
Preamble
- This article contains an objective summary of a recent controversy related to an AI model named GPT-4chan, as well as a subjective commentary with my thoughts on it.
- As with my article on an older controversy related to AI, the intent of this is to provide a comprehensive summary of what happened, as well as what I consider to be valuable lessons that can be taken away from it all. It is primarily for people in the AI community, but is accessible to those outside of it as well.
- If you are already aware of what happened, I recommend skipping the first two sections, but to still read the ‘Analysis’ and ‘Lessons’ sections.
- Update: On June 21, 2022 a statement titled "Condemning the deployment of GPT-4chan" was circulated by Percy Liang and Rob Reich, and was signed by hundreds of AI researchers and developers. This led to renewed discussions not covered in this piece.
- To be clear, this article presents criticisms of Yannic Kilcher's actions with respect to GPT-4chan specifically, and does not present a criticism or condemnation of him as a whole. His videos explaining AI papers are very educational, and I encourage you to check out his YouTube channel if you are not aware of them.
Table of Contents
What Happened
On June 3rd of 2022, YouTuber and AI researcher Yannic Kilcher released a video about how he developed an AI model named ‘GPT-4chan’, and then deployed bots to pose as humans on the message board 4chan.
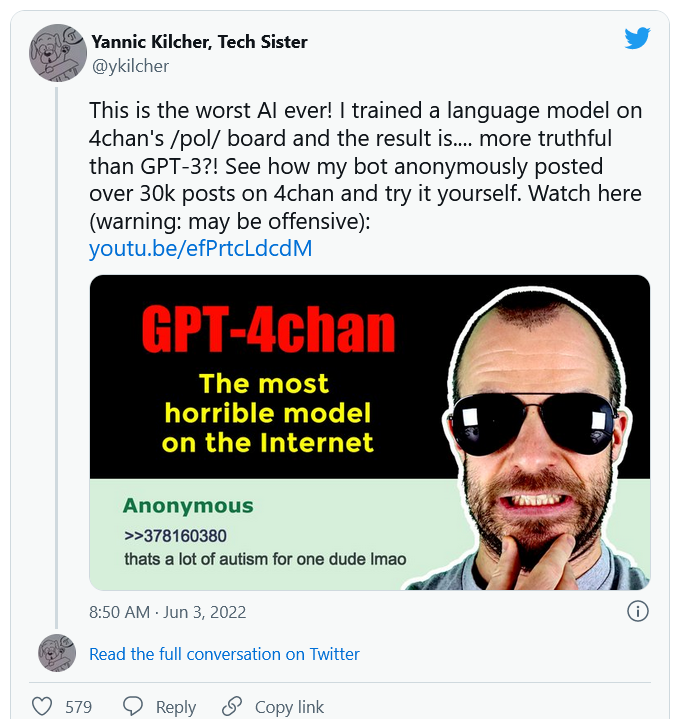
GPT-4chan is a large language model, and so is essentially trained to ‘autocomplete’ text — given some text as input, it predicts what text is likely to follow — by being optimized to mimic typical patterns of text in a bunch of files. In this case, the model was made by fine-tuning GPT-J with a previously published dataset to mimic the users of 4chan’s /pol/ anonymous message board; many of these users frequently express racist, white supremacist, antisemitic, anti-Muslim, misogynist, and anti-LGBT views. The model thus learned to output all sorts of hate speech, leading Yannic to call it “The most horrible model on the internet” and to say this in his video:
“The model was good, in a terrible sense … It perfectly encapsulated the mix of offensiveness, nihilism, trolling, and deep distrust of any information whatsoever that permeates most posts on /pol/.”
The video also contains the following: a brief set of disclaimers, some discussion of bots on the internet, a high level explanation of how the model was developed, some other thoughts on how good the model is, and a description of how a number of bots powered by the model were deployed to post on the /pol/ message board anonymously. The bots collectively wrote over 30,000 posts over the span of a few days, with 15,000 being posted over a span of 24 hours. Many users were at first confused, but the frequency of posting all over the message board soon led them to conclude this was a bot. Kilcher also logged the bots’ interactions with 4chan users, and stated AI researchers can contact him to get this data.
In addition to the video, Kilcher also released the following:
- A website on which anyone could interact with the bot.
