
This piece was the winner of the inaugural Gradient Prize.
Introduction
AI systems are compute-intensive: the AI lifecycle often requires long-running training jobs, hyperparameter searches, inference jobs, and other costly computations. They also require massive amounts of data that might be moved over the wire, and require specialized hardware to operate effectively, especially large-scale AI systems. All of these activities require electricity — which has a carbon cost. There are also carbon emissions in ancillary needs like hardware and datacenter cooling [1].
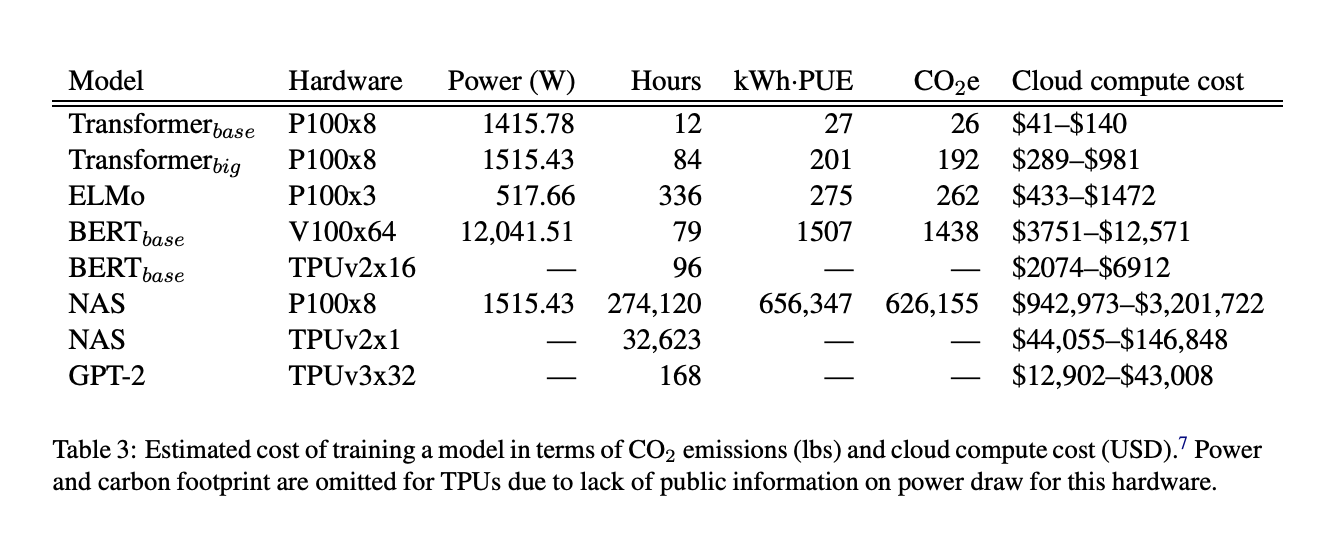
Source: Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and policy considerations for deep learning in NLP. arXiv preprint arXiv:1906.02243.
Thus, AI systems have a massive carbon footprint[2]. This carbon footprint also has consequences in terms of social justice as we will explore in this article. Here, we use sustainability to talk about not just environmental impact, but also social justice implications and impacts on society[3]. Though an important area, we don’t use the term sustainable AI here to mean applying AI to solve environmental issues. Instead, a critical examination of the impacts of AI on the physical and social environment is the focus of our discussion.
The impacts are only growing as we inch towards ever larger models to deliver the wonders of intelligent capabilities used in modern technology. For example, compute consumption of high-compute AI systems (of their time) is doubling every 3.4 months [4] (perhaps even faster today!). Though this gives us an upper bound for the pace of compute consumption, paying attention to the choice of models, location of datacenters, and training schedule can alleviate the carbon emissions of the process[5]. Even so, in many cases, there is little value to be gained from the use of such large systems where smaller systems might suffice[6] — or, situations where we can achieve similar results without requiring the use of AI at all.
