Artificial neural networks and deep learning have taken center stage as the tools of choice for many contemporary machine learning practitioners and researchers. But there are many cases where you need something more powerful than basic statistical analysis, yet not as complex or compute-intensive as a deep neural network. History provides us with many approaches dating to the Multilayer Perceptron era. Yet many of these alternate methods languish in the shadows despite modern advances in enabling technologies. One such approach is called the associative memory.
Associative what?
Associative memories (AM) are pattern storage and retrieval systems inspired by the psychological concept of the same name. As demonstrated by key findings in learning and memory research, a given stimulus (object, shape, word) is stored as a memory in the brain, and is associated with related stimuli. When we experience stimuli that triggers an AM, we can recall memories associated with those inputs. Have you ever smelled and/or tasted a dish and recalled strong memories of other places and times? How about listening to an old song and remembering what you were doing when you first heard it? You hear the phrase, “One small step for man…”, and you can recall the rest of the quote. These are all examples of AM.
When applied to Computer Science problems, associative memories come in two high-level forms: autoassociative and heteroassociative memories. While both are able to recall patterns given a set of inputs, autoassociative memories are primarily focused on recalling a pattern X when provided a partial or noisy variant of X. By contrast, heteroassociative memories are able to recall not only patterns of different sizes from their inputs, but can be leveraged to map concepts between categories (hence “heteroassociative”). One common example from the literature is a heteroassociative memory that might recall the embedded animal concept of “monkey” given the embedded food concept of “banana". Since all forms of AM are focused on the actual content being stored and retrieved, they are also commonly referred to as content-addressable memories (CAM) in the literature.
Features of associative memories
While there have been many implementations, expansions, and improvements to the original AM systems, there are common features that current AMs also incorporate. Similar to artificial neural networks (ANNs), AMs include the representation of a neuron. Unlike a contemporary ANN, however, an AM neuron encompasses a kernel function that is usually not required to be differentiable, as most AM algorithms do not have a backpropagation step (although as we’ll see later, Kosko’s BAM may be an exception). Instead, AMs rely on weights that get updated during forward training passes through the neurons, often implementing a Hebbian style of learning. This allows some implementations to achieve one-shot or few-shot learning over relatively simple domains (Acevedo-Mosqueda, 2013). In contrast, most deep learning approaches are tuned using some combination of educated guesses, grid searches through hyperparameters, and practitioners’ intuition with no theoretical upper limit on training effort or network capacity. This often requires significant compute resources and time to fully explore. To be fair, auto-ML approaches are tackling this, but they take time and resources to train.
An interesting feature of several modern AM systems is the ability to “forget” older patterns with hyperparameter tuning. It follows that these systems are fully updateable as new training data is made available. This can become an important design consideration, as there are theoretical limits on the number of patterns any given AM can learn with high precision and recall. This is often a function of the number of neurons in the model (Hopfield, 1982; Chou, 1988; Acevedo-Mosqueda, 2013; Ritter & Sussner, 1998). Some herteroassociative memories also allow for relatively simple reverse traversal. Using the example above, you could train an AM to take “banana” as an input and return “monkey”, yet querying the AM in reverse with the concept of “monkey” results in one or more food concepts related to monkeys (e.g. “banana”) (Kosko, 1988). Other examples show how AMs can be optimized for temporal inference; provided a series of input patterns they are able to predict the following one or more patterns.
Research Milestones
In computer science, associative memories were first proposed by Karl Steinbuch (1961) in the form of the Lernmatrix. It would take several years before other researchers took up the concept and expanded on it (Willshaw et al, 1969; Kohonen, 1974), but the major breakthrough came with the introduction of both the discrete Hopfield network (Hopfield, 1982) and the expanded continuous variant (Hopfield, 1984). Subsequent research on Hopfield networks, in combination with the Multilayer Perceptron, laid the groundwork for most supervised machine learning research today. Below we explore a few of the highest-impact AM models and how they affected the state of the art.