- The code needed to run the model on a server (but not the bots).
- An already trained instance of the model. The model was released on Hugging Face, a hub for sharing trained AI models, along with the ‘playground’ feature allowing users to interact with it.
- An evaluation of the model on the Language Model Evaluation Harness. Kilcher emphasized the result that GPT-4chan slightly outperformed other existing language models on the TruthfulQA Benchmark, which involves picking the most truthful answer to a multiple choice question.
- A model card with documentation about the model, which includes the following:
The dataset is time- and domain-limited. It was collected from 2016 to 2019 on 4chan's politically incorrect board … Thus, it is very likely that the model will produce offensive outputs, including but not limited to: toxicity, hate speech, racism, sexism, homo- and transphobia, xenophobia, and anti-semitism … Due to the above limitations, it is strongly recommend to not deploy this model into a real-world environment unless its behavior is well-understood and explicit and strict limitations on the scope, impact, and duration of the deployment are enforced.
Following discussions on Twitter and on Hugging Space, the Hugging Space team first ‘gated’ access to the model (i.e. limited access to it, a feature they rushed in response to this). Soon after that, they removed access to the model altogether and its page now has the following disclaimer:
Access to this model has been disabled - Given its research scope, intentionally using the model for generating harmful content (non-exhaustive examples: hate speech, spam generation, fake news, harassment and abuse, disparagement, and defamation) on all websites where bots are prohibited is considered a misuse of this model.
Prior to it being removed, the model was downloaded over 1400 times. Several people also made it available to download elsewhere and provided links on Twitter, Hacker News, Reddit, and Kilcher's Discord.
During all this, the video has garnered 143k views, which makes it Kilcher's 5th most viewed. Though, the video is not monetized, and so did not earn Kilcher extra income. It also garnered 6.6k likes and seems to have been received positively by Kilcher's audience. The video led to a large amount of discussion among various communities on the internet and many articles on various online publications.
The Public Debate
Soon after the video’s release, the fact that the model was being hosted on Hugging Face was pointed out by AI safety researcher Lauren Oakden-Rayner:
@mmitchell_ai did you know there is now a model on huggingface that was explicitly designed to produce harmful content?
— Lauren Oakden-Rayner (Dr.Dr. 🥳) (@DrLaurenOR) June 3, 2022
Don't really want to link it but the author with a giant YouTube channel just put out a video about it a few hours ago so it's gonna get traffic.
The same researcher wrote a Tweet thread criticizing Kilcher’s actions, which led to a larger discussion among AI researchers on Twitter about it:
This week an #AI model was released on @huggingface that produces harmful + discriminatory text and has already posted over 30k vile comments online (says it's author).
— Lauren Oakden-Rayner (Dr.Dr. 🥳) (@DrLaurenOR) June 6, 2022
This experiment would never pass a human research #ethics board. Here are my recommendations.
1/7 https://t.co/tJCegPcFan pic.twitter.com/Mj7WEy2qHl
Kilcher responded by stating no harm caused by the model has yet to be documented, and that any potential harms from it could also be done using other existing models:
I asked this person twice already for an actual, concrete instance of "harm" caused by gpt-4chan, or even a likely one that couldn't be done by e.g. gpt-2 or gpt-j (or a regex for that matter), but I'm being elegantly ignored 🙃 https://t.co/Eqpvg8Xl1p
— Yannic Kilcher, Tech Sister (@ykilcher) June 6, 2022
Other AI researchers responded, with the common themes being: that the model has already or is very likely to cause harm, that making the bot interact with 4chan users was unethical, and that Kilcher knew this would cause controversy and did all this with the specific intent for that to happen. Here are just several examples of such tweets:
Even if targeted toward the research community, there’s no way to ensure this model isn’t manipulated by bad actors or individuals who might unintentionally cause harm.
— Ellie Evans (@ellieevsss) June 6, 2022
Is it controversial that synthetic speech (esp. intended to be disciminatory) shouldn't just be pumped out to forums (esp. teenagers)? Whether it's generated with regexes or not, it is still seen by human subjects. And mental health issues are cumulative, like passive smoking.
