovea (i.e. the area at our retina where acuity is the highest) quickly. This phenomenon is known as the saccade. In their paper, Mnih et al. proposed a model that mimics this behavior. Their Recurrent Attention Model has a Glimpse Sensor that focuses onto a subset of the input image recurrently. Therefore, the model uses only a subset of the input image, rather than using its entirety, to predict MNIST digits.
Later, Ba et al. [18:1] proposed an enhanced hard-attention model for multi- ple object recognition. Their DRAM (Deep Recurrent Attention Model) uses optimizing ELBO (i.e. using Variational Inference techniques) for training and the authors explain how this is identical to REINFORCE algorithm [31] used by Mnih et al.
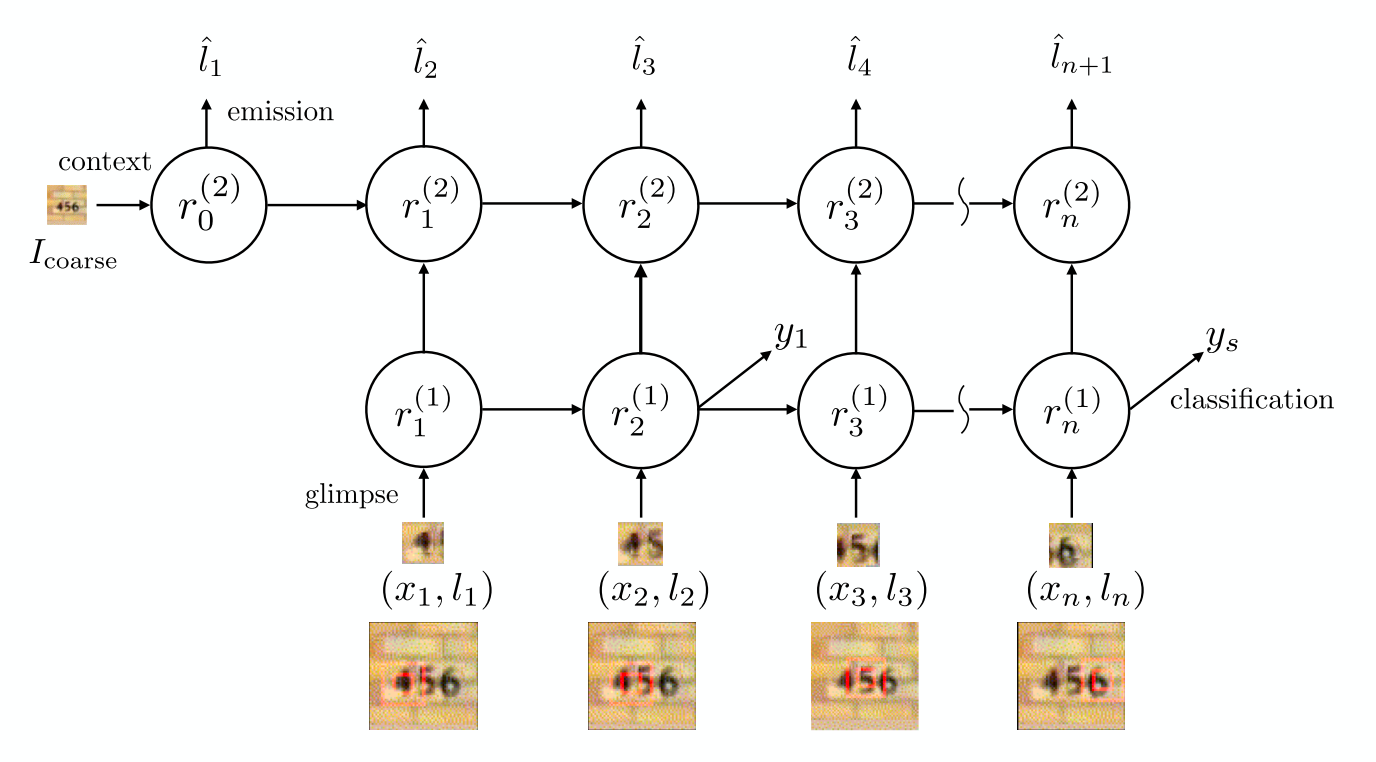
The problem with the hard-attention model is obvious now: they need VI or Sampling which is usually harder to train than gradient back-propagation (i.e.differentiable) algorithms. This is explained in Xu et al. paper [12:1] in which authors show both soft and hard attention models. Their model generated a caption for the input image by attending sub-regions of the input image. Their soft-attention-based model uses Bahdanau’s scoring where the hard-attention version uses REINFORCE.