The Lernmatrix
The Lernmatrix as described by Karl Steinbuch (Steinbuch, 1961) was a hardware AM proposal using ferromagnetic circuitry and overlapping connectors to provide a crude heteroassociative memory between inputs and a classification pattern. It laid out the concepts of using a matrix of weighted “values” with some set update weight to strengthen the connections between associated bits in the input and classification patterns. This approach laid the groundwork for future hardware and software AM architectures.

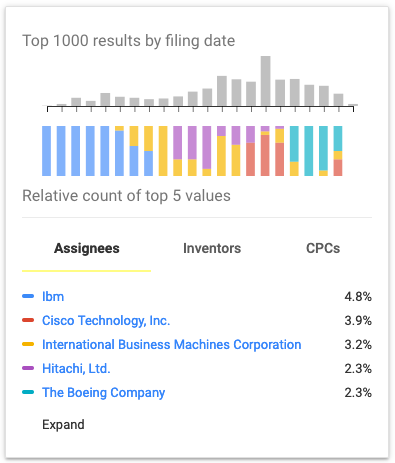
It does appear the Lernmatrix had a more immediate impact on hardware as patents referencing “associative memories” began to surface at about the same time, and have been the subject of continued interest in the context of modern systems. There has even been an attempt to develop a theoretical framework for the Lernmatrix as a basis for expanding the original architecture (Sánchez-Garfias, 2005).
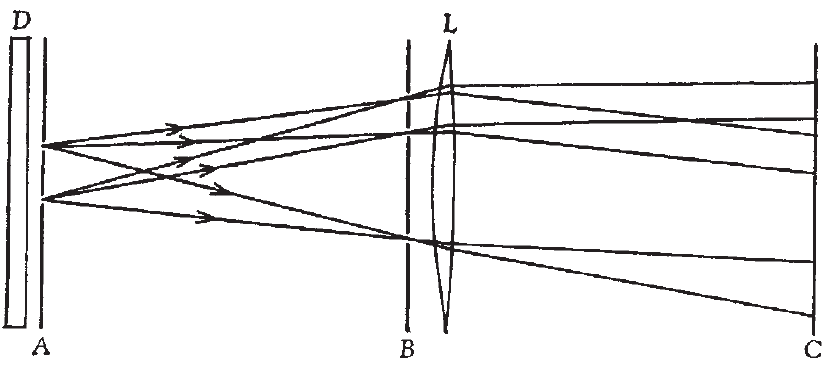
The Correlograph
Where Steinbuch was focused on persistent hardware memories and analog representations, D. J. Willshaw attempted to take known holographic pattern storage and retrieval theories of the time and expand the approach proposed in the Lernmatrix with holographic concepts. Wilshaw’s (1969) contribution became known as the correlograph or correlogram. The correlograph can be used to describe a simplistic neural network model that he referred to as an associative net. The Wilshaw model was the first to propose a quantitative approach to associative memory, emphasizing neuronal activation from paired stimuli and based on the McCulloch-Pitts (MCP) neuron model (McCulloch & Pitts, 1943). Wilshaw’s approach also proposed a theoretical upper limit for useful capacity and an approach that was resistant to noise in inputs.