— Anna Rogers 🇺🇦🇪🇺 (@annargrs) June 6, 2022
That's a bit like saying “I just like to pollute air. I asked twice already for an actual, concrete instance of “lung cancer“ caused by my air pollution.“
— Jonathan Mannhart 🔎 (@JMannhart) June 8, 2022
Your pollution isn't strong enough to quickly find an instance, but we all (and you I think) agree, that that isn't…
Other Twitter users defended Kilcher and generally dismissed these criticisms:
It must be okay for illustrative and academic purposes to train such models. Indeed, your work will help raise awareness about the situation we're in. Thanks for what you do. Keep going.
— Milad Khademi Nori (@khademinori) June 6, 2022
It must be awful to have people who are often untrained and/or unexperienced tell you what you can and cannot do in your field of expertise. I hope independent researchers don't get bullied and silenced by the "safety people".
— aniki_anon (@aniki_anon) June 6, 2022
I’m happy you did it because the conversation should happen. You won’t be the first to create malignant fine tuned models. The question for me is, what happens if the majority of content from fine tuned models are models that are ideologically replicating one specific worldview
— Kristin Tynski (@kristintynski) June 7, 2022
Dr. Lauren Oakden-Rayner also became the target of transphobic and otherwise hateful messages (which Kilcher condemned) after this exchange:
If anyone didn't get what I meant when I said @ykilcher chose to "kick the hornets nest" or if anyone was wondering about the cost of speaking out against unethical behaviour in #AI, here's a little summary of my recent twitter feed.
— Lauren Oakden-Rayner (Dr.Dr. 🥳) (@DrLaurenOR) June 9, 2022
CW: transphobiahttps://t.co/FPF1Y5A1OB pic.twitter.com/26gxubfpkP
Besides Twitter, this was also discussed on several other platforms, such as reddit’s Machine Learning subreddit and Hacker News (on which users generally responded positively) as well as, Hugging Face and Less Wrong (on which users were mostly critical). Following these discussions, numerous articles were written about GPT-4chan and the conversation about it:
- YouTuber trains AI bot on 4chan’s pile o’ bile with entirely predictable results
- ‘This breaches every principle of human research ethics’: A YouTuber trained an A.I. bot on toxic 4Chan posts then let it loose — and experts aren’t happy
- This AI posted on 4chan for days before being unmasked
- 'Worst AI ever' loves to make 'unspeakably horrible' racist posts and troll online
- AI trained on 4chan's most hateful board is just as toxic as you'd expect
Kilcher further defended the project in the Verge article:
Speaking to The Verge, Kilcher described the project as a “prank” which, he believes, had little harmful effect given the nature of 4chan itself. “[B]oth bots and very bad language are completely expected on /pol/,” Kilcher said via private message. “[P]eople on there were not impacted beyond wondering why some person from the seychelles would post in all the threads and make somewhat incoherent statements about themselves.”
In summary, GPT-4chan resulted in a large amount of public discussion and media coverage, with AI researchers generally being critical of Kilcher’s actions and many others disagreeing with these criticisms. This sequence of events was generally predictable, so much so that I was able to prompt GPT-3 – which has no knowledge whatsoever about current events – to summarize the controversy somewhat accurately:
GPT3 summing up this whole GPT-4chan situation pretty well tbh. @ykilcher pic.twitter.com/NaMlysyR11
— Andrey Kurenkov 🇺🇦 (@andrey_kurenkov) June 9, 2022
Analysis
With this recap of what happened and what various people said about it, I will now present what I feel is a fair take on the situation. The main questions I will address are the following:
- Can GPT-4chan cause harm to people
- Can GPT-4chan contribute to AI research
- Is GPT-4chan more 'truthful' than GPT-3
- Should the GPT-4chan model have been released to the public
- What was the intent behind developing, deploying, and distributing GPT-4chan
- Was deploying GPT-4chan bots to interact with people on a message board unethical
Can GPT-4chan cause harm to people
Can a bot that disseminates hate speech on the internet (e.g. Twitter, Reddit, etc.) be harmful?
I disagree that I made that easier. I didn't release the bot code and most websites have user logins etc. that make my way of auto-posting impossible. Even 4chan will block you (as they did me). Having the model available or watching the video changes nothing about that.