Although there is a lot of paper to cover attention in computer vision, the most prominent one came in 2017 titled "Attention is All You Need" by Vaswani et al. [13:1]. Let’s see why this is important in the next section.
Breakthrough: Transformers
Although I’ve covered transformers in detail in my blog post, I’ll cover it quickly here, too. So fasten your seat belts. The main reason I skip a good amount of great papers in soft-attention models is that they are all similar: they are using encoder-decoder architecture in which they learn to attend to a subset of input using a scoring system. Then the transformer came in. The major difference in the transformer is, it gets rid of the recurrent network, and uses only "self- attention".
The self-attention reduces computational complexity and it can learn longer dependencies among input. Self-attention has a constant O(1) time in sequential operations where recurrent layers have O(n) where n is the length of the input token set. Also, it does not maintain the order of sequence of the input, so it can learn longer dependencies than recurrent models.
By the way, self-attention means, we maintain an attention matrix among input tokens themselves. The model learns in which tokens it should attend for the token in the current time step.
This simple but radical idea has utterly transformed the entire Deep Learning landscape over the past few years. We now have BERT [14:1], GPT-2 [15:1] and GPT-3 [16:1]. The same transformer concept was also realized in computer vision by Jaderberg et al. [17:1] and most recently, Vision Transformer by Dosovitskiy et al. [32].
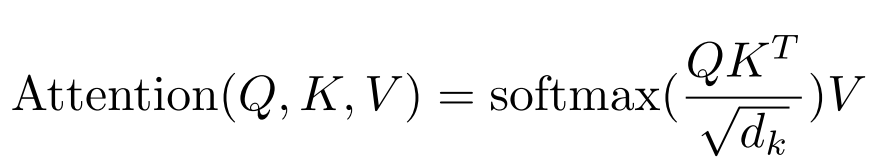

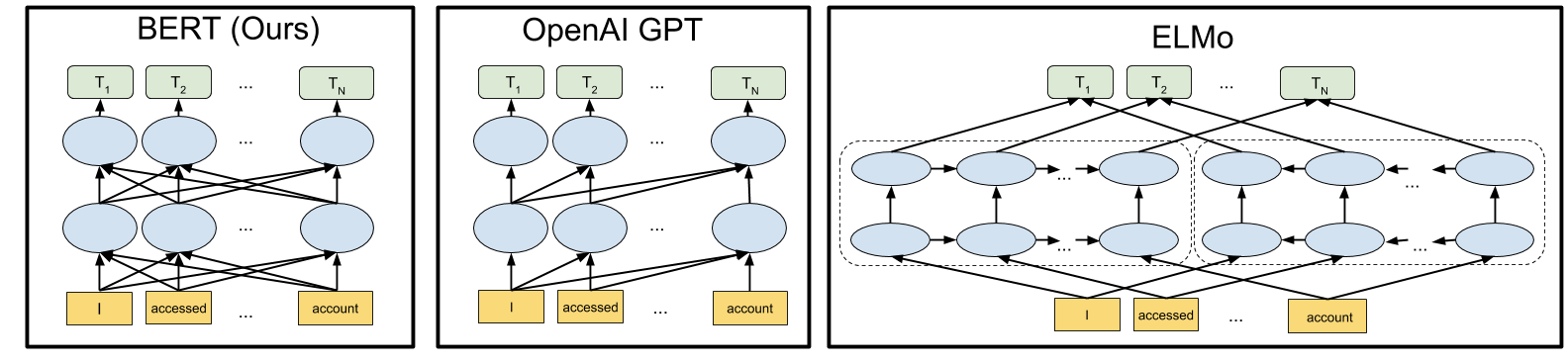
Now the transformer became mainstream and the model of choice. On the other hand, there is another interesting line of work in generative models. Now let’s see how attention is applied in generative models.
