
When I started my first job out of college, I thought I knew a fair amount about machine learning. I had done two internships at Pinterest and Khan Academy building machine learning systems. I spent my last year at Berkeley doing research in deep learning for computer vision and working on Caffe, one of the first popular deep learning libraries. After I graduated, I joined a small startup called Cruise that was building self-driving cars. Now I’m at Aquarium, where I get to help a multitude of companies deploying deep learning models to solve important problems for society.
Over the years, I got the chance to build out pretty cool deep learning and computer vision stacks. There are a lot more people using deep learning in production applications nowadays compared to when I was doing research at Berkeley, but many problems that they face are the same ones I grappled with in 2016 at Cruise. I’ve learned a lot of lessons about doing deep learning in production, and I'd like to share some of those lessons with you so you don’t have to learn them the hard way.
A Story

To start off, let me talk about the first ever ML model deployed onto the car at Cruise. As we developed the model, the workflow felt a lot like what I was used to from my research days. We trained open source models on open source data, integrated them into our production software stack, and deployed them onto the car. After a few weeks of work, we merged the final PR to turn on the model to run on the car. “Mission accomplished!” I thought, and then we moved on to putting out the next fire. Little did I know that the real work had only just begun.
As the model ran in production, our QA team started to notice problems with its performance. But we had other models to set up and fires to fight, so we didn’t try to immediately address the issues. 3 months later, when we looked into them, we discovered that the training and validation scripts had all broken due to changes in the codebase since the first time we deployed!
After a week of fixing that, we looked at the failures over the past few months and realized that a lot of the problems we observed in the model’s production runs could not be easily solved by modifying the model code, and that we needed to go collect and label new data from our vehicles instead of relying on open source data. This meant that we needed to set up a labeling process with all of the tools, operations, and infrastructure that this process would entail.
Another 3 months later, we were able to ship a new model that was trained on randomly selected data that we had collected from our vehicles and then labeled with our own tools. But as we started solving the easy problems, it got harder and harder to improve the model, and we had to become a lot smarter about what changes were likely to yield results. Around 90% of the problems were solved with careful data curation of difficult or rare scenarios instead of deep model architecture changes or hyperparameter tuning. For example, we discovered that the model had poor performance on rainy days (rare in San Francisco) so we labeled more data from rainy days, retrained the model on the new data, and the model performance improved. Similarly, we discovered that the model had poor performance on green cones (rare compared to orange cones) so we collected data of green cones, went through the same process, and model performance improved. We needed to set up a process where we could quickly identify and fix these types of problems.
It took only a few weeks to hack together the first version of the model. Then another 6 months to ship a new and improved version of the model. And as we worked more on some of the pieces (better labeling infrastructure, cloud data processing, training infrastructure, deployment monitoring) we were able to retrain and redeploy models about every month to every week. As we set up more model pipelines from scratch and worked on improving them, we began to see some common themes. Applying our learnings to the new pipelines, it became easier to ship better models faster and with less effort.