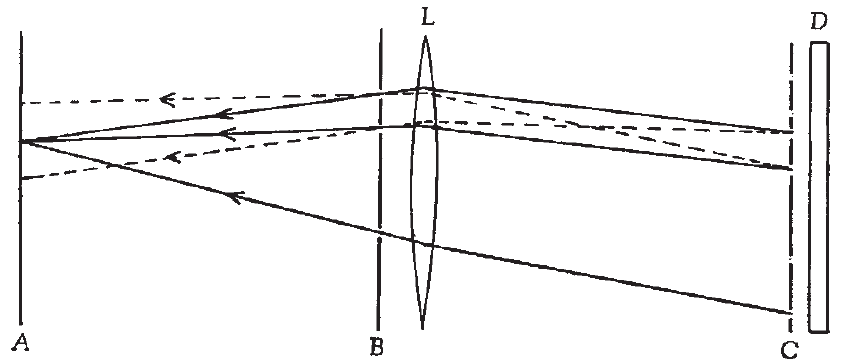

Hopfield Networks
While the Correlograph was a large step towards more efficient software implementations of the Lernmatrix, probably one of the most influential milestones in AM research was the advent of the Hopfield network (Hopfield, 1982). The original Hopfield network was a stochastic model that could learn discrete patterns by utilizing the memory capacity of Ising spin glasses (Ising, 1925; Wikipedia - Ising model, 2020) and energy flows mediated via the model weights. The Ising model was meant to move away from a purely “wire and fire” mechanism. A physical model based on energetics might allow us to take into account latencies and pattern reinforcement. The original Hopfield network also proposed an asynchronous update approach as opposed to a purely synchronous one, more closely mimicking biological neural activity. That being said, Hopfield himself suggested this was not particularly practical due to the compute limitations of the time. Hopfield also proposed a theoretical upper limit for non-degraded pattern storage and recall in his network is 0.15N where N is the number of neurons in the network. For example, if you wanted to store 15 patterns in a Hopfield network with acceptable degradation and strong resistance to noise, you would need at least 100 neurons. He also proposed a reasonable convergence iteration limit based on the stochastic update rate W { W | 0.0 ≤ W < 1.0}, which can achieve memory stability after ~4/W iterations through the entire pattern set.
In 1984, Hopfield proposed a continuous, deterministic version of the 1982 model that did away with the MCP neuron and used a new neuron similar to a Perceptron (Rosenblatt, 1957). This approach proved to be even more resilient to errors and supported continuous (as opposed to discrete) inputs, weights, and outputs. Most contemporary AM approaches are based at least in part on this variant of the Hopfield network. We also see its influence in modern ANNs with discrete or continuous inputs, weights, and outputs; Perceptron-inspired neurons; as well as energy-based optimization approaches like simulated annealing and gradient descent.
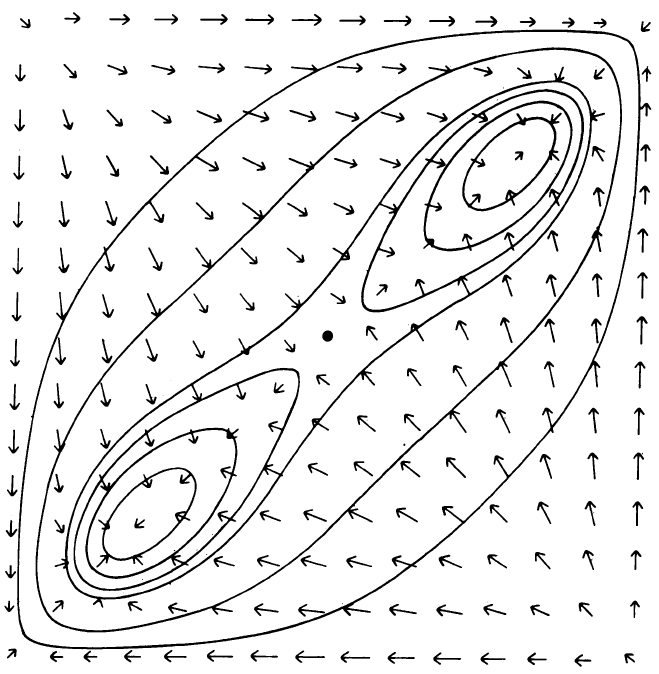
Bidirectional Associative Memories
Most AM research following Hopfield’s seminal works focused on either autoassociative or heteroassociative unidirectional approaches. When presented with a pattern pair (A, B), such networks can only be trained in one direction to produce B if A is provided as an input. Kosko introduced the bidirectional associative memory (BAM) which allowed learning of not only the A→B association, but also the B→A association (Kosko, 1988). This was achieved by transforming the conventional discrete binary value set {0, 1} to a bipolar form {-1, 1}, calculating a correlation matrix, and updating the AM weight matrix M with the correlation matrix. The result was an AM that could produce B when given A in the “forward” direction but could leverage the transpose of the weight matrix to also produce A when given B in a “backward” pass.