Attention in Generative Models
Recently, the Variational Auto-encoders (or VAEs for short) [33], which is a mix of deep learning and variational inference (VI), became popular in generative modeling. Variational inference is an alternative to the sampling (e.g. Monte Carlo) approach where the objective is to maximize ELBO (the evidence lower bound) so our model can better approximate the original input distribution.
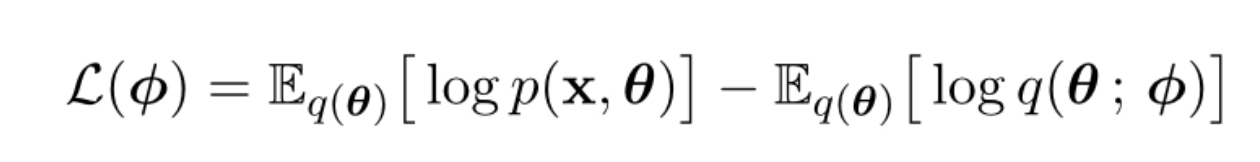
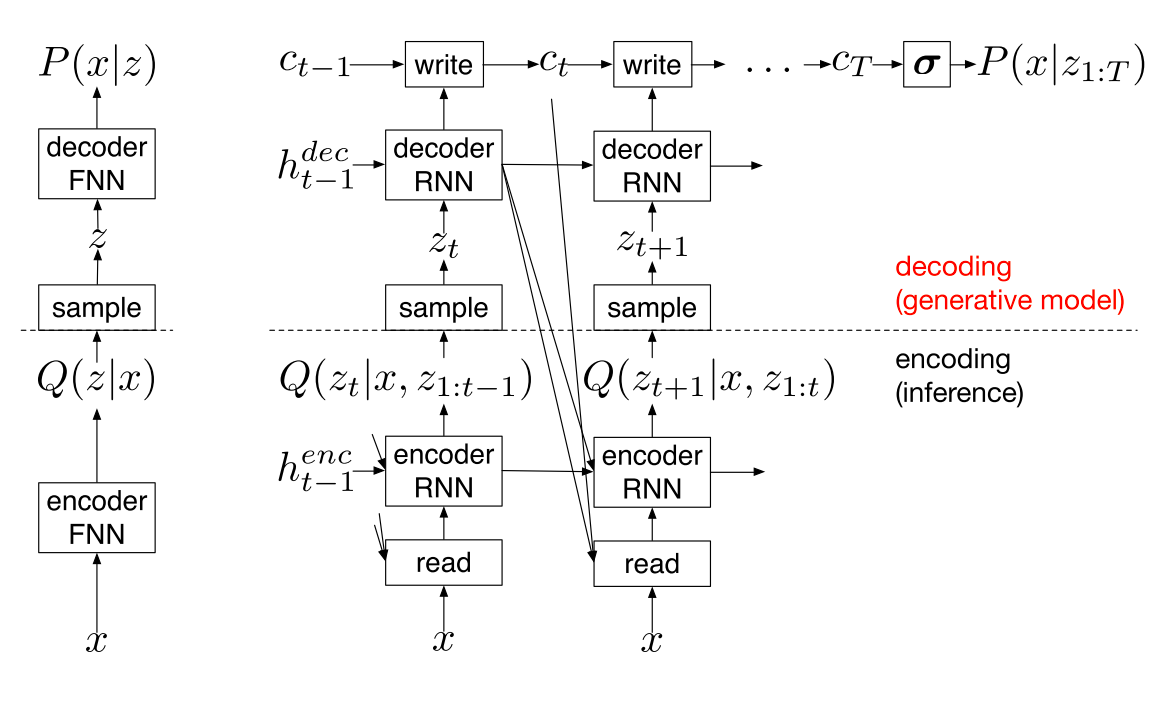
Previously, I’ve mentioned hard-attention models use a sampling approach (which is therefore not differentiable), especially the REINFORCE algorithm, and Ba et al. [18:2] proposed a VI based training algorithm for a hard-attention model. The DRAW model by Gregor et al. [23:1], which is a member of the VAE family, proposes a differentiable VI-based model that sequentially attends to a subset of input to generate the input image, instead of a single pass.
