P
eer review has been an integral part of scientific research for more than 300 years. But even before peer review was introduced, reproducibility was a primary component of the scientific method. One of the first reproducible experiments was presented by Jabir Ibn Haiyan in 800 CE. In the past few decades, many domains have encountered high profile cases of non-reproducible results. The American Psychological Association has struggled with authors failing to make data available. A 2011 study found that only 6% of medical studies could be fully reproduced. In 2016, a survey of researchers from many disciplines found that most had failed to reproduce one of their previous papers. Now, we hear warnings that Artificial Intelligence (AI) and Machine Learning (ML) face their own reproducibility crises.
This leads us to ask: is it true? It would seem hard to believe, as ML permeates every smart-device and intervenes evermore in our daily lives. From helpful hints on how to act like a polite human over email, to Elon Musk’s promise of self-driving cars next year, it seems like machine learning is indeed reproducible.
How reproducible is the latest ML research, and can we begin to quantify what impacts its reproducibility? This question served as motivation for my NeurIPS 2019 paper. Based on a combination of masochism and stubbornness, over the past eight years I have attempted to implement various ML algorithms from scratch. This has resulted in a ML library called JSAT. My investigation in reproducible ML has also relied on personal notes and records hosted on Mendeley and Github. With these data, and clearly no instinct for preserving my own sanity, I set out to quantify and verify reproducibility! As I soon learned, I would be engaging in meta-science, the study of science itself.
What is Reproducible Machine Learning?
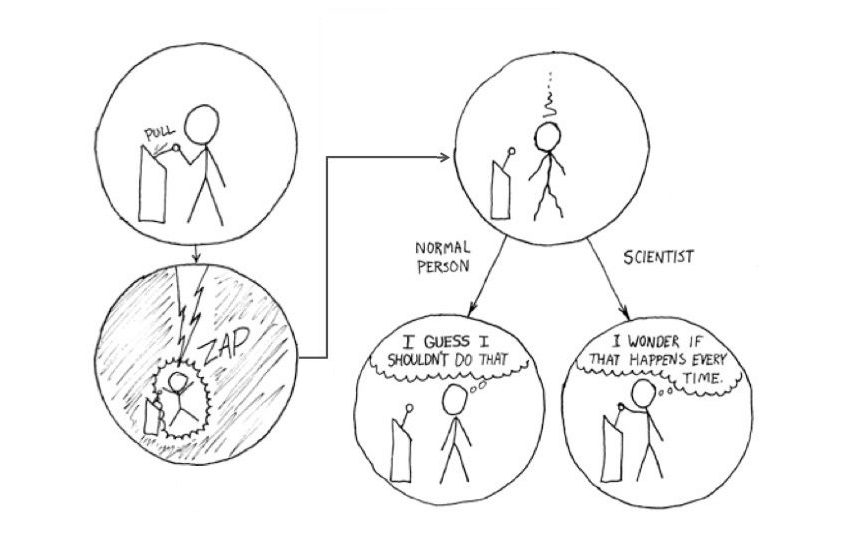
Before we dive in, it is important to define what we mean by reproducible. Ideally, full reproducibility means that simply reading a scientific paper should give you all the information you need to 1) set up the same experiments, 2) follow the same approach, and then 3) obtain similar results.
If we can get all the way to step 3 based solely on information present in the paper, we might call that independent reproducibility. In this example, our result is reproducible because we are able to get the same result, and independent because we have done so in an effort completely independent of the original publication.
But as our friend from the comic above might tell us, simply following the content of the paper isn’t always sufficient. If we can’t get to step 3 by using only the information in the paper (or from cited prior work), we would determine that the paper is not independently reproducible.
Some may wonder, why make this distinction between reproducibility and independent reproducibility? Almost all of AI and ML research is based on computer code. We don’t require the burden of expensive and labor-intensive chemical synthesis, waiting for bacteria in a petri dish to mature, or pesky human trials. It should be easy to simply get code from the authors, run that on the same data, and get the same results!

