
In our work we are often surprised by the fact that most people know about Automatic Speech Recognition (ASR), but know very little about Voice Activity Detection (VAD). It is baffling, because VAD is among the most important and fundamental algorithms in any production or data preparation pipelines related to speech – though it remains mostly “hidden” if it works properly.
Another problem arises if you try to find a high quality VAD with a permissible license. Typically academic solutions are poorly supported, slow, and may not support streaming. Google’s formidable WebRTC VAD is an established and well-known solution, but it has started to show its age. Despite its stellar performance (30ms chunks, << 1ms CPU time per chunk) it often fails to properly distinguish speech from noise. Commercial solutions typically have strings attached and send some or another form of telemetry or are not “free” in other ways.
So we decided to fix this and publish (under a permissible license) our internal VAD satisfying the following criteria:
- High quality;
- Highly portable;
- No strings attached;
- Supports 8 kHz and 16 kHz;
- Supports 30, 60 and 100 ms chunks;
- Trained on 100+ languages, generalizes well;
- One chunk takes ~ 1ms on a single CPU thread. ONNX may be up to 2-3x faster;
In this article we will tell you about Voice Activity Detection in general, describe our approach to VAD metrics, and show how to use our VAD and test it on your own voice.
What is a VAD and what defines a good VAD?
Voice Activity Detection is the problem of looking for voice activity – or in other words, someone speaking – in a continuous audio stream. It is an integral pre-processing step in most voice-related pipelines and an activation trigger for various production pipelines. Typically VAD should be from 1 to 3 orders of magnitude less compute intensive than Speech-to-Text and may live together somewhere with wake word detection in the chain of algorithms.
VAD can be helpful for the following applications:
- Call-center automation (e.g. as a first stage of ASR pipeline);
- Speech detection in mobile or IOT devices;
- Preparation or filtration of audios;
- Voice bots and interfaces;
Basically, VAD should tell speech apart from noise and silence. The input is just a small audio chunk, and the output is a probability that this chunk contains speech given its history. Seems easy enough, just a binary classifier, you say? Well yeah, but as usual the devil is in the details.
If we abstract from the nuts and bolts for a bit, to be competitive a modern VAD should satisfy four main criteria:
- High quality. It may depend per application, but higher precision or recall may be preferable in different situations;
- Low user perceived latency, i.e. CPU latency + audio chunk size. Typically anything lower than 100 ms is good enough. Quite often speech chunks shorter than 100 ms are not really meaningful even to humans;
- Good generalization, i.e. it should work reasonably well for all domains, audio sources, noise, quality and SNR levels and require only minor fiddling with hyper-parameters;
- Portability in general sense, i.e. be easy and cheap to port, install and run;
In practice a well trained VAD behaves somewhat like this (notice that some loud sounds are not speech):
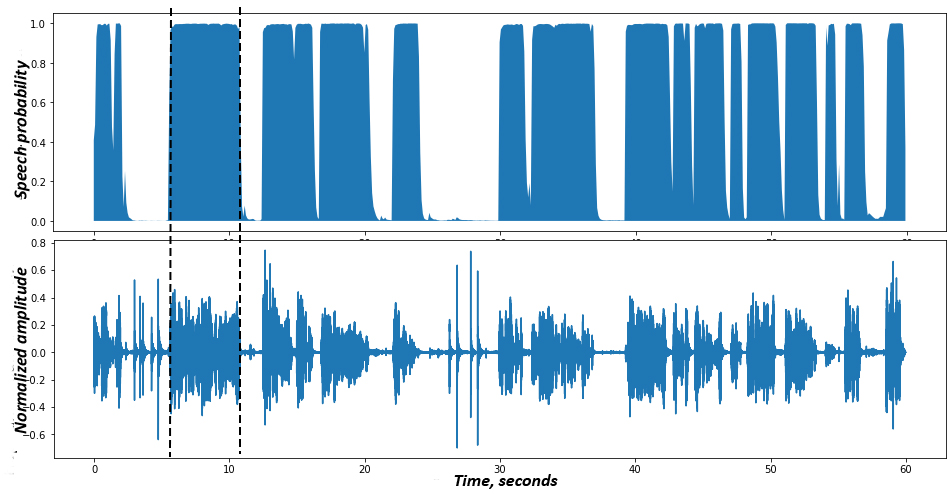
Other solutions
Although there are many public VADs out there, not all of them are production ready. A decent production ready VAD should strike a fine balance between low compute / latency and decent modern quality. We did not find a solution that would satisfy all of our criteria. Plus the majority of “open” solutions receive little to no frequent updates and mostly serve as demonstrations or research artifacts. This is why we decided to develop our own VAD.
The table below summarizes the advantages and limitations of most popular available VAD engines. All information was sourced from the documentation, public issues, code, colab notebooks and examples.