Later, Attend-Infer-Repeat (or AIR) by Eslami et al. [24:1] proposed better- structured representations than DRAW or VAEs. Therefore it is performing well on learning good representations in a structured way (i.e. vision as inverse graphics), without supervision.
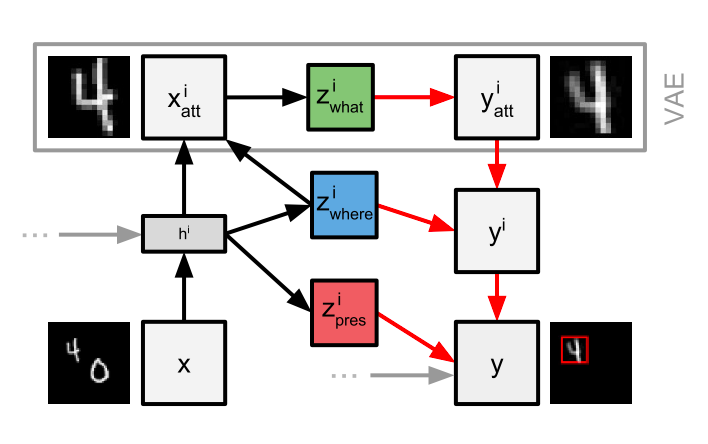
On the other hand, AIR is not scalable therefore it is enhanced by SQAIR (Sequential Attend-Infer-Repeat) [34], SPAIR (Spatially Invariant Attend, Infer, Repeat) [35] as well as HART (Hierarchical Attentive Recurrent Tracking) [26:1], and RATM (Recurrent Attentive Tracking Model) [25:1] for object representations and object tracking between sequences.
Conclusion
Although the exact mechanism of attention (either in an overt or covert form) is still unknown in neuroscience, this does not stop us, AI researchers, from mimicking the demonstrated features of attention. Moreover, the motivating part is the attention-based models are achieving state-of-the-art in almost all areas.
In conclusion, based on the successful results of attention-based models, we will expect to see more attention-based models in near future. More importantly, the more we learn from neuroscience, the better ML methods and models we can build. In the end, the human brain is still the golden standard of intelligence.