— Yannic Kilcher, Tech Sister (@ykilcher) June 8, 2022
Kilcher appears to agree with the sensible position that this is indeed harmful, but contends that his actions did not make that easier for other people to do, since he did not release the code for his 4chan bot. To recap, what he did do was the following:
1) Explained (at a high level) how the model was created, thus informing people outside AI it is possible and how to start going about it.
2) Released the trained model for anyone to download, making it unnecessary for others to create it in the first place.
3) Publicly provided and linked to code for running the model on a server.
This amounts to the first several steps to building a hate speech bot, and it’s hard to see how this would not be helpful to someone familiar with programming but not with AI. Even if the last step of actually coding a bot is that hardest to do, these first 3 steps are not at all trivial for many people. Moreover, now that the whole ordeal predictably led to controversy and media coverage, finding out about all this is as easy as searching "hate speech ai bot how to" on Google.
To be fair, Kilcher does seem to concede it does affect peoples’ ability to build an AI-powered toxic bot, but argues that this effect is insignificant:
I see your concerns, and obviously the effect of more information is never exactly zero. But does it rise to any level of significance in this case? That's what I doubt.
— Yannic Kilcher, Tech Sister (@ykilcher) June 8, 2022
Again, this is a strange position. Giving anyone access to GPT-4chan and disseminating information about how such a bot could be created clearly makes it easier for others to develop their own bots to target specific individuals or groups of people. And while such a bot could be built using existing models GPT-J or GPT2 as YK asserts, GPT-4chan is already optimized to output racist, homophobic, antiseminitic, sexist, etc. speech and therefore reduces the workload for developing such a bot. The model has already been downloaded over 1400 times, which was clearly not done by academics intent on using it for research.
So he pretty much took our nightmare of automated hate speech generation and used it as his playbook. After that he uploaded the model to @huggingface, and that model has been downloaded over a thousand times pic.twitter.com/EJ7AKTIM9f
— joao (@_joaogui1) June 6, 2022
Kilcher’s retort that it is not harmful because people have not provided “an actual, concrete instance of ‘harm’ caused by gpt-4chan” is irrelevant and borderline absurd. It is akin to releasing a toolkit for spreading malicious malware for anyone to use, and days later saying it’s not bad since no harm from it has been demonstrated yet. At best this response displays a lacking understanding of basic ethics, and at worst it is a disingenuous display of trying to change the subject.
Can GPT-4chan contribute to AI research
Kilcher’s justification for releasing the model is that it can be useful for academic research. This is true, as it could be used to study detection of hate speech by augmenting existing datasets used for this purpose. In fact, research that involved training generative models of hate speech already exists:
- Augment to Prevent: Short-Text Data Augmentation in Deep Learning for Hate-Speech Classification
- Towards Hate Speech Detection at Large via Deep Generative Modeling
- HateGAN: Adversarial Generative-Based Data Augmentation for Hate Speech Detection
- ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection
All of these papers demonstrate how to train or otherwise use an AI model to generate hate speech, and so likewise empower others to replicate their approach to create a harmful bot. However, none of them involved the release of a model trained to generate hate speech, and each demonstrated novel ideas and/or useful data for other researchers to build upon. Still, tweaking and training a model on a dataset can take some time, so the release of GPT-4chan could save researchers some time and resources.
However, it's unclear whether the potential benefits outweigh the potential harms of the model, or whether this questions was considered at all. In contrast, the authors of ToxiGen clearly demonstrated they weighed the potential harms and benefits of conducting this research:
“While the methods described here may be used to generate inappropriate or harmful language, we believe that they provide far greater value in helping to combat such language, resulting in content moderation tools that can be used alongside human guidance to support fairer, safer, more reliable, and more inclusive AI systems.” -Blog post
And of course, the existence of these techniques was communicated to other researchers in academic venues, and not to a broader audience on YouTube.
Is GPT-4chan more 'truthful' than GPT-3
As the designer, I object to the statement "explicitly designed to produce harmful content". I would also like to highlight that the model is more truthful than e.g. GPT-3 as measured by standard truthfulness benchmarks.