The BAM approach supports continuous inputs as long as the values can be transformed via a monotonic function whose derivative always yields a value ≧ 0. Another interesting feature of the BAM is the ability to forget pairs with a simple update to the weight matrix. Temporal patterns are also supported in both directions, so training a BAM with A1→A2→A3 (essentially A1→A2, A2→A3) can be traversed in reverse as A3→A2→A1. Due to the flexibility and rapid training allowed by the BAM model, it has been used as the base for many heteroassociative approaches since its inception. Conceptually, the use of forward and backward passes to reinforce the association between a pair of patterns is not dissimilar to modern BiLSTM and backpropagation approaches used in recurrent deep learning models.
Sparse Distributed Memories
At the same time Kosko was developing the BAM to address the unidirectional shortcomings of Hopfield-based AMs, Kanerva was working towards addressing the capacity issues. Hopfield network sizes (the number of neurons) are typically limited by the input and output vector sizes. For example, if input pattern A is always 10 bits, and output pattern B is always 10 bits, then the maximum number of neurons in a Hopfield network is 10 x 10 = 100 neurons (N). With a capacity of 0.15N, this means the network can only hold up to 0.15 x 100 ≈ 15 patterns before degradation becomes an issue. Kanerva (1988) proposed a mechanism by which the capacity of a Hopfield network could be scaled without severe performance degradation, independent of its stored pattern sizes. Kanerva named this approach Sparse Distributed Memory (SDM).
The premise for the SDM is that given a large enough virtual address space, the effective memory capacity can be increased. This increase in capacity corresponds to decreased collisions within a Hopfield network, while the virtual address space is mapped to a smaller physical address space via Hamming distance spheres. Shortly after Kanerva’s publication, Chou (1988) produced an exhaustive proof of the theoretical capacities and limitations of the Kanerva SDM. While framed as an artificial neural network, the incremental contributions over Hopfield do not constitute a trainable network. Rather, the Kanerva SDM is more a preprocessing function for the patterns to be stored and retrieved within the embedded Hopfield component (Keeler, 1986).
Several variants of the SDM approach appeared shortly after; some were independently discovered during the same timeframe, and others built on Kanerva’s work (1992):
- Jaeckel's Selected-Coordinate Design (Jaeckel, 1989a)