Always Be Iterating
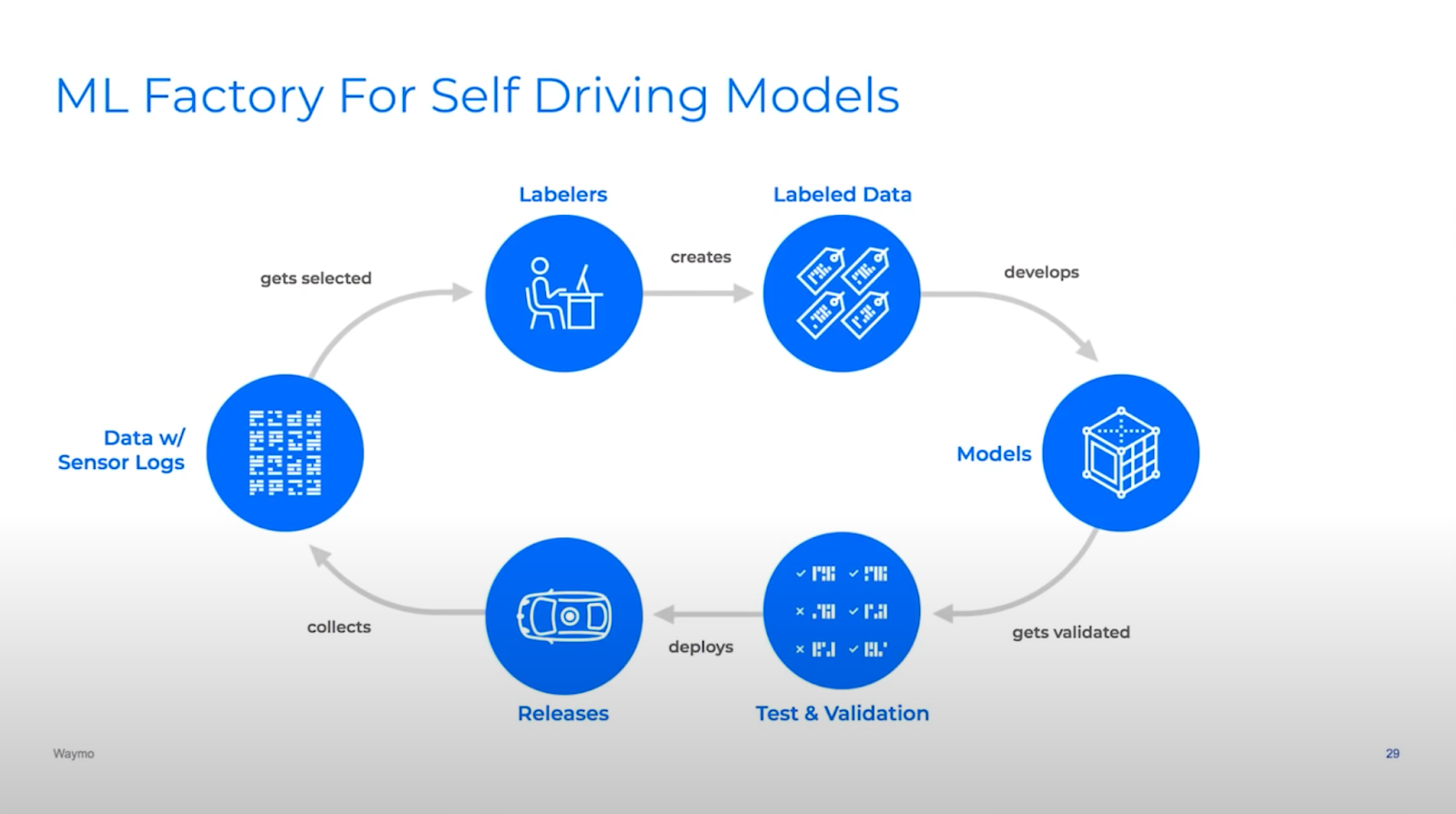

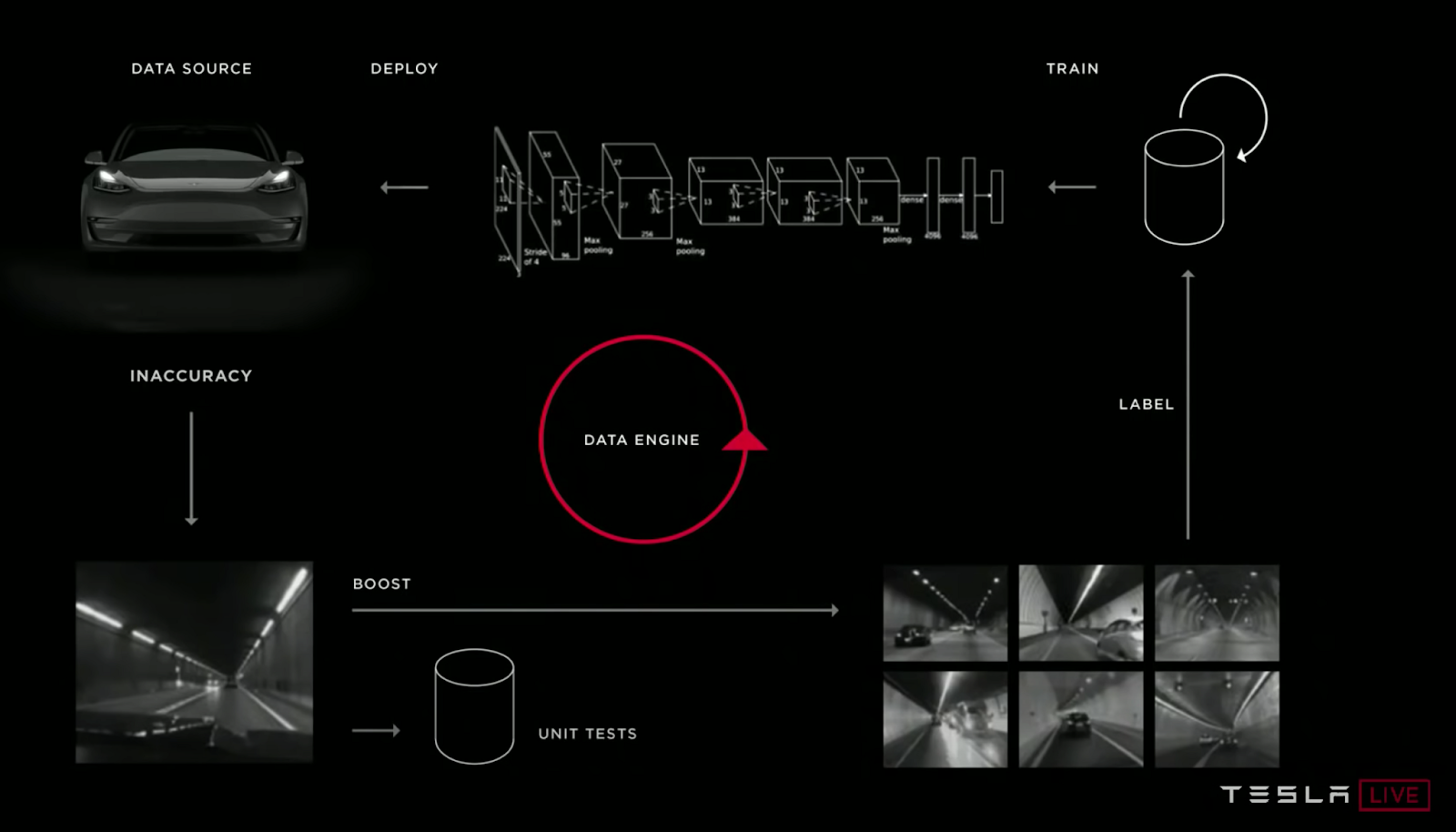
I used to think that machine learning was about the models. Actually, machine learning in production is about pipelines. One of the best predictors of success is the ability to effectively iterate on your model pipeline. That doesn't just mean iterating quickly, but also iterating intelligently. The second part is crucial, otherwise you end up with a pipeline that produces bad models very quickly.
Most traditional software is developed in an agile process that emphasizes quick iterations and delivery. This is because the requirements of the product are unknown and must be discovered through adaptation, so it's better to ship an MVP quickly and iterate than to do exhaustive planning up-front with shaky assumptions.
Just as the requirements of traditional software are complex, the domain of data inputs that ML systems must handle is truly vast. Unlike normal software development, the quality of an ML model depends on its implementation in code and on the data that code trains on. This dependency on the data means that the ML model can "explore" the input domain through dataset construction / curation, allowing it to understand the requirements of the task and adapt to it over time without necessarily having to modify the code.
To take advantage of this property, machine learning needs a concept of continuous learning that emphasizes iteration on the data as well as the code. Machine learning teams have to:
- Uncover problems in the data or model performance
- Diagnose why the problems are happening
- Change the data or the model code to solve these problems
- Validate that the model is getting better after retraining
- Deploy the new model and repeat
Teams should try to go through this cycle at least every month. If you're good, maybe every week.
Massive companies can run through the model deployment cycle in less than a day, but it’s very difficult for most teams to build the infrastructure to do this quickly and automatically. Updating models any less frequently than this can lead to code rot (where the model pipeline breaks due to changes to the codebase) or data domain shifts (where the model in production cannot generalize to changes in the data over time).