Our aversion to using or asking for the authors code is more than fear of working with undocumented research-grade code. Chris Drummond has described the approach of using an author’s code as replicability, and made a very salient argument that replication is desirable, but not sufficient for good science. A paper is supposed to be the scientific distillation of the work, representing what we have learned and now understand to enable these new results. If we can’t reproduce the results of a paper without the authors code, it may suggest that the paper itself didn’t successfully capture the important scientific contributions. This is before we consider the possibility that there may be bugs in the code that actually benefit the results, or any number of other possible discrepancies between code and paper.
Another great example from ICML this past year showed that even if we can replicate the results of a paper, slightly altering the experimental setup could have dramatically different results. For these reasons, we don’t want to consider the authors code, as this could be a source of bias. We want to focus on the question of reproducibility, without wading into the murky waters of replication.
What Makes a ML Paper Reproducible?
| Feature | Important | My Reaction |
|---|---|---|
| Hyperparameters | ✅ | 👍 |
| Easy to Read | ✅ | 👍 |
| Equations per Page | ✅ | 🤔 |
| Empirical vs Rigor | ✅ | 🤨 |
| Pseudo Code | ✅ | 🤯 |
| Replies to Questions | ✅ | 🤷 |
| Include Toy Problems | ❌ | 😭 |
| Year Published | ❌ | 😌 |
| Open Source Code | ❌ | 😱 |
I reviewed every paper I have attempted to implement up to 2017, and filtered out papers based on two criteria: if the attempt would be biased by having looked at released source code, or if there was a personal relationship with the authors. For each paper, I recorded as much information as I could to create a quantifiable set of features. Some were completely objective (how many authors where on the paper), while others highly subjective (does the paper look intimidating)? The goal of this analysis was to get as much information as possible about things that might impact a paper’s reproducibility. This left me with 255 attempted papers, and 162 successful reproductions. Each paper was distilled to a set of 26 features, and statistical testing was done to determine which were significant. In the table to the right I've put what I think are the most interest and important results, along with my initial reactions.
Some of the results where unsurprising. For example, the number of authors shouldn’t have any particular importance to a paper’s reproducibility, and it did not have a significant relationship. Hyperparameters are the knobs we can adjust to change an algorithms behavior, but are not learned by the algorithm itself. Instead, we humans must set their values (or devise a clever way to pick them). Whether or not a paper detailed the hyperparameters used was found to be significant, and we can intuit why. If you don’t tell the reader what the settings where, the reader has to guess. That takes work, time, and is error prone! So, some of our results have given credence to the ideas the community has already been pursuing in order to make papers more reproducible. What is important is that we can now quantify why these are good things to be pursuing. Other findings follow basic logic, such as the finding that papers that are easier to read are easier to reproduce, likely because they are easier to understand.
I implore you to read the paper for a deeper discussion, but there are a few additional results that I think are particularly interesting; either because they challenge our assumptions about what we “know” a good paper is or lead to some surprising conclusions. All of these results are nuanced more than I can unpack in this article, but are worth mentioning if for nothing else but to stimulate a deeper conversation, and hopefully spur further research to answer these questions.
Finding 1: Having fewer equations per page makes a paper more reproducible.

It appears to be the case because the most readable papers use the fewest equations. We often see papers that have many equations and derivations listed, for any number of reasons. It appears that a careful and judicious use of equations makes things easier to read, primarily because you can use math selectively to communicate more effectively. This result clashes with the incentive structure of getting a paper published. On more than one occasion, reviewers have asked me to include more math in a paper. It may be that the math itself makes a paper more scientific or grounded in objectivity. While more specification may seem to be better, it is not synonymous with reproducibility. This is a cultural issue we need to address as a community.
Finding 2: Empirical papers may be more reproducible than theory-oriented papers.