Source: https://openai.com/blog/ai-and-compute/
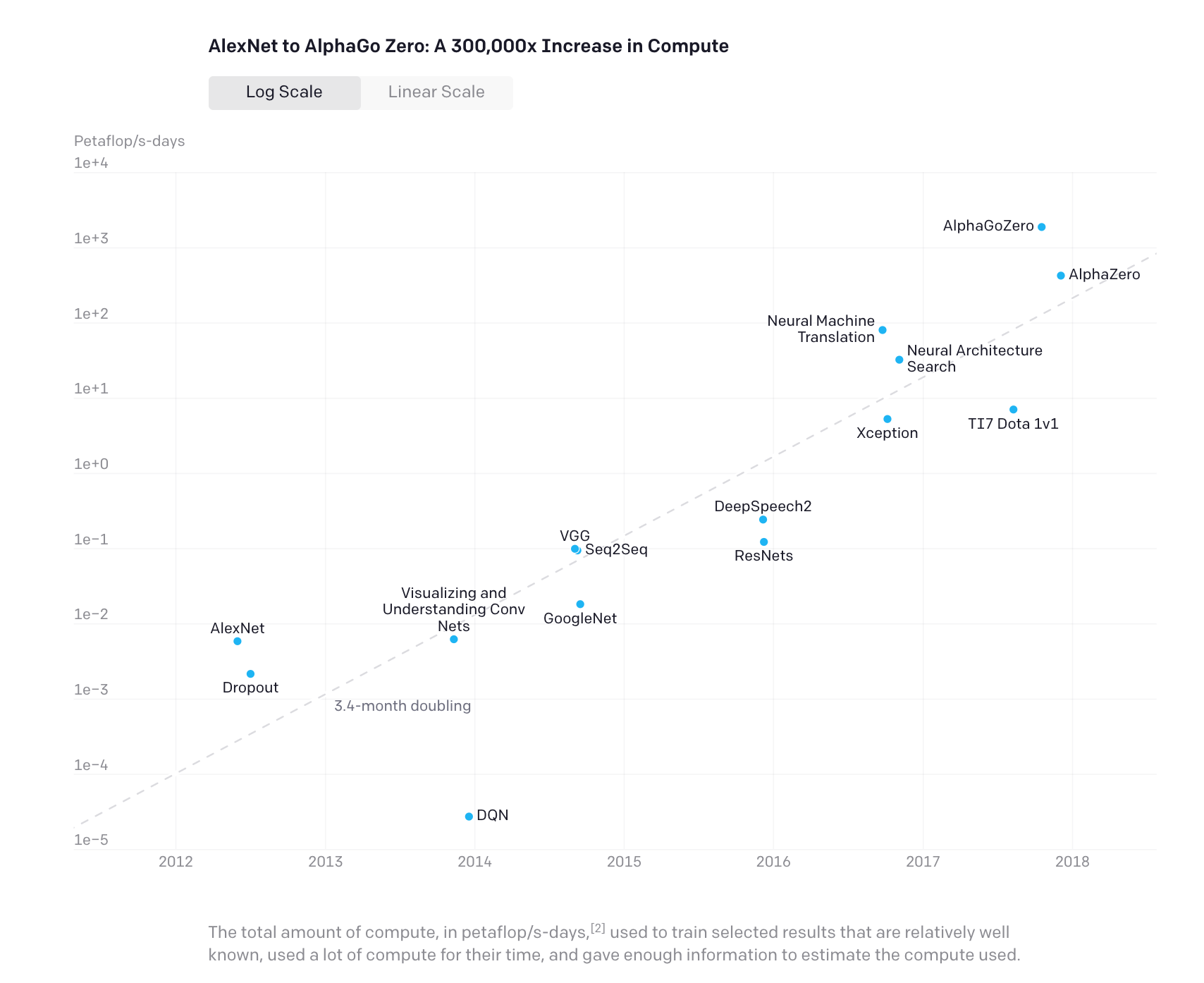
We are firmly in the paradigm of large-scale models today. GPT-3[7] is a popular example, but there are many others like Turing-NLG[8] and Switch Transformer[9] that use more than a trillion parameters to deliver state-of-the-art (SOTA) results on various cognitive tasks. These are certainly very impressive engineering achievements and push the envelope in terms of performance on benchmark tasks. But, such SOTA improvements can come up at very high carbon costs: for example, Parcollet and Ravanelli show that a SOTA Transformer emits 50% of its total training released CO2 solely to achieve a final decrease of 0.3 of the word error rate[10].
Such a paradigm also comes with many other challenges: biases[11], memorization and subsequent privacy leaks[12], vulnerability to adversarial attacks[13], and prohibitive training costs. With such models being made available through public APIs for broader consumption[14], these problems are propagated downstream to application developers and researchers where provenance is obscured and agency is limited in being able to affect change. The recent formulation of large-scale models as “foundation models”[15] also underscores the potential proliferation of these problems in coming months and years.
Sustainable AI can be thought of as another dimension along which we can guide the development of AI systems in addition to typical functional and business requirements. As van Wynsberghe elucidates, “Sustainable AI is a movement to foster change in the entire lifecycle of AI products (i.e. idea generation, training, re-tuning, implementation, governance) towards greater ecological integrity and social justice.”[16] There are two important considerations that jump out from this that we must take into account: Sustainable AI can allow us to (1) achieve social justice when we utilize this approach, and (2) especially so when these systems operate in an inherently socio-technical context. Indeed, a harmonized approach accounting for both societal and environmental considerations in the design, development, and deployment of AI systems[17] can lead us to gains that support the triple bottom line: profits, people, and planet.
There are immediate next steps that we can take to improve the environmental posture of the AI systems that we build: normalizing the practice of carbon accounting for AI systems, implementing basic instrumentation and telemetry to gather the necessary data, and making carbon impacts a core consideration alongside functional and business requirements.
A holistic approach that takes into account the business and functional needs at the same time boosts the likelihood that measures to be more green in our AI lifecycle will be taken up by both researchers and practitioners.
Challenges with the current paradigm
There are several challenges with our current approach to AI, resulting in intertwined environmental and societal implications.