- Jaeckel's Hyperplane Design (Jaeckel, 1989b)
- Hassoun's Pseudorandom Associative Neural Memory (Hassoun, 1988)
- Adaptation to Continuous Variables by Prager and Fallside (Prager & Fallside, 1989)
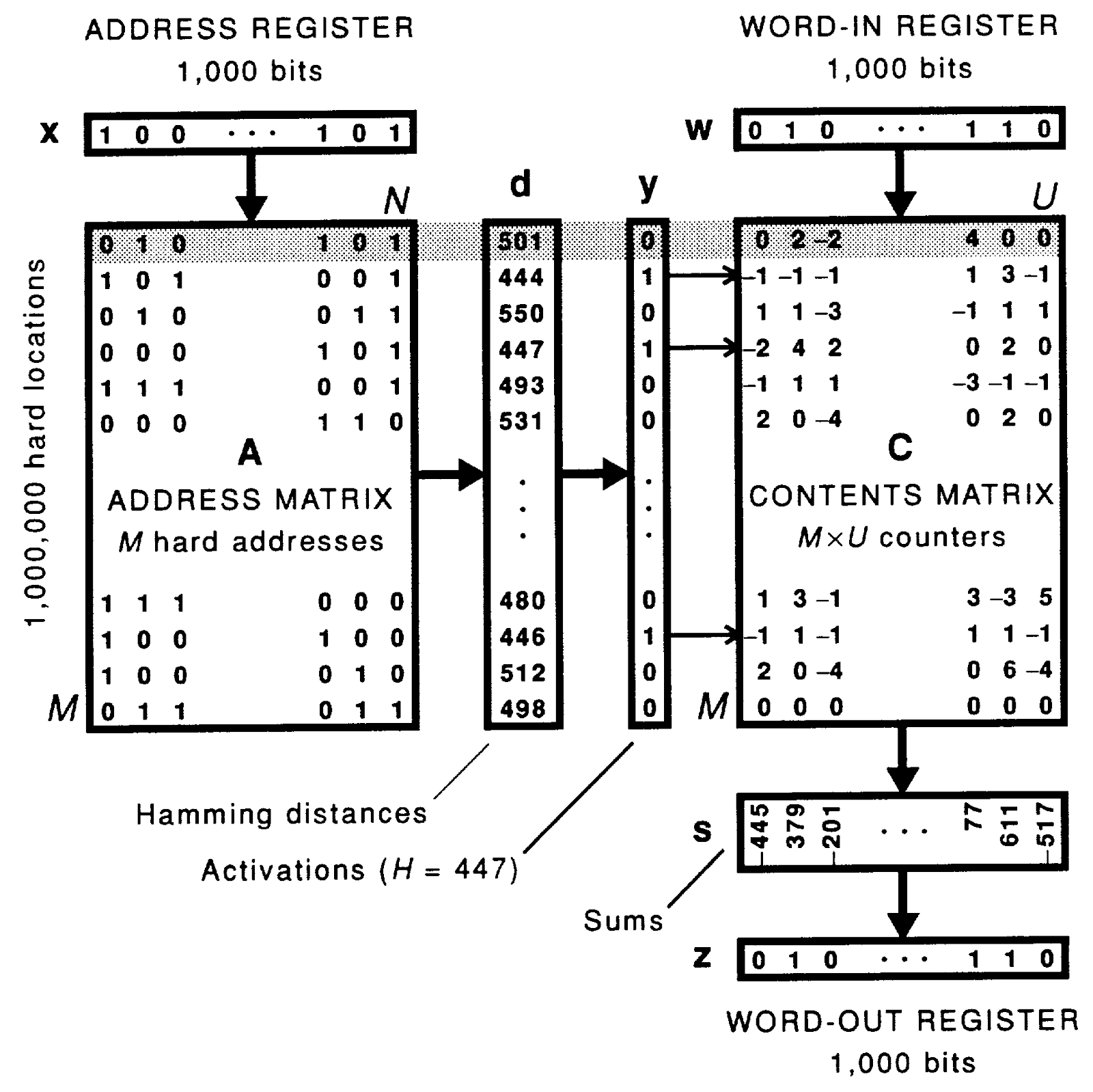
Morphological Associative Memories
So far most of the AM models we’ve explored have been based on some form of linear-linear or linear-nonlinear transformation. They use either the MCP or Perceptron neuron approach. Recognizing that there are limitations to these neuron-based models, Ritter and Sussner (1998) proposed morphological neural networks, and specifically a morphological autoassociative memory to address capacity and recall shortcomings of the traditional Hopfield network and its variants. Morphological approaches involve two correlation matrices and a nonlinear-nonlinear transformation based on lattice algebra. One matrix is constructed using a maximizing transform, the other matrix a minimizing transform. This is not unlike min-max pooling in some deep learning approaches. Taken together, this pair of matrices provided erosion and dilation resistance to the memories as well as unlimited pattern storage and recall provided exact inputs. Recall that Hopfield networks have a theoretical maximum capacity of 0.15N under the same conditions. Another benefit of the morphological AM is one-shot learning, which does not require multiple iterations of training for convergence as in a Hopfield network. Unlike many prior AM approaches, training can be carried out in parallel.

Ongoing research
Many of the groundbreaking milestones discussed so far were published prior to the year 2000, which is around the time the conventional feed-forward multilayer perceptron with backpropagation took root as the de facto statistical ML approach by researchers. That being said, there have been pockets of active research where AMs have continued to have a strong following. Many of these are in image recognition and high-performance pattern matching systems.
Alpha-Beta Associative Memories
One intriguing offshoot of AM research was initially proposed by Yáñez-Márquez (2002) in his Ph.D. thesis, dubbed the Alpha-Beta Associative Memory. Due to the unavailability of a public copy of his thesis in English, the earliest available publication regarding the original Alpha-Beta AM provides the basis for this discussion (Yáñez-Márquez et al, 2018). While the Alpha-Beta AM was based on the morphological AM proposed by Ritter & Sussner, it augments the nonlinear min-max operations to additionally preprocess the X and Y patterns through so-called 𝛼 and 𝛽 operations prior to the min-max operations.