There is considerable debate within the community about where and how much rigor needs to be normalized in the community. This is done under the guide that as a community, our focus should be on getting the best results for a given bench mark. Yet in optimizing for bench marks, we risk losing our understanding of what is actually happening and why these methods work. The inclusion of theoretical work and formal proofs do not cover all aspects of what might be meant by the term rigor. Given the common belief that elaborate mathematical proofs ensure a better understanding of a given method, it is interesting to see that greater mathematical specification isn’t necessarily making research easier to reproduce. The important point here is that papers containing a mix of theory and empirical emphasis have the same overall reproduction rates as purely empirical papers. An empirical bent can be helpful from the reproducibility perspective, but could also hamper progress by creating perverse incentives and unintended side effects.
Finding 3: Sharing code is not a panacea
We have already touched upon the idea that reproduction via released code is not the same thing as reproduction done independently. Is this a difference without distinction? It is not! My results indicate that the open sourcing of code is at best a weak indicator of reproducibility. As conferences begin to more strongly encourage code submission and examination as part of the review process, I believe this is a crucial point. As a community, we need to understand what our goals are with such efforts and what we are actually accomplishing. Careful thought and consideration should go into this distinction if we ever make code submission mandatory, and the guidance we give reviewers to evaluate such code.
I find this result particularly noteworthy in terms of other people's reactions. While presenting at NeurIPS, many people commented on it. Half of them were certain that releasing would have been correlated with reproducibility , and the other half felt it obvious that the non-relationship would emerge. This strong contrast in opinions that were all deeply held is a perfect example of why I wanted to do this study. We don't really know until we sit down and measure it!
Finding 4: Having detailed pseudo code is just as reproducible as having no pseudo code.



This finding challenged my assumptions of what constituted a good paper, but made more sense as I thought about the results. Somewhere in the paper, the process must be described. A computer scientist by training, I always preferred a type of description called pseudo code. But pseudo code can take many different forms. I categorized the papers it into four groups: None, Step-Code, Standard-Code, and Code-Like. I have some representative samples of these to the right from some widely reproduced papers that may or may not have been in this study!
I was shocked when Standard-Code and Code-Like has roughly equal reproduction rates, and floored to discover that None at all was just as good! However, cogent writing is just as effective in communicating a process. What was not as effective was so-called Step code, where a bulleted list of steps is listed, with each step referring to another section of the paper. Step code actually makes reading and understanding the paper harder, as the reader must now jump back and forth between different sections, rather than following a single sequential flow.
Finding 5: Creating simplified example problems do not appear to help with reproducibility.
This was another surprising result that I am still coming to grips with. I’ve always valued writers who can take a complex idea and boil it down to a simpler and more digestible form. I have likewise appreciated papers that create so-called toy problems. Toy problems which exemplify some property in a way that is easily visualized and turned into experiments. Subjectively, I always found simplified examples useful for understanding what a paper is trying to accomplish. Reproducing the toy problem was a useful tool in creating a smaller test case I could use for debugging. From an objective standpoint, simplified examples appear to provide no benefit for making a paper more reproducible. In fact, they do not even make papers more readable! I still struggle to understand and explain this result. This is exactly why it is important for us as a community to quantify these questions. If we do not do the work of quantifiction, we will never know that our work is tackling the issues most relevant to the research problem at hand.
Finding 6: Please, check your email
The last result I want to discuss is that replying to questions has a huge impact on a paper’s reproducibility. This result was expected, as not all papers rarely contain a perfect description of their methods. I emailed 50 different authors with questions regarding how to reproduce their results. In the 24 cases where I never got a reply, I was able to reproduce their results only once (a 4% success rate). For the remaining 26 cases in which the author did respond, I was able to successfully reproduce 22 of the papers (an 85% success rate). I think this result is most interesting for what it implies about the publication process itself. What if we allowed published papers to be updated over time, without it becoming some kind of “new” publication? This way, authors could incorporate common feedback and questions into the original paper. This is already possible when papers are posted on the arXiv; this should be the case for conference venue publications as well. These are things that could potentially advance science by increasing reproducibility, but only if we allow them to happen.