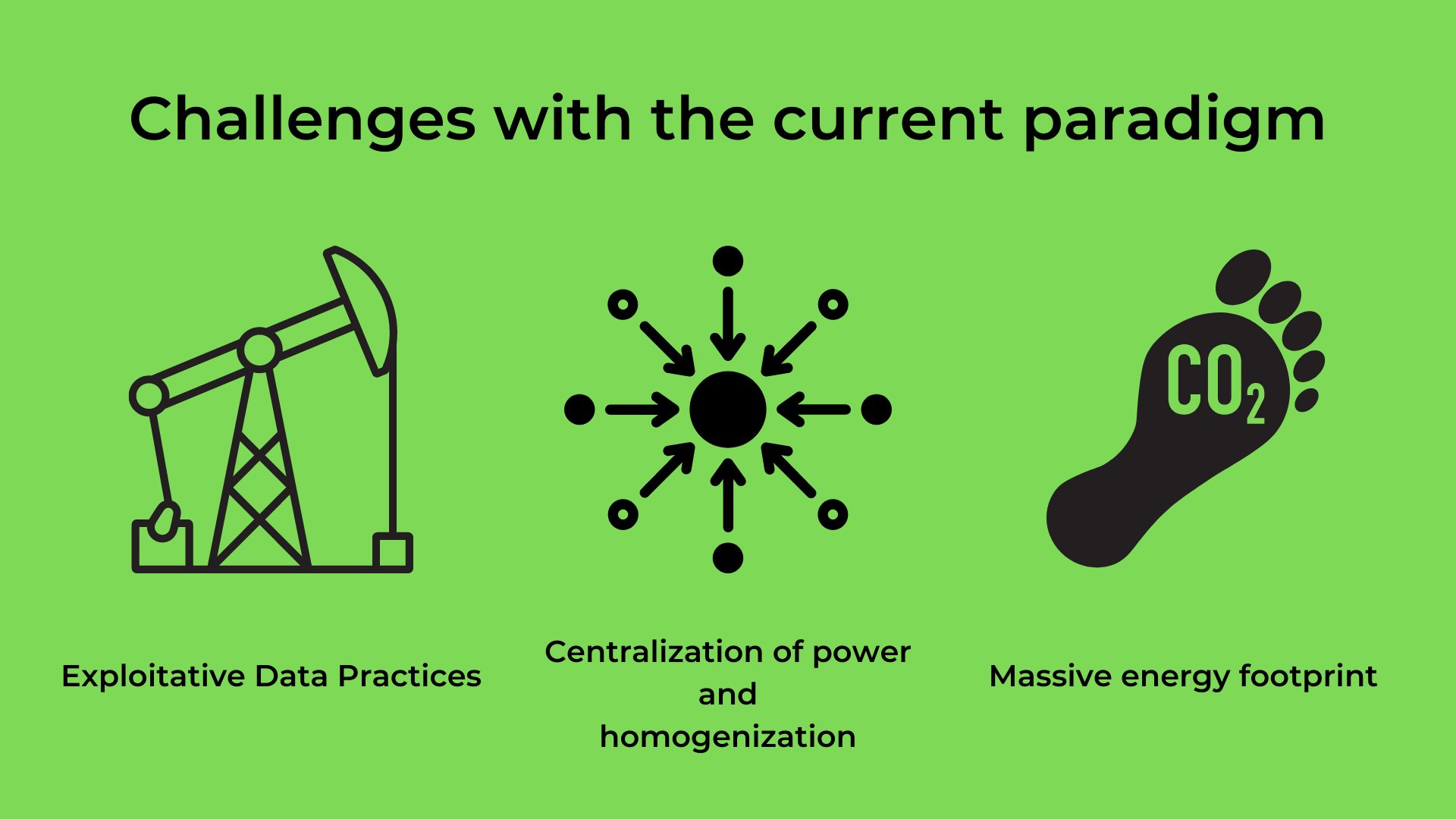
Exploitative Data Practice
Large-scale models are impossible to build, at least in the current paradigm of supervised machine learning, without access to correspondingly large-scale datasets. Such datasets often carry ethical implications: lack of informed consent in their construction and subsequent use[18]; inability to withdraw consent; and the difficulty of remedying issues like fairness, privacy violations, and incorrect labels. These issues often fall down the dependency chain in the application and research use of these datasets, which makes it nearly impossible to make post-hoc corrections once a dataset has been released. Data is often gathered from public sources like the Internet without clear guidelines on how such data should be gathered in the first place, and whether such guidelines would even be followed if they are made available to researchers and practitioners[19]. With the COVID-19 pandemic, we saw the repurposing of face datasets by adding masks[20] to power up facial recognition technology which was previously an effective counterattack against[21] the power of automated surveillance. Data collected in large quantities can yield itself to a variety of purposes that can’t all be imagined a priori, hence, encouraging such exploitative data practices can have significant negative impacts in the long-run.
Massive energy footprints
While the environmental impacts of AI systems have been in discussion for a few years now, following in the tradition of thinking about the environmental impacts of computing in general[22],”On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?🦜”[23] brought the idea into public consciousness due to both the dangers of those large models in terms of their environmental costs, but more so because of their severe negative societal impacts. In the field of NLP, “Energy and Policy Considerations for Deep Learning in NLP”[24] showed us how the environmental impact of training a single, large NLP model could approach that of the carbon emissions of 5 cars over their entire lifetime. While there aren’t any standardized and widely accepted methodologies for assessing the carbon impacts of computing yet[25], there are various approaches that recommend metrics like run-duration, FLOPs, wall energy consumption, and even financial costs as a carbon proxy. What is evident from the numerous studies and initiatives around the world trying to help us grasp the environmental impacts of AI is that neither is this a simple problem, nor are narrow metrics enough to make an accurate assessment. In fact, just as the field of Responsible AI has embraced the idea of thinking about the entire AI lifecycle[26], we need to account for the environmental impacts of AI all the way through to the hardware and the supply chain[27] that help create the necessary infrastructure to power these systems. Such a lifecycle perspective on design of products and services has been quite effective in other fields[28].