However, if done right, a team can get into a good cadence where they are deploying improved models to production on a regular schedule.
Set Up A Feedback Loop

A key part of effective iteration on a model is to focus effort on solving the most impactful problems. To improve a model, you need to be able to know what is wrong with it and be able to triage the problems based on priority for the product / business. There are a lot of ways to set up a feedback loop, but it starts with discovery and triage of errors.
Leverage domain-specific feedback loops. When available, these can be very powerful and efficient ways of getting model feedback. For example, forecasting tasks can get labeled data “for free” by training on historical data of what actually happened, allowing them to continually feed in large amounts of new data and fairly automatically adapt to new situations.
Set up a workflow where a human can review the outputs of your model and flag when an error occurs. This is particularly appropriate when it’s easy for human review to catch mistakes across a lot of model inferences. The most common way this occurs is when customers notice mistakes in the model outputs and complain to the ML team. This is not to be underestimated, as this channel lets you directly incorporate customer feedback into the development cycle! A team can have humans double-check model outputs that a customer might miss: think of an operations person watching a robot sort packages on a conveyor belt and clicking a button whenever they notice an error occurring.
When the models run at too high a frequency for humans to check, consider setting up automated double-checking. This is particularly useful when it’s easy to write “sanity checks” against the model outputs. For example, flagging whenever a lidar object detector and 2D image object detector disagree on a certain object, or when a frame-to-frame detector disagrees with a temporal tracking system. When it works, it provides a lot of helpful feedback on where failure cases occur. When it doesn’t work, it simply exposes errors in your checking system or misses out on situations where all the systems made an error, which is pretty low risk high reward.
The most general (but difficult) solution is to analyze model uncertainty about the data it is running on. A naive example is to look at examples where the model produced low confidence outputs in production. This can surface places where the model is truly uncertain, but it’s not 100% precise. Sometimes the model can be confidently wrong. Sometimes the model is uncertain due to lack of information available to make a good inference (for example, noisy input data that a human would struggle to make sense of). There are models that can solve these problems, but this is an active research area [1].
Lastly, one can utilize feedback from the model’s feedback on the training set. For example, examining the model’s disagreement with its training / validation dataset (i.e. high loss examples) surfaces high-confidence failures or labeling errors. Analysis of neural network embeddings can provide a way to understand patterns of failure modes in the training / validation dataset and find differences in the distribution of the raw data between the training and production datasets.
Automate and Delegate

A big part of iterating faster is reducing the amount of effort needed to do a single cycle of iteration. However, there’s always ways to make things easier, so one must prioritize what to improve. I like to think about effort in two ways: clock time and human time.
Clock time refers to time needed to run certain computational tasks like ETL of data, training models, running inference, calculating metrics, etc. Human time refers to time where a human must actively intervene to run through the pipeline, like manually inspecting results, running commands, or triggering scripts in the middle of the pipeline.
In a production context, human time is a far more limited resource. Intermittent usage of human time also imposes significant switching costs and is inconvenient for the user. Generally, it’s much more important to automate away human time, especially when the time required comes from a skilled ML engineer. For example, it’s extremely common but wasteful to have multiple scripts that must be manually run in sequence with some manual moving of files between steps. Some back of the napkin math: if an ML engineer costs \$90 an hour and wastes even 2 hours per week to manually run scripts, that adds up to \$9360 per year per person! Combining multiple scripts with human interrupts into a single fully-automatic script makes it much faster and easier to run through a single cycle of the model pipeline, saves a lot of money, and makes your ML engineer much less cranky.
In contrast, clock time generally needs to be “reasonable” (e.g.. can be completed overnight) to be acceptable. The exception is if ML engineers are running a huge number of experiments or if there are extreme cost / scaling constraints. This is because clock time is generally proportional to data scale and model complexity. There’s a significant reduction in clock time when moving from local processing to distributed cloud processing. After that, horizontal scaling in the cloud tends to solve most problems for most teams until getting to mega-scale.