What Have We Learned?

This work was inspired by the headline, “Artificial intelligence faces reproducibility crisis”. Is this headline hype or does it point to a systematic problem in the field? After completing this effort, my inclination is that there is room for improvement, but that we in the AI/ML field are doing a better job than most disciplines. A 62% success rate is higher than many meta-analyses from other sciences, and I suspect my 62% number is lower than reality. Others who are more familiar with research areas outside of my areas of expertise might be able to succeed where I have failed. Therefore, I consider the 62% estimate to be a lower bound.
One thing I want to make very clear: none of these results should be taken as a definitive statement on what is and what is not reproducible. There are a huge number of potential biases that may impact these results. Most obvious is that these 255 attempts at reproduction were all done by a single person. There are no community standards for internal consistency between meta-analysts. What I find easy to reproduce may be difficult for others, and vice-versa. For example, I couldn’t reproduce any of the Bayesian or fairness-based papers I attempted, but I don’t believe that these fields are irreproducible. My personal biases, in terms of background, education, resources, interests, and more, are all inseparable from the results obtained.
That said, I think this work provides strong evidence for a number of our communities’ current challenges while validating many reproducibility efforts currently under way in the community. The biggest factors are that we cannot take all of our assumptions about so-called reproducible ML at face value. These assumptions need to be tested, and I hope more than anything that this work will inspire others to begin quantifying and collecting this data for themselves. As a community, we are in a very unique position to perform meta-science on ourselves. The cost of replication is so much lower for us than for any other field of science. What we learn here could have impacts that extend beyond AI & ML to other subfields of Computer Science.
More than anything, I think this work reinforces how difficulties of evaluating the reproducibility of research. Considering each feature in isolation is a fairly simple way to approach this analysis. This analysis has already delivered a number of potential insights, unexpected results, and complexities. However, it does not begin to consider correlations among papers based on authors, and representing the data as a graph, or even just looking at non-linear interactions of the current features! This is why I’ve attempted to make much of the data publicly available so that others can perform a deeper analysis.
Finally, it has been pointed out to me that I may have created the most unreproducible ML research ever. But in reality, it leads to a number of issues regarding how we do the science of meta-science, to study how we implement and evaluate our research. With that, I hope I’ve encouraged you to read my paper for further details and discussion. Think about how your own work fits into the larger picture of human knowledge and science. As the avalanche of new AI and ML research continues to grow, our ability to leverage and learn from all this work will be highly dependent on our ability to distill ever more knowledge down to a digestible form. At the same time, our process and systems must result in reproducible work that does not lead us astray. I have more work I would like to do in this space, and I hope you will join me.
Author Bio
Dr. Edward Raff is a Chief Scientist at Booz Allen Hamilton, Visiting Professor at the University of Maryland, Baltimore County (UMBC), and author of the JSAT machine learning library. Dr. Raff leads the machine learning research team at Booz Allen, while also supporting clients who have advanced ML needs. He received his BS and MS in Computer Science from Purdue University, and his PhD from UMBC. You can follow him on Twitter @EdwardRaffML.
Acknowledgments
Feature image source: https://xkcd.com/242/
Citation
For attribution in academic contexts or books, please cite this work as
Edward Raff, "Quantifying Independently Reproducible Machine Learning", The Gradient, 2020.
BibTeX citation:
@article{raff2020quantifying,
author = {Raff, Edward},
title = {Quantifying Independently Reproducible Machine Learning},
journal = {The Gradient},
year = {2020},
howpublished = {\url{https://thegradient.pub/independently-reproducible-machine-learning/ } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.



{kind=link}
{kind=link}
{kind=link}
{kind=link}