There is a tremendous urgency in addressing our carbon footprints, particularly since climate change looms large as highlighted in the Sixth Assessment Report (AR6 WG1)[29] from the Intergovernmental Panel on Climate Change (IPCC). There is still hope that corrective actions can steer us away from climate disaster. Natural market forces and current practices will not change on their own and without concerted effort, we risk continuing down this path realizing some of the worst-case scenarios highlighted in the report. As datacenters rise up in their share of the ICT sector’s emissions, which rivals that of the entire airline industry[30], it behooves us to pay more immediate attention for where we can be more green in our approach with designing, developing, and deploying AI systems.
Centralization of power and homogenization
The largest societal impact of not using sustainable AI systems is that it creates a strong degree of inequity. The world of AI research and application is already heavily skewed towards particular demographics and regions of the world[31]. In addition, the influence of well-funded non-academic organizations also looms large over the field[32].
When we veer away from sustainable AI systems, we entrench those gaps further. Only those with the financial resources to train large models, requiring massive amounts of data, can spend millions of dollars to share and publish their systems. This helps them spin their data and AI flywheels faster[33] by building more performant products that offer better quality of service to users, who will then want to stick around on those products and services, share more data, and allow those organizations to train even more performant systems. This increases the barrier to entry for smaller firms who don’t have the ability to obtain such large troves of data, don’t have the financial resources to train such large systems, nor have the operational expertise to deploy and maintain these systems. The specialized knowledge required to operate such systems at scale presents challenges at each and every stage of the AI lifecycle[34]. The net effect of all these challenges is that incumbents can build ever deeper moats making it difficult for new entrants to alter the degree of competitiveness in the market.
Source: https://ml-ops.org/content/end-to-end-ml-workflow
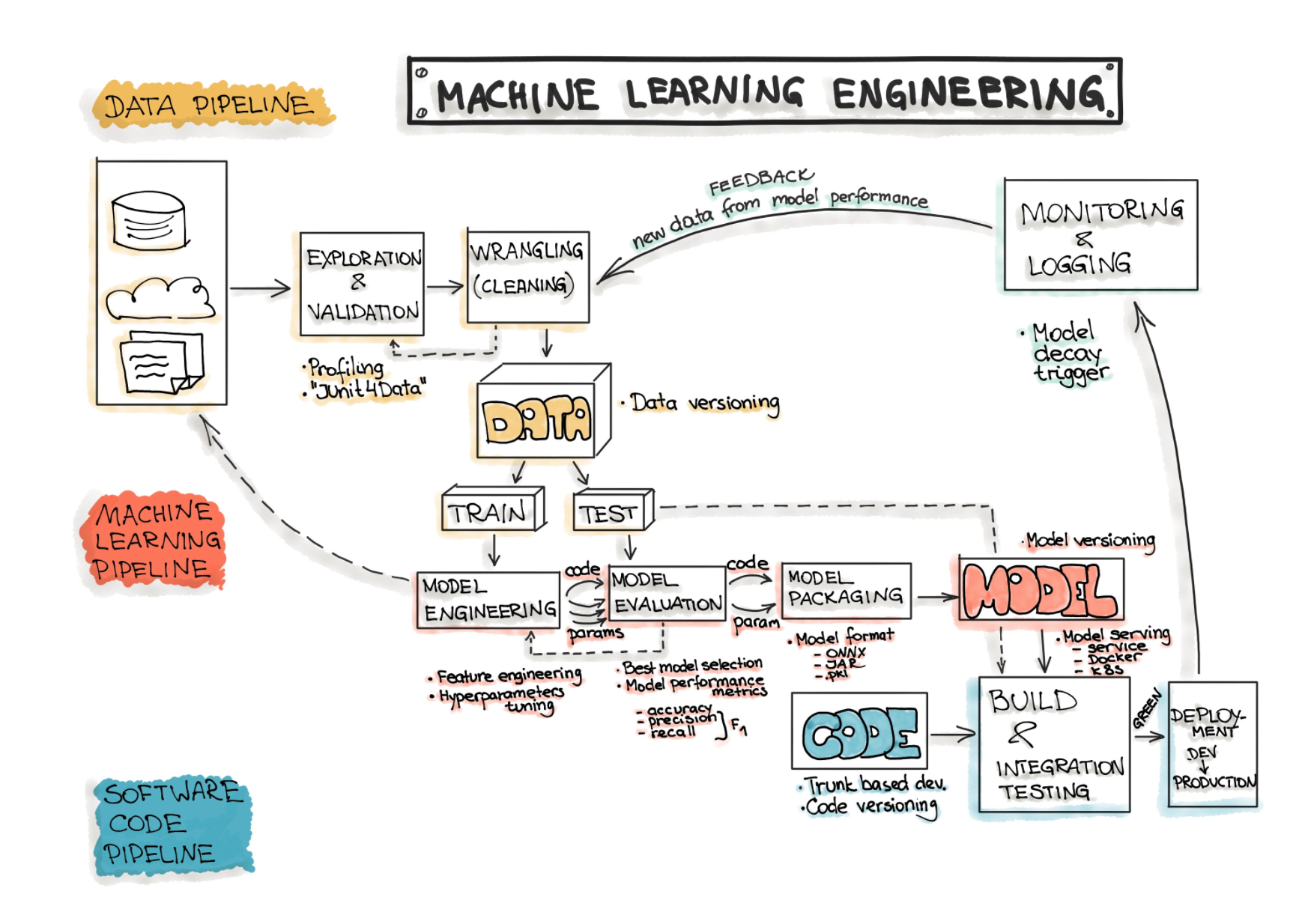
On the research front, the same problem persists with well-funded labs having access to the necessary compute hours on large clusters to allocate to their researchers who can then run more extensive searches for more performant systems, iterate faster, and produce more meaningful results which they can then publish at top-tier conferences and journals. This again spins a flywheel enabling them to raise more funding for their projects by pointing to evidence of a stellar publishing record. Given the very scarce nature of academic funding and long, arduous grant cycles, this effect is pernicious in a very subtle way over the long-term in terms of diversity of ideas that are germinated and nurtured in the academic landscape.