Grace W. Lindsay. Attention in Psychology, Neuroscience, and Machine Learning. Frontiers in Computational Neuroscience, 14:29, 4 2020. ↩︎
Alfred L Yarbus. Eye movements and vision. Springer, 2013. ↩︎
Laurent Itti and Christof Koch. A saliency-based search mechanism for overt and covert shifts of visual attention. In Vision Research, volume 40, pages 1489–1506, 6 2000. ↩︎
Michael I. Posner. Attention: The mechanisms of consciousness. Proceed- ings of the National Academy of Sciences of the United States of America, 91(16):7398–7403, 8 1994. ↩︎
Michael I. Posner and Stanislas Dehaene. Attentional networks. Trends in Neurosciences, 17(2):75–79, 1 1994. ↩︎
Giacomo Rizzolatti, Lucia Riggio, Isabella Dascola, and Carlo Umiltá. Re- orienting attention across the horizontal and vertical meridians: Evidence in favor of a premotor theory of attention. Neuropsychologia, 25(1, Part 1):31–40, 1987. ↩︎
Thomas Parr and Karl J. Friston. Attention or salience? Current Opinion in Psychology, 29:1–5, 10 2019. ↩︎
Christof Koch and Shimon Ullman. Shifts in selective visual attention: towards the underlying neural circuitry. In Matters of intelligence, pages 115–141. Springer, 1987. ↩︎
Laurent Itti, Christof Koch, and Ernst Niebur. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(11):1254–1259, 1998. ↩︎ ↩︎
Dzmitry Bahdanau, Kyunghyun Hyun Cho, and Yoshua Bengio. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv e-prints, page arXiv:1409.0473, 9 2014. ↩︎ ↩︎
Volodymyr Mnih, Nicolas Heess, Alex Graves, and Koray kavukcuoglu. Re- current models of visual attention. Advances in Neural Information Pro- cessing Systems, 3(January):2204–2212, 2014. ↩︎ ↩︎
Kelvin Xu, Jimmy Lei Ba, Ryan Kiros, Kyunghyun Cho, Aaron C Courville, Ruslan Salakhutdinov, Richard S. Zemel, and Yoshua Bengio. Show, Attend and Tell: Neural Image Caption Generation with Visual At- tention. CoRR, abs/1502.0:2048–2057, 2015. ↩︎ ↩︎
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin, Lukasz Kaiser, Illia Polo- sukhin, Łukasz Kaiser, and Illia Polosukhin. Attention is All You Need. In Advances in Neural Information Processing Systems, volume 2017-Decem, pages 5999–6009. Neural information processing systems foundation, 2017. ↩︎ ↩︎
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota, 6 2019. Association for Computational Linguistics. ↩︎ ↩︎
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language Models are Unsupervised Multitask Learners. 2019. ↩︎ ↩︎
Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Ka- plan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language Models are Few-Shot Learners. 2020. ↩︎ ↩︎
Max Jaderberg, Karen Simonyan, Andrew Zisserman, and Koray Kavukcuoglu. Spatial Transformer Networks. In C Cortes, N D Lawrence, D D Lee, M Sugiyama, and R Garnett, editors, Advances in Neural In- formation Processing Systems 28, volume 2015-Janua, pages 2017–2025. Curran Associates, Inc., 2015. ↩︎ ↩︎
Jimmy Lei Ba, Volodymyr Mnih, and Koray Kavukcuoglu. Multiple ob- ject recognition with visual attention. In 3rd International Conference on Learning Representations, ICLR 2015 - Conference Track Proceedings, pages 1–10. International Conference on Learning Representations, ICLR, 12 2015. ↩︎ ↩︎ ↩︎
Kyunghyun Cho, Aaron Courville, and Yoshua Bengio. Describing Multi- media Content Using Attention-Based Encoder-Decoder Networks. IEEE Transactions on Multimedia, 17(11):1875–1886, 11 2015. ↩︎
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside con- volutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034, 2013. ↩︎
Marcella Cornia, Lorenzo Baraldi, Giuseppe Serra, and Rita Cucchiara. Predicting human eye fixations via an LSTM-Based saliency attentive model. IEEE Transactions on Image Processing, 27(10):5142–5154, 10 2018. ↩︎
Wenguan Wang, Qiuxia Lai, Huazhu Fu, Jianbing Shen, and Haibin Ling. Salient Object Detection in the Deep Learning Era: An In-Depth Survey. ArXiv, abs/1904.0, 2019. ↩︎