Rules for updating the pair of matrices were also updated to support the new 𝛼 and 𝛽 operations where the 𝛼 operation was used during the learning phase, and the 𝛽 operation was used during recall. By utilizing constrained sets of possible values for the 𝛼 and 𝛽 operations, the dual-matrix model could be tuned for higher capacity and one-shot learning, and in theory, improved pattern matching in the presence of noise (both additive and subtractive) over the original morphological AM. The Alpha-Beta AM and its variants have been successfully used in image processing, color matching, pollutant detection, bioinformatics, software engineering, and medical support systems, resulting in over 100 publications from 2006-2017; according to the authors, the model had a long roadmap ahead of it as of 2018. Unfortunately, the research team’s website as reported in the 2018 publication is not currently available, so the status of the group’s research activities is unknown at present.
Distributed Associative Memories
Another intriguing offshoot of AM research involves scaling via so-called distributed associative memories. There is mention in the literature dating back to the early 1990s regarding a form of distributed AM for database resilience, but almost all of those approaches involved strategies to distribute the AM storage throughout local memory or persistent storage in a way that was resistant to faulty hardware, including Kanerva’s SDM. In his Ph.D. thesis, Sterne proposed a distributed AM strategy based on a combination of modified Bloom filter, Hopfield network, and error correction algorithms that could in theory be distributed across a network and supported massively parallel training and recall (2011). While Sterne was proposing this as a computational analogue of basic biological neural systems, there has been some follow-on research in this vein that expanded on his variant of the Bloom filter as well as constructing larger AM-like networks.
Hybrid Deep Learning Approaches
In recent years, deep learning practitioners have come to realize that sometimes hybrid solutions yield faster learning and better results. One example is the deep belief network, which has a deep-learning front-end and the final layers are treated as an associative memory (Hinton, 2009). This model has been used on audio and NLP solutions with great success (Sarikaya et al, 2014; Mohamed et al, 2012; Mohamed et al, 2011). More recently, a deep dive into the BERT language model, transformer architecture, and related attention mechanisms uncovered an implicit, embedded Hopfield-type network in what many consider a SOTA deep learning architecture (Ramsauer et al, 2020). Further experiments proved the usefulness of Hopfield networks when blended into certain types of deep learning architectures; a PyTorch layer implementation was recently released as a result of this research (Ml-jku/hopfield-layers, 2020).
Sightings in the wild
Many companies don’t divulge their “secret sauce” when it comes to machine learning or AI unless it’s the new hotness. As a result, documented use cases of AMs outside of academia or R&D are few and far between. Two companies that have openly documented use of AM approaches in recent years are Saffron Technology and Veloxiti.
Saffron Technology was founded in 1999 by Dr. Manuel Aparicio, an AM evangelist and researcher. The company developed AM approaches to build non-deep-learning systems to compete directly against IBM Watson and Grok. Their systems were also used in DARPA projects to construct knowledge bases for the intelligence community. Saffron was purchased by Intel in 2015, but quietly shuttered in late 2018 (Wikipedia - Saffron Technology, 2020). It is unknown whether Saffron’s software is still in use by Intel. Apart from the above-referenced Wikipedia article and a handful of patent filings, there is no publicly available material regarding the details of Saffron’s systems.
Veloxiti was founded in 1987 based on knowledge-based AI (KBAI) approaches, specifically leveraging the Observe-Orient-Decide-Act (OODA) loop to automate challenges in well-defined domains. Around 2010 the company developed a proprietary AM classification system based on sparse compressed matrices that implemented the following unique features:
- Explainability regarding the impact of specific features on each classification score
- Feature engineering for complex data types like streaming real-time sensor signals and unstructured textual data
- Similarity or “fuzzy” matching on continuous data
- A desktop UI to support development, training, and testing workflows
Veloxiti’s AM system was applied to petroleum production systems for real-time anomaly detection and classification of well conditions (Stephenson, 2010). It has also been embedded within OODA loops to provide explainable ML classifications at key decision nodes in a system, as well as a standalone classifier in systems with few-sample or one-shot requirements. (In full disclosure, I am employed by Veloxiti and leverage their AM system to address various ML challenges, often where datasets are too small for contemporary ML approaches to be effective.)