Finally, the operational costs when leasing these resources on-demand from cloud providers can be prohibitive to those who reside in areas outside of North America and Europe. This further exacerbates the above problems. In particular, this is the case when we talk about using AI as a potential solution to address societal challenges. We can’t meaningfully believe that AI can be a force for good[35] unless we empower local populations to build systems for themselves through equitable access to these fundamental resources.
What is Sustainable AI?
While not a panacea by any means, sustainable AI provides a cohesive framework to gather together various efforts to help mitigate the negative environmental and societal impacts of AI systems as they are designed, developed, and deployed today.
There are a few approaches that stem from the sustainable AI mindset that we can leverage to address the challenges outlined before. These include elevating smaller models, choosing alternate deployment strategies, and choosing optimal running time, location, and hardware to make the systems carbon-aware and carbon-efficient.
Elevating smaller models
There are several research initiatives that are exploring how to train models faster and more efficiently that rely on pruning[36], compression[37], distillation[38], and quantization[39] among other techniques with the goal of shrinking down the size of the models and utilizing fewer compute cycles which have direct implications on the financial and environmental costs of building and deploying AI systems.
With the proliferation of edge computing and IoT devices, which have limited resources for memory and computation, the field of TinyML[40] has also seen a lot of uptake. For example, with devices that have RAM sizes in KBs, model size can be minimized along with prediction costs using approaches like Bonsai[41] that proposes a shallow, sparse tree-based algorithm. Another approach, called ProtoNN, is inspired by kNN but uses minimal computation and memory to make real-time predictions on resource-constrained devices[42]. Novel domain-specific languages like SeeDot[43], which expresses ML-inference algorithms and then compiles that into fixed points, makes these systems amenable to run on edge-computing devices.
Alternate deployment strategies
One of the major components of the environmental footprint of AI systems is the embodied carbon in the hardware that is required to run these systems. There are three strategies here that can be applied to mitigate these impacts: (1) use specialized hardware[44] like ASICs and TPUs to accelerate the run times of these jobs (provided the embodied carbon is amortized over a long period of usage), (2) obtain higher utilization rates on existing hardware[45] preventing idle power consumption and sub-optimal computational processing distribution, and (3) optimizing the use of existing hardware like general-purpose CPUs[46] instead of specialized hardware which means that we reduce the demand for manufacturing new hardware to a certain extent. Each approach comes with tradeoffs but choosing the appropriate hardware platform to run jobs can result in significant carbon savings.
Federated learning ,a technique where training happens in a decentralized manner across multiple devices without the training data leaving those devices can be used as an alternative approach which can help to provide privacy protections[47] by keeping data on-device; additionally, it can enable the compute-intensive part of the AI lifecycle to be pushed (potentially) to regions where carbon intensity is low mitigating the carbon costs of that AI system[48]. Such a strategy helps us achieve two goals with the same change.
Carbon-efficiency and carbon-awareness
Carbon-efficiency is the idea that on both the software and the hardware level, we optimize for getting the most value, the output that we desire from the system, per unit of computation and subsequently energy that is expended to achieve that value. Smaller models and alternate deployment strategies can help us achieve carbon-efficiency as does carbon-awareness.
Carbon awareness means adapting the operational parameters of the AI system to meet the state of the grid supplying the energy in a way that the most opportune times and locations can be picked dynamically to minimize the carbon footprint of the system. The differences in carbon intensity of the energy used to power the infrastructure behind AI systems is shown to have wide disparities, sometimes even as much as a 30x difference between the most polluting regions in USA and the least polluting regions in Canada[49]. This has implications in terms of where we choose to train our AI systems and where they are deployed. This is possible through tools provided by cloud providers like the Azure Sustainability Calculator[50] and through internal load balancing and distribution performed by cloud providers to achieve their own sustainability goals[51].
What can you do next?
Large-scale AI systems and the current paradigm will not change or disappear overnight. But, what is critical is that we continue to explore these sustainable AI approaches in parallel and help to steer our community towards a more sustainable practice. Elevating these approaches as equals to the current approaches will help to jointly optimize for business, functional, and environmental considerations.
In trying to address societal and environmental impacts of our activities, inertia looms large and it can feel overwhelming to get started. There are some easy ways to get started on your journey to building more sustainable AI systems.