Karol Gregor, Ivo Danihelka, Alex Graves, Danilo Jimenez Rezende, Daan Wierstra, Danihelka@google Com, Danilo Jimenez Rezende, and Daan Wierstra. DRAW: A Recurrent Neural Network For Image Generation. In Francis Bach and David Blei, editors, Proceedings of the 32nd Inter- national Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pages 1462–1471, Lille, France, 2015. PMLR. ↩︎ ↩︎
S. M. Ali Eslami, Nicolas Heess, Theophane Weber, Yuval Tassa, David Szepesvari, Koray Kavukcuoglu, and Geoffrey E. Hinton. Attend, Infer, Repeat: Fast Scene Understanding with Generative Models. In Advances in Neural Information Processing Systems, pages 3233–3241. Neural infor- mation processing systems foundation, 3 2016. ↩︎ ↩︎
Samira Ebrahimi Kahou, Vincent Michalski, Roland Memisevic, Christo- pher Pal, and Pascal Vincent. RATM: Recurrent Attentive Tracking Model. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, volume 2017-July, pages 1613–1622. IEEE Com- puter Society, 8 2017. ↩︎ ↩︎
Adam R Kosiorek, Alex Bewley, and Ingmar Posner. Hierarchical attentive recurrent tracking. In Advances in Neural Information Processing Systems, volume 2017-Decem, pages 3054–3062, 2017. ↩︎ ↩︎
Jindong Jiang, Sepehr Janghorbani, Gerard de Melo, and Sungjin Ahn. SCALOR: Generative World Models with Scalable Object Representations. In Proceedings of ICLR 2020. OpenReview.net, 10 2020. ↩︎
Zhixuan Lin, Yi-Fu Wu, Skand Vishwanath Peri, Weihao Sun, Gautam Singh, Fei Deng, Jindong Jiang, and Sungjin Ahn. SPACE: Unsupervised Object-Oriented Scene Representation via Spatial Attention and Decom- position. In International Conference on Learning Representations, 2020. ↩︎
Ekrem Aksoy, Ahmet Yazıcı, and Mahmut Kasap. See, Attend and Brake: An Attention-based Saliency Map Prediction Model for End-to-End Driv- ing. arXiv e-prints, page arXiv:2002.11020, 2 2020. ↩︎
E Aksoy and A Yazici. Attention Model for Extracting Saliency Map in Driving Videos. In 2020 28th Signal Processing and Communications Applications Conference (SIU), pages 1–4, 2020. ↩︎
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3-4):229–256, 5 1992. ↩︎
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Min- derer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. 9 2020. ↩︎
Diederik P Kingma and Max Welling. Auto-encoding variational bayes. In 2nd International Conference on Learning Representations, ICLR 2014 - Conference Track Proceedings, 2014. ↩︎
Adam R. Kosiorek, Hyunjik Kim, Ingmar Posner, and Yee Whye Teh. Se- quential attend, infer, repeat: Generative modelling of moving objects. In Advances in Neural Information Processing Systems, volume 2018-Decem, pages 8606–8616. Neural information processing systems foundation, 6 2018. ↩︎
Eric Crawford and Joelle Pineau. Spatially Invariant Unsupervised Object Detection with Convolutional Neural Networks. Proceedings of the AAAI Conference on Artificial Intelligence, 33(01):3412–3420, 7 2019. ↩︎
Author Bio
Ekrem Aksoy is an AI/ML Researcher. His research interests are machine learning, computer vision, computational neuroscience and attention mechanisms. He received his PhD from Eskisehir Osmangazi University. He currently works as senior software engineer at GEOTAB Inc. You can find his blog on Medium and follow him on Linkedin.
Citation
For attribution in academic contexts or books, please cite this work as
Ekrem Aksoy, "Attention in the Human Brain and Its Applications in ML", The Gradient, 2021.
BibTeX citation:
@article{aksoyattention2021,
author = {Aksoy, Ekrem},
title = {Attention in the Human Brain and Its Applications in ML},
journal = {The Gradient},
year = {2021},
howpublished = {\url{https://thegradient.pub/attention-in-human-brain-and-its-applications-in-ml/} },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.



{kind=link}
{kind=link}
{kind=link}
{kind=link}