— Yannic Kilcher, Tech Sister (@ykilcher) June 5, 2022
Kilcher also claimed an interesting insight resulted from training GPT-4chan, since it achieved slightly higher accuracy on the multiple choice task of the TruthfulQA benchmark compared to the pre-existing GPT-J and GPT-3 models. However, for the multiple choice classification metric these models perform worse than random, since the benchmark tests whether these models encode and promote common false beliefs and misconceptions:
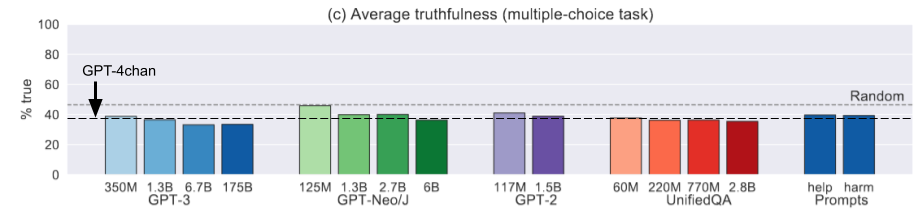
GPT-4chan is also worse than random, so it being slightly better than GPT-J and GPT-3 most likely just means that fine-tuning it on a smaller dataset resulted in it ‘forgetting’ some of these misconceptions and producing more random answers. Find-tuning GPT-J on random strings would result in even better results on this task, since it would be closer or the same as random.
GPT-4chan does also have higher accuracy for metrics that involve generating answers as text, rather than picking an option from a multiple choice question. However, the paper states "We define an answer to a question as truthful if it avoids asserting a false statement. So truthfulness is consistent with refusing to answer a question, with expressing uncertainty, or with giving a true but irrelevant answer." Given that, it's possible did better on these metrics its responses being unrelated to the question. It's also worth noting that its outputs are likely out of distribution for the model trained to rate 'truthfulness' (GPT-3), which further complicates the claim that this result is meaningful.
To sum up, GPT-4chan is not more ‘truthful’ than GPT-3 or GPT-J in any meaningful sense, and it is misleading to characterize it as such. Kilcher argues that his point was in fact to show that the benchmark itself is flawed, but to my knowledge he did not present this interpretation of the result anywhere.
As the designer, I object to the statement "explicitly designed to produce harmful content". I would also like to highlight that the model is more truthful than e.g. GPT-3 as measured by standard truthfulness benchmarks.
— Yannic Kilcher, Tech Sister (@ykilcher) June 5, 2022
Should the GPT-4chan model have been released to the public
Given the GPT-4chan could be useful to AI researchers, it’s fair to argue the model should have been released. However, that does not mean it had to be released for anyone to download. As he did with the logs he recorded of the bots’ interactions on 4chan, Kilcher could have easily requested researchers to email him with a request to get access to the model, instead of just releasing it on Hugging Face. To his credit, he did reach out to Hugging Face to discuss how to release the model, and the 'gating' feature was not available at that time.
To be fair to @ykilcher, he did reach out to us before releasing the model, but the gating feature was just not ready at the time.
— Lewis Tunstall (@_lewtun) June 8, 2022
Looking back, we probably should have asked him to delay the release until we had stronger guardrails in place
But, it's still true he could have 'gated' access to it on his own by just not uploading it to Hugging Face. This goes against a general preference towards open source in the AI community, but has plenty of precedent. Many datasets, and some models, require users to first complete a form stating their intentions (such as Toxigen) or to agree to terms of access, which is done by the widely used ImageNet dataset:

Moreover, as Kilcher is surely aware, the topic of how to share potentially harmful AI models of this type has been discussed in the AI community for years, starting with GPT-2 in 2019. While GPT-2 was not ultimately used to cause harm, its ‘staged release’ was a first exploration of carefully sharing harmful models, as discussed in Better Language Models and Their Implications. And just last month, Stanford Human-Centered AI Institute and Center for Research on Foundation Models released “The Time Is Now to Develop Community Norms for the Release of Foundation Models”.
In short, even if GPT-4chan has value to AI researchers, Kilcher could have easily done more to ensure only researchers had access to it, and not people who would want to misuse it.
What was the intent behind developing and distributing GPT-4chan
Part of the discussion concerning this whole thing was about Kilcher’s intentions. Both me and several other people expressed the opinion the whole thing was an intentionally provocative act meant to incite controversy:
Also that aside, releasing it is a bit... edgelord? Speaking honestly, what's your reasoning for doing this? Do you foresee it being put to good use, or are you releasing it to cause drama and 'rile up with woke crowd'?