Share the idea of sustainable AI widely
We can begin first by sharing this idea of sustainable AI with our own communities of research and practice. Normalizing the accounting[52] and reporting[53] of the carbon impacts of AI systems through mechanisms like making it a soft requirement for conference and journal publications is a great first step. This has precedent in the form of “broader impact statements” that are making their way to top-tier ML conferences[54]. This will create a virtuous cycle of practice and reward enabling a transition into “Green AI”, AI systems that are built and used with the awareness of their carbon impact, as opposed to “Red AI”[55], AI systems that are built and used with only performance goals in mind ,which is currently favored and supported in the research and practice ecosystem. Actions that you can take as researchers include creating requirements for workshops that you host at these conferences to have submissions that provide an environmental report with applicants’ paper and presentation submissions. For practitioners in industry, providing information about the environmental impact of the product or service in an easily digestible manner to the end-consumer can help them make more informed choices. If you lead teams or hold a management position in industry, supporting such efforts from your rank and file employees is a great first step in giving them the necessary cover to experiment with what works and what doesn’t in sharing this information with consumers.
Instrument your AI systems to gather telemetry
“You can’t manage what you can’t measure”, from Peter Drucker, aptly captures a key requirement to get started on the sustainable AI journey: effective carbon accounting of AI systems[56]. Instrumenting our current AI systems to capture and report back energy consumption data will provide us with the raw insights that can help make smarter decisions about what actions we should take to make changes to move towards sustainable AI systems. Code-based tools like CodeCarbon[57], carbontracker[58], experiment-impact-tracker[59], and scaphandre[60] are great places to start. Some even offer integration with existing AI lifecycle management tooling like CometML[61], making it even easier to get started. As a researcher, you can encourage the use of such tools in the research and operations of your lab. As you become familiar with these tools, you can make them a normalized practice and part of the lab induction process and playbook for new members joining your lab as well. In industry, we are spoilt for choice with a variety of tooling, yet sometimes constrained by existing organizational mandates or just accepted practices. As a practitioner, you can share your experiences on using these tools, writing up blog posts for what works and what doesn’t and sharing those at brown-bag sessions to bolster adoption within your teams and developer ecosystems. For those holding management positions, encouraging this kind of experimentation through rewards and positive feedback in the performance reviews can jolt the technical teams in the organization to fast-track adoption and experimentation to find the right tools that help you meet your environmental commitments through greener AI systems.
Make carbon impacts a core consideration alongside functional and business requirements
Building sustainable AI systems is not just about doing right by people and our planet. Consumers are becoming more informed about the environmental impacts of the products and services they use. This has a direct impact on the business[62] where consumers vote with their actions of choosing products and services from organizations that have greener solutions.
Running a greener version of your systems has definite financial cost savings in most scenarios, which helps to make a strong business case for organizations adopting a sustainable AI approach. But, even in cases where the financial tradeoff is not clear with this new approach, there are long-term benefits in securing a competitive market position as an organization that is prepared to change their ways of working, building, and delivering solutions to meet their ESG commitments. As we observed with the launch of the GDPR and subsequent pressure for organizations to conform to stricter norms with data processing, organizations that took these challenges head on stood to benefit in an increasingly competitive marketplace[63].
While there is no certificate or standardized way yet to report on the environmental impact of software systems, much less so AI systems, work from organizations like the Green Software Foundation[64] towards presents a determined path forward in creating an interoperable and actionable approach that can inform consumers to make meaningful choices as they seek green solutions. Regulators and policymakers might also seek to leverage policy recommendations[65] based on standardization work in the interest of nudging the AI ecosystem towards more sustainable practices.
For each of the areas above, we’ve seen recommended actions for researchers, industry practitioners, and those holding management positions. As we ratchet up our commitments and actions on all these levels, we can create collective action at a broader level whose impact will start making itself felt more widely across our field.
Conclusion
We became familiar with the large carbon footprint of AI systems that manifests throughout their lifecycle, from the hardware used to power it, through training, and the inference phases. Such an environmental impact is inextricably linked to the societal impacts of AI systems with respect to issues of bias, privacy, inequity, and concentration of power at large. Sustainable AI offers an approach that harmonizes these issues and presents a potential pathway to addressing these challenges in a holistic fashion keeping in mind our planet, organizational profits, and above all, people at the center of the design, development, and deployment phases of an AI system. We can push forward on making sustainable AI a reality by starting to share this idea widely, instrumenting our systems to gather telemetry data, and making carbon impacts a core consideration alongside functional and business requirements.