Unfortunately, it can be impossible to completely automate certain tasks. Almost all production machine learning applications are supervised learning tasks, and most rely on some amount of human interaction to tell the model what it should do. In some domains, human interaction comes for free (for example, with social media recommendation use cases or other applications with a high volume of direct user feedback). In others, human time is more limited or expensive, such as highly trained radiologists “labeling” CT scans for training data.
Either way, it is important to minimize the amount of time (and associated costs) needed from humans to improve the model. While teams that are early on in the process might rely on an ML engineer to curate the dataset, it’s often more economical (or in the radiologist case, necessary) to have an operations user or domain expert without ML knowledge take on the heavy lifting of data curation. At that point, it becomes important to set up an operational process with good software tooling to label, quality check, improve, and version control the dataset.
When It Works: ML Engineering At The Gym

It can take a lot of time and effort to build adequate tooling to support a new domain or a new user group, but when done well, the results are well worth it! At Cruise, one engineer I worked with was particularly clever (some would say lazy).
This engineer set up an iteration cycle where a combination of operations feedback and metadata queries would sample data to label from places where the model had poor performance. An offshore operations team would then label the data and add it to a new version of the training dataset. The engineer then set up infrastructure that allowed them to run a single script on their computer and kick off a series of cloud jobs that automatically retrained and validated a simple model on the newly added data.
Every week, they ran the retrain script. Then they went to the gym while the model trained and validated itself. After a few hours of gym and dinner, they would return to examine the results. Invariably, the new and improved data would lead to model improvements. After a quick double-check to make sure everything made sense, they then shipped the new model to production and the car’s driving performance would improve. They then spent the rest of the week working on improving the infrastructure, experimenting with new model architectures, and building new model pipelines. Not only did this engineer get their promotion at the end of the quarter, they were in great shape!
The Takeaway
So to recap: in research and prototyping stages, the focus is on building and shipping a model. But as a system moves into production, the name of the game is in building a system that is able to regularly ship improved models with minimal effort. The better you get at this, the more models you can build!
To that end, it pays to focus on:
- Running through the model pipeline on a regular cadence and focusing on shipping models that are better than before. Get a new and improved model into production every week or less!
- Setting up a good feedback loop from the model outputs back to the development process. Figure out what examples the model does poorly on and add more examples to your training dataset.
- Automating tasks in the pipeline that are particularly burdensome and building a team structure that allows your team members to focus on their areas of expertise. Tesla’s Andrej Karpathy calls the ideal end state “Operation Vacation.” I say, set up a workflow where you can send your ML engineers to the gym and let your ML pipeline do the heavy lifting!
As a disclaimer: in my experience, the vast majority of problems with model performance can be solved with data, but there are certain issues that can only be solved with changes to the model code. These changes tend to be very particular to the model architecture at hand - for example, after working on image object detectors for a number of years, I have spent too much time worrying about optimal prior box assignment for certain aspect ratios and improving feature map resolution on small objects. However, as transformers show promise as being the jack-of-all-trades model architecture type for many different deep learning tasks, I suspect more of these tricks will become less relevant and the focus of machine learning development will shift even further towards improving datasets.
Author Bio
Peter is the cofounder and CEO of Aquarium, a company that builds tools to find and fix problems in deep learning datasets. Before Aquarium, Peter worked on machine learning for self driving cars, education, and social media. Feel free to reach out to Peter via LinkedIn if you’d like to talk about ML!
Title Image: "ML Ops Venn Diagram" by Cmbreuel. Licensed under the Creative Commons Attribution-Share Alike 4.0 International license.
References:
[1]: Kendall, A. & Gal, Y. (2017). What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? Advances in Neural Information Processing Systems, 5574-5584.
For attribution in academic contexts or books, please cite this work as
Peter Gao, "Lessons From Deploying Deep Learning To Production", The Gradient, 2022.
BibTeX citation:
@article{gao2022lessons,
author = {Gao, Peter },
title = {Lessons From Deploying Deep Learning To Production},
journal = {The Gradient},
year = {2022},
howpublished = {\url{https://thegradient.pub/lessons-from-deploying-deep-learning-to-production} },
}



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}