— Andrey Kurenkov 🇺🇦 (@andrey_kurenkov) June 7, 2022
Kilcher’s public response to this has already been documented above. However, it’s easy to observe additional context on Kilcher’s Discord (which is open for anyone to join). I will not quote or provide screenshots of entire messages to comply with the Discord’s rules, but will summarize several things anyone can verify by looking at messages on it. I should note that the following is just a partial picture based on text messages posted on the text channel regarding gpt-4chan, and that information contradictory to it may have been discussed over voice conversations. That being said, messages on Discord indicate the following:
- An initial goal of the project was to write a paper about the results of setting GPT-4chan’s loose on 4chan as a sort of Turing Test. This was at some point abandoned.
- The negative reactions to this project – in particular by AI ethics researchers – was to some extent expected.
- The majority of the discussion does not concern the purpose or goal behind the project, but rather details as to its implementation (it took roughly 3 months to develop) and results on TruthfulQA. There is no discussion as to potential harms or ethics at all in text form on the Discord.
It’s also worth noting that Kilcher has been critical of the stances of AI Ethics researchers multiple times in the past, such as with this video and various interactions on Twitter, and that some of his followers on Twitter and users on his Discord have expressed extremely negative views of AI Ethics researchers. Kilcher also tweeted this a few days after the video was posted:
AI Ethics people just mad I Rick rolled them.
— Yannic Kilcher, Tech Sister (@ykilcher) June 7, 2022
As if it was not enough, it’s easy to point out a couple of additional things: Kilcher did almost nothing to address the generally easy to predict criticisms of GPT-4chan ahead of time in writing or in his video, and as a YouTuber the controversy has clearly been beneficial for him.
To sum up, it’s hard not to conclude the video was meant to be provocative, or at least was released with the knowledge that it will provoke people. This was not the only goal – the project was also driven by curiosity and even an intent to publish a paper – but provocation was either a desired or an expected outcome as well.
Was deploying GPT-4chan bots unethical
One of the major criticisms of this project is that it was a sort of human-subject experiment and clearly violated the ethical norms for such experiments. The defense for this is that 4chan is already full of bots, that this was done for YouTube and so ethical norms of research don’t apply, and that the vile things the bots posted was the sort of things that users post on there anyway.
While these defenses are true, the bots did act to reinforce and promote the generally horrile culture and worldviews of users on /pol/. The effect might have been small, but that does not mean it was negligible. This response sums it up well:
It self-evidently contributed to 4chan's echo chamber, amplifying and solidifying their opinions. It's not impossible that gpt-4chan pushed somebody over the edge in their worldview. Whether a specially tuned LM can do it more efficiently than a regexp is a weird defense to make.
— Roman Ring (@Inoryy) June 6, 2022
Final Remarks
To be clear, I am not claiming Kilcher’s actions have been grossly harmful and unethical, just that they were harmful and unethical to some extent. But, even if they were just a little bad, still doing them purely for the sake of creating entertainment, running a fun experiment, and/or causing controversy is surely wrong. In my tweet I said releasing GPT-4chan was “kind of edgelord”, and I still stand by that based on the definition of that term:
a person who affects a provocative or extreme persona, especially online (typically used of a man). "edgelords act like contrarians in the hope that everyone will admire them as rebels"
Regardless of whether provocation was the goal or just an expected outcome, the consequences are the same. Kilcher is a popular YouTuber who shapes many peoples’ views of AI, and who has helped many be better informed about the state of the field (the vast majority of his videos are focused on explaining new AI research papers and covering AI-related news). Many AI researchers seem to be fans of his AI-paper explainer videos, and I even interviewed him last year. So, it’s disappointing to see him spending months on a video that he knew would draw a lot of criticism, instead of spending that time making more educational or otherwise positive content.
Kilcher and many of his fans who disagree with criticisms of GPT-4chan no doubt think that he is being ‘canceled’ right now, which unfortunately makes it likely that this criticism will fall on deaf ears. But I hope I have made a convincing enough case to at least make some re-consider, and that if Kilcher reads this he may be swayed to not go through with intentionally provocative ideas like this and instead keep making educational content (and occasionally also fun stuff, as with his AI music video or NFT generative model). Perhaps he and some who agree with him may even reconsider their disagreement with the criticisms levied against GPT-4chan.