References
Itoh, S., Kodama, Y., Shimizu, T., Sekiguchi, S., Nakamura, H., & Mori, N. (2010, October). Power consumption and efficiency of cooling in a Data Center. In 2010 11th IEEE/ACM International Conference on Grid Computing (pp. 305-312). IEEE. ↩︎
Lacoste, A., Luccioni, A., Schmidt, V., & Dandres, T. (2019). Quantifying the carbon emissions of machine learning. arXiv preprint arXiv:1910.09700. ↩︎
Cowls, J., Tsamados, A., Taddeo, M., & Floridi, L. (2021). The AI Gambit—Leveraging artificial intelligence to combat climate change: Opportunities, challenges, and recommendations. Challenges, and Recommendations (March 15, 2021). ↩︎
Patterson, D., Gonzalez, J., Le, Q., Liang, C., Munguia, L. M., Rothchild, D., ... & Dean, J. (2021). Carbon emissions and large neural network training. arXiv preprint arXiv:2104.10350. ↩︎
Frankle, J., & Carbin, M. (2018). The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv preprint arXiv:1803.03635. ↩︎
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165. ↩︎
https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/ ↩︎
Fedus, W., Zoph, B., & Shazeer, N. (2021). Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961. ↩︎
Parcollet, T., & Ravanelli, M. (2021). The Energy and Carbon Footprint of Training End-to-End Speech Recognizers. ↩︎
Abid, A., Farooqi, M., & Zou, J. (2021). Persistent anti-muslim bias in large language models. arXiv preprint arXiv:2101.05783. ↩︎
Carlini, N., Liu, C., Erlingsson, Ú., Kos, J., & Song, D. (2019). The secret sharer: Evaluating and testing unintended memorization in neural networks. In 28th {USENIX} Security Symposium ({USENIX} Security 19) (pp. 267-284). ↩︎
Akhtar, N., & Mian, A. (2018). Threat of adversarial attacks on deep learning in computer vision: A survey. Ieee Access, 6, 14410-14430. ↩︎
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., ... & Wang, W. (2021). On the Opportunities and Risks of Foundation Models. arXiv preprint arXiv:2108.07258. ↩︎
van Wynsberghe, A. (2021). Sustainable AI: AI for sustainability and the sustainability of AI. AI and Ethics, 1-6. ↩︎
Gupta, A., Lanteigne, C., & Kingsley, S. (2020). SECure: A Social and Environmental Certificate for AI Systems. arXiv preprint arXiv:2006.06217. ↩︎
Peng, K., Mathur, A., & Narayanan, A. (2021). Mitigating dataset harms requires stewardship: Lessons from 1000 papers. arXiv preprint arXiv:2108.02922. ↩︎
Thomas, D. R., Pastrana, S., Hutchings, A., Clayton, R., & Beresford, A. R. (2017, November). Ethical issues in research using datasets of illicit origin. In Proceedings of the 2017 Internet Measurement Conference (pp. 445-462). ↩︎
Wang, Z., Wang, G., Huang, B., Xiong, Z., Hong, Q., Wu, H., ... & Liang, J. (2020). Masked face recognition dataset and application. arXiv preprint arXiv:2003.09093. ↩︎
Harmon, R. R., & Auseklis, N. (2009, August). Sustainable IT services: Assessing the impact of green computing practices. In PICMET'09-2009 Portland International Conference on Management of Engineering & Technology (pp. 1707-1717). IEEE. ↩︎
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021, March). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?🦜. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (pp. 610-623). ↩︎
Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and policy considerations for deep learning in NLP. arXiv preprint arXiv:1906.02243. ↩︎
Lannelongue, L., Grealey, J., & Inouye, M. (2020). Green Algorithms: Quantifying the carbon emissions of computation. arXiv e-prints, arXiv-2007. ↩︎
Gupta, A. (2021). Making Responsible AI the Norm rather than the Exception. arXiv preprint arXiv:2101.11832. ↩︎
Crawford, K., & Joler, V. (2018). Anatomy of an AI System. Retrieved August, 31, 2021. ↩︎
Giudice, F., La Rosa, G., & Risitano, A. (2006). Product design for the environment: a life cycle approach. CRC press. ↩︎
IPCC, 2021: Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change [Masson-Delmotte, V., P. Zhai, A. Pirani, S.L. Connors, C. Péan, S. Berger, N. Caud, Y. Chen, L. Goldfarb, M. I. Gomis, M. Huang, K. Leitzell, E. Lonnoy, J. B.R. Matthews, T. K. Maycock, T. Waterfield, O. Yelekçi, R. Yu and B. Zhou (eds.)]. Cambridge University Press. In Press. ↩︎
Jones, N. (2018). How to stop data centres from gobbling up the world's electricity. Nature, 561(7722), 163-167. ↩︎
Zhang, D., Mishra, S., Brynjolfsson, E., Etchemendy, J., Ganguli, D., Grosz, B., ... & Perrault, R. (2021). The ai index 2021 annual report. arXiv preprint arXiv:2103.06312. ↩︎
Abdalla, M., & Abdalla, M. (2021, July). The Grey Hoodie Project: Big tobacco, big tech, and the threat on academic integrity. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society (pp. 287-297). ↩︎
Gurkan, H., & deVericourt, F. (2020). Contracting, pricing, and data collection under the AI flywheel effect. ↩︎
Paleyes, A., Urma, R. G., & Lawrence, N. D. (2020). Challenges in deploying machine learning: a survey of case studies. arXiv preprint arXiv:2011.09926. ↩︎
https://ssir.org/articles/entry/artificial_intelligence_as_a_force_for_good ↩︎
Lym, S., Choukse, E., Zangeneh, S., Wen, W., Sanghavi, S., & Erez, M. (2019, November). PruneTrain: fast neural network training by dynamic sparse model reconfiguration. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (pp. 1-13). ↩︎
Neill, J. O. (2020). An overview of neural network compression. arXiv preprint arXiv:2006.03669. ↩︎
Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531. ↩︎
Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., … & Kalenichenko, D. (2018). Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2704-2713). ↩︎
Banbury, C. R., Reddi, V. J., Lam, M., Fu, W., Fazel, A., Holleman, J., ... & Yadav, P. (2020). Benchmarking TinyML systems: Challenges and direction. arXiv preprint arXiv:2003.04821. ↩︎
Kumar, A., Goyal, S., & Varma, M. (2017, July). Resource-efficient machine learning in 2 kb ram for the internet of things. In International Conference on Machine Learning (pp. 1935-1944). PMLR. ↩︎
Gupta, C., Suggala, A. S., Goyal, A., Simhadri, H. V., Paranjape, B., Kumar, A., … & Jain, P. (2017, July). Protonn: Compressed and accurate knn for resource-scarce devices. In International Conference on Machine Learning (pp. 1331-1340). PMLR. ↩︎
Gopinath, S., Ghanathe, N., Seshadri, V., & Sharma, R. (2019, June). Compiling kb-sized machine learning models to tiny iot devices. In Proceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation (pp. 79-95). ↩︎
Nurvitadhi, E., Sim, J., Sheffield, D., Mishra, A., Krishnan, S., & Marr, D. (2016, August). Accelerating recurrent neural networks in analytics servers: Comparison of FPGA, CPU, GPU, and ASIC. In 2016 26th International Conference on Field Programmable Logic and Applications (FPL) (pp. 1-4). IEEE. ↩︎
Li, D., Chen, X., Becchi, M., & Zong, Z. (2016, October). Evaluating the energy efficiency of deep convolutional neural networks on CPUs and GPUs. In 2016 IEEE international conferences on big data and cloud computing (BDCloud), social computing and networking (SocialCom), sustainable computing and communications (SustainCom)(BDCloud-SocialCom-SustainCom) (pp. 477-484). IEEE. ↩︎
Vanhoucke, V., Senior, A., & Mao, M. Z. (2011). Improving the speed of neural networks on CPUs. ↩︎
Wei, K., Li, J., Ding, M., Ma, C., Yang, H. H., Farokhi, F., ... & Poor, H. V. (2020). Federated learning with differential privacy: Algorithms and performance analysis. IEEE Transactions on Information Forensics and Security, 15, 3454-3469. ↩︎
Yang, Z., Chen, M., Saad, W., Hong, C. S., & Shikh-Bahaei, M. (2020). Energy efficient federated learning over wireless communication networks. IEEE Transactions on Wireless Communications, 20(3), 1935-1949. ↩︎
https://appsource.microsoft.com/en-us/product/power-bi/coi-sustainability.sustainability_dashboard ↩︎
Radovanovic, A., Koningstein, R., Schneider, I., Chen, B., Duarte, A., Roy, B., ... & Cirne, W. (2021). Carbon-Aware Computing for Datacenters. arXiv preprint arXiv:2106.11750. ↩︎
https://branch.climateaction.tech/issues/issue-2/secure-framework/ ↩︎
Henderson, P., Hu, J., Romoff, J., Brunskill, E., Jurafsky, D., & Pineau, J. (2020). Towards the systematic reporting of the energy and carbon footprints of machine learning. Journal of Machine Learning Research, 21(248), 1-43. ↩︎
Nanayakkara, P., Hullman, J., & Diakopoulos, N. (2021). Unpacking the Expressed Consequences of AI Research in Broader Impact Statements. arXiv preprint arXiv:2105.04760. ↩︎
Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2019). Green ai. corr abs/1907.10597 (2019). arXiv preprint arXiv:1907.10597. ↩︎
https://devblogs.microsoft.com/sustainable-software/the-current-state-of-affairs-and-a-roadmap-for-effective-carbon-accounting-tooling-in-ai/ ↩︎
Anthony, L. F. W., Kanding, B., & Selvan, R. (2020). Carbontracker: Tracking and predicting the carbon footprint of training deep learning models. arXiv preprint arXiv:2007.03051. ↩︎
Koller, T., Nuttall, R., & Henisz, W. (2019). Five ways that ESG creates value. The McKinsey Quarterly. ↩︎
https://www.trustmark.org.uk/blogs/blogs-home/trustmark-blog/2018/11/13/6-surprising-benefits-that-gdpr-compliance-can-bring-to-your-business ↩︎
Taddeo, M., Tsamados, A., Cowls, J., & Floridi, L. (2021). Artificial intelligence and the climate emergency: Opportunities, challenges, and recommendations. One Earth, 4(6), 776-779. ↩︎
Author Bio
Abhishek Gupta is the Founder and Principal Researcher at the Montreal AI Ethics Institute, an international non-profit research institute with a mission to democratize AI ethics literacy. He works in Machine Learning and serves on the CSE Responsible AI Board Member at Microsoft where his work helps solve the toughest technical challenges of Microsoft’s biggest customers. Through his work as the Chair of the Standards Working Group at the Green Software Foundation, he is leading the development of a Software Carbon Intensity standard towards the comparable and interoperable measurement of the environmental impacts of AI systems. His work focuses on applied technical and policy measures for building ethical, safe, and inclusive AI systems, specializing in the operationalization of AI ethics and its deployments in organizations and assessing and mitigating the environmental impact of these systems. His work on community building has been recognized by governments from across North America, Europe, Asia, and Oceania. More information on his work is available here: https://atg-abhishek.github.io
Citation
For attribution in academic contexts or books, please cite this work as
Abhishek Gupta, "The Imperative for Sustainable AI Systems", The Gradient, 2021.
BibTeX citation:
@article{gupta2021sustainableai,
author = {Gupta, Abhishek},
title = {The Imperative for Sustainable AI Systems},
journal = {The Gradient},
year = {2021},
howpublished = {\url{https://thegradient.pub/sustainable-ai} },
}




{kind=link}
{kind=link}
{kind=link}
{kind=link}