Conclusion
Through our exploration of the history, current state, and future directions of associative memories, I hope you have a new appreciation for the richness of the field, and the applicability not only to software but also hardware for a wide variety of applications. When tackling a new challenge, many machine learning practitioners tend to work their way up from basic statistical methods to advanced ones, maybe dabble a bit in optimization approaches, and then most often converge on deep learning as outlined in most contemporary ML coursework. In fact, most ML textbooks don’t even make mention of associative memories, which I personally feel is a grave oversight (I confirmed that my trusty copy of Mitchell’s venerable Machine Learning sheds no light on these algorithms). So the next time you need a robust pattern matching system, noise-resistant pattern recaller, bidirectional learning system, or have a few-shot requirement, consider adding associative memory approaches to your ML toolbox and you might be surprised how far they can take you.
References
[1] Acevedo-Mosqueda, M. E., Yáñez-Márquez, C., & Acevedo-Mosqueda, M. A. (2013). Bidirectional associative memories: Different approaches. ACM Computing Surveys (CSUR), 45(2), 1-30.
[2] Chou, P. A. (1988). The capacity of the Kanerva associative memory is exponential. In Neural information processing systems (pp. 184-191).
[3] Event-based anticipation systems, methods and computer program products for associative memories. (n.d.). Retrieved October 20, 2020, from https://patents.google.com/patent/US20090083207A1/en
[4] Google Patents. (n.d.). Retrieved September 30, 2020, from https://patents.google.com/?q=%22associative+memory%22
[5] Hassoun, M. H. (1988, May). Two-level neural network for deterministic logic processing. In Optical Computing and Nonlinear Materials (Vol. 881, pp. 258-264). International Society for Optics and Photonics.
[6] Hinton, G. E. (2009). Deep belief networks. Scholarpedia, 4(5), 5947. https://doi.org/10.4249/scholarpedia.5947
[7] Hoffmann, H. (2019). Sparse associative memory. Neural computation, 31(5), 998-1014.
[8] Hoffmann, H. (2019). U.S. Patent Application No. 16/297,449.
[9] Hopfield, J. J. (1982). Neural networks and physical systems with emergent collective computational abilities. Proceedings of the national academy of sciences, 79(8), 2554-2558.
[10] Hopfield, J. J. (1984). Neurons with graded response have collective computational properties like those of two-state neurons. Proceedings of the national academy of sciences, 81(10), 3088-3092.
[11] Ising, E. (1925). Contribution to the theory of ferromagnetism. Z. Phys, 31(1), 253-258.
[12] Jaeckel, L. A. (1989). A class of designs for a sparse distributed memory.
[13] Jaeckel, L. A. (1989). An alternative design for a sparse distributed memory.
[14] Kanerva, P. (1992). Sparse distributed memory and related models.
[15] Keeler, J. D. (1986). Comparison between sparsely distributed memory and Hopfield-type neural network models.
[16] Kohonen, T. (1974). An adaptive associative memory principle. IEEE Transactions on Computers, 100(4), 444-445.
[17] Kosko, B. (1988). Bidirectional associative memories. IEEE Transactions on Systems, man, and Cybernetics, 18(1), 49-60.
[18] McCulloch, W. S., & Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity. The bulletin of mathematical biophysics, 5(4), 115-133.
[19] Ml-jku/hopfield-layers. (2020). [Python]. Institute for Machine Learning, Johannes Kepler University Linz. https://github.com/ml-jku/hopfield-layers (Original work published 2020)
[20] Mohamed, A. R., Hinton, G., & Penn, G. (2012, March). Understanding how deep belief networks perform acoustic modelling. In 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 4273-4276). IEEE.