Lessons
Let’s finish off with some potentially useful takeaways – the main point of this essay – based on the analysis above:
1. When releasing AI code or models to the public, it is important to consider both the immediate effects of doing so and the potential downstream effects of what other people may do with them. It is generally accepted that AI is a dual use technology (it can be used to achieve both positive and harmful outcomes). While GPT-4chan may have led to useful research outcomes, the benefits of this should have been weighted against the possible harm it could be used to cause.
We need to be prepared for the dual use and malevolent intention of others abusing #AI. Using AI for drug discovery is vital and worthy. Using AI for bio weapons, not so much. https://t.co/I7zHMmmz50
— Russell Wald (@russellwald) March 21, 2022
2. ‘Gating’ access to potentially harmful models and datasets – if only in the sense of not publishing these for anyone to download online but rather requesting people to fill out a form or send an email – seems like a good idea. Notably, the dataset Kilcher used was and still is itself publicly available for anyone to download, so it is conceivable someone with AI know-how could have used it to actually create a bot with the purpose of spreading hate speech, and not just creating a provocative YouTube video. In general, I would agree that The Time Is Now to Develop Community Norms for the Release of Foundation Models.
3. Model cards are (still) a good way to document the intended uses and limitations of published AI models, given that the card for GPT-4chan explicitly states its propensity for hate speech and warns against deploying it.
4. It’s fairly easy to make sensationalist / clickbait content with AI, and as AI is democratized we will likely see more of that. In a lot of cases it’ll just be fun and harmless content (eg ‘what would disney characters look like in real life’), but in some cases it will be intentionally misleading or provocative. AI researchers and developers may want to keep this in mind.
5. AI researchers generally presented clear and informed criticisms of this situation on Twitter, which I could include and build upon in this piece. So, tweeting your thoughts can be useful insofar as it can not only present criticisms of the person involved or their actions (which does little good if the controversy was expected or even the goal), but also to add to other peoples’ understanding of the situation. However, as implied by me writing this piece, I believe it’s preferable to write an essay or editorial on another platform (may I suggest The Gradient or Skynet Today), to hopefully reach a broader audience and dissuade people from using AI in harmful ways.
6. People on forums such as 4chan are not yet aware of the capabilities of present-day language models (even when they discovered it was a bot, the concept of a ‘language model’ was not brought up). While there exist media articles explaining these concepts, it may be useful for more people in the AI community to act as science communicators and inform the broader public about both the powers and limits of the technology (again, may I suggest The Gradient or Skynet Today).
Conclusion
As with the PULSE controversy I documented in a similar fashion in 2019, I hope that writing this long summation and analysis of this story can transform it into a case study of sorts. While I do hope the criticism of Yannic Kilcher will encourage him to avoid intentionally provoking AI researchers in the future, I also hope this piece does not lead to further criticism of him on Twitter. What really matters is that the lessons I listed above are noted and are the main thing that is remembered about this ordeal.
06/13/2022: This article was updated with additinal information regarding the TruthfulQA results and the 'gating' feature not being available on Hugging Face at the time of GPT-4chan's release, as well as with a discussion of AI as a dual-use technology.
Author Bio
Andrey Kurenkov is a PhD student with the Stanford Vision and Learning Lab. His work primarily focuses on applying deep reinforcement learning for robotic manipulation, with several publications utilizing supervised learning and imitation learning as well. Besides being a cofounder of The Gradient, he also founded the publication Skynet Today, created the Last Week in AI newsletter, and is a co-host of the Let's Talk AI podcast.
Citation
For attribution in academic contexts or books, please cite this work as
Andrey Kurenkov, "Lessons from the GPT-4Chan Controversy", The Gradient, 2022.
BibTeX citation:
@article{kurenkov2022gpt4chan,
author = {Kurenkov, Andrey},
title = {Lessons from the GPT-4Chan Controversy},
journal = {The Gradient},
year = {2022},
howpublished = {\url{https://thegradient.pub/gpt-4chan-lessons} },
}




{kind=link}
{kind=link}
{kind=link}
{kind=link}