[21] Mohamed, A. R., Sainath, T. N., Dahl, G., Ramabhadran, B., Hinton, G. E., & Picheny, M. A. (2011, May). Deep belief networks using discriminative features for phone recognition. In 2011 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5060-5063). IEEE.
[22] Prager, R. W., & Fallside, F. (1989). The modified Kanerva model for automatic speech recognition. Computer Speech & Language, 3(1), 61-81.
[23] Ramsauer, H., Schäfl, B., Lehner, J., Seidl, P., Widrich, M., Gruber, L., ... & Kreil, D. (2020). Hopfield networks is all you need. arXiv preprint arXiv:2008.02217.
[24] Ritter, G. X., Sussner, P., & Diza-de-Leon, J. L. (1998). Morphological associative memories. IEEE Transactions on neural networks, 9(2), 281-293.
[25] Rosenblatt, F. (1957). The perceptron, a perceiving and recognizing automaton Project Para. Cornell Aeronautical Laboratory.
[26] Sarikaya, R., Hinton, G. E., & Deoras, A. (2014). Application of deep belief networks for natural language understanding. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22(4), 778-784.
[27] Stephenson, G., Molotkov, R., De Guzman, N., & Lafferty, L. (2010). Real-Time Diagnostics of Gas Lift Systems Using Intelligent Agents: A Case Study. SPE Production & Operations, 25(01), 111-123.
[28] Steinbuch, K. (1961). Die lernmatrix. Kybernetik, 1(1), 36-45.
[29] Steinbuch, K. (1990). Die Lernmatrix - The Beginning of Associative Memories. In Advanced Neural Computers (pp. 21-29). North-Holland.
[30] Sterne, P. J. (2011). Distributed associative memory (Doctoral dissertation, University of Cambridge).
[31] Sánchez-Garfias, F. A., & Yáñez-Márquez, C. (2005, September). A new theoretical framework for the Steinbuch’s Lernmatrix. In Mathematical Methods in Pattern and Image Analysis (Vol. 5916, p. 59160N). International Society for Optics and Photonics.
[32] Wikipedia contributors. (2020, September 7). Ising model. In Wikipedia, The Free Encyclopedia. Retrieved 03:14, October 8, 2020, from https://en.wikipedia.org/w/index.php?title=Ising_model&oldid=977139781
[33] Wikipedia contributors. (2020, October 12). Saffron Technology. In Wikipedia, The Free Encyclopedia. Retrieved 17:52, October 24, 2020, from https://en.wikipedia.org/w/index.php?title=Saffron_Technology&oldid=983150144
[34] Willshaw, D. J., Buneman, O. P., & Longuet-Higgins, H. C. (1969). Non-holographic associative memory. Nature, 222(5197), 960-962.Yáñez-Márquez, C., López-Yáñez, I., Aldape-Pérez, M., Camacho-Nieto, O., Argüelles-Cruz, A. J., & Villuendas-Rey, Y. (2018). Theoretical Foundations for the Alpha-Beta Associative Memories: 10 Years of Derived Extensions, Models, and Applications. Neural Processing Letters, 48(2), 811-847.
Author Bio
Robert Bates is a Principal Engineer II at Veloxiti located in Alpharetta, Georgia, USA. Robert’s research interests lie at the intersection of finance, machine learning, and knowledge discovery. Robert earned an MS in Computer Science from Georgia Tech in 2018 specializing in Machine Learning, in addition to an MBA in Finance from Saint Edward’s University in 2003. Prior to joining Veloxiti, Robert held a Research Faculty position at Georgia Tech developing AI-driven, agent-based simulations in collaboration with the Smithsonian Institution.
Citation
For attribution in academic contexts or books, please cite this work as
Robert Bates, "Don’t Forget About Associative Memories", The Gradient, 2020.
BibTeX citation:
@article{bates2020associative,
author = {Bates, Robert},
title = {Don’t Forget About Associative Memories},
journal = {The Gradient},
year = {2020},
howpublished = {\url{https://thegradient.pub/dont-forget-about-associative-memories/} },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.




{kind=link}
{kind=link}
{kind=link}
{kind=link}