Even though we were not able to calculate the latency and quality metrics for all of the models shown in the table, сhunk size can indirectly indicate the delay and / or compute. Our main goal was to make a production-ready easy-to-use model that could be used by other people without installing tons of dependencies and that could be easily integrated for streaming tasks while maintaining decent quality.
| Model Name | License | Chunk Size | Streaming-ready | Model Size, MB | Sampling Rate |
|---|---|---|---|---|---|
| Pyannote | MIT | 2000 ms | No* | 2.4 | 16 kHz |
| NeMo | Apache 2.0 | 630 ms | No* | 0.3 | 16 kHz |
| SpeechBrain | Apache 2.0 | Unclear | No | 0.4 | 16 kHz |
| WebRTC VAD | Custom | 10, 20, or 30 ms | Yes | Very small | 8, 16, 32 or 48 kHz |
| Commercial VAD | Apache 2.0 | 30 ms | Yes | Very small | 16 kHz |
| Silero | MIT | 30, 60, 100 ms | Yes | 0.8 | 8, 16, 32 or 48 kHz |
*(window streaming)
Also it is notable that the solutions may differ in the amount of languages and data used for their training. VADs are much less data hungry than speech-to-text models, but a correlation between generalization, quality and amount of data used is still observed. We trained our VAD on approximately 13k hours of speech spanning 100 languages. Academic solutions typically lean towards using several small academic datasets. Commercial solutions usually do not disclose how they were trained (or we did not search well enough).
Our solution
A few days back we published a new totally reworked Silero VAD. You can try it on your own voice via interactive demo with a video here or via basic demo here. We employ a multi-head attention (MHA) based neural network under the hood with the Short-time Fourier transform as features. This architecture was chosen due to the fact that MHA-based networks have shown promising results in many applications ranging from natural language processing to computer vision and speech processing, but our experiments and recent papers show that you can achieve good results with any sort of fully feedforward network, you just need to do enough experiments (i.e. typical choices are MHA-only or transformer networks, convolutional neural networks or their hybrids) and optimize the architecture.
Our VAD satisfies the following criteria:
- High quality: see the testing methodology below;
- Highly portable: it can run everywhere PyTorch and ONNX can run;
- No strings attached: no registration, licensing codes, compilation required;
- Supports 8 kHz and 16 kHz. The PyTorch model also accepts 32 kHz and 48 kHz and resamples audios from these sample rates to 16 kHz by slicing;
- Supports 30, 60 and 100 ms chunks;
- Trained on 100+ languages, generalizes well;
- One chunk takes ~ 1ms on a single CPU thread. ONNX may be up to 2-3x faster;
Overall VAD invocation in python is as easy as (VAD requires PyTorch > 1.9)
import torch
torch.set_num_threads(1)
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad', model='silero_vad')
(get_speech_timestamps, _, read_audio, _, _) = utils
wav = read_audio('test.wav', sampling_rate=16000)
speech_timestamps = get_speech_timestamps(wav, model, sampling_rate=16000, visualize_probs=True, return_seconds=True)
For more usage examples (including streaming) and tutorials, please see the repo, the links section and FAQ.
Testing methodology
Test dataset collection for a VAD with a 30 ms chunk is a challenge. Ideally, you would divide each audio in such chunks and manually annotate each chunk with 1 or 0. But in real life this may be prohibitively expensive and introduce a lot of errors and bias (people are notorious for being inaccurate and have problems with short speech chunks).
Of course you can ask assessors to mark only the start and end timestamps, but in real life this becomes messy and problematic too, just take a look at the below chart:

It is easy to see that with real speech usually there are no clear well-defined boundaries, sometimes there are many short chunks separated by very brief pauses. Nevertheless most likely people will just mark “global” start and end.
We chose a much simpler and more concise testing methodology - annotate the whole utterance with 1 or 0 depending on whether it has any speech at all. The rules are as follows:
- If the voice is loud enough - it is speech;
- Background murmur is considered speech only if is legible;
- Laughter, screams, murmur are also considered speech;
- Singing with legible worlds is also speech;
- House pet sounds and screams, background bird singing are not speech;
- City sounds, applause, crowd noises and chants are not considered speech;
- Any other non-human sounds are not speech also;
Following these criteria we collected the following test dataset:
- 30+ languages;
- 2,200 utterances, average duration ~7 seconds, 55% contain speech;
- A wide variety of domains and audio sources (calls, studio records, noisy audios with background noise or speech, etc);
At this moment an ambiguity arises. We have 7 second long audios, but the model classifies 30 ms long chunks! Each utterance contains hundreds of such chunks. In practice though, meaningful speech is usually longer than 250 ms. Of course there are exceptions, but they are rare.
Ok, if we have 250ms of consecutive non-interrupted speech then we are golden. But what if we have 150ms of speech, slight silence and then 150ms more speech (see the above chart)? In this case we wait up to 250ms to allow speech to continue. The above chart shows the most important cases.
The VAD predicts a probability for each audio chunk to have speech or not. In the majority of cases a default 50% threshold works fine, but there are some exceptions and some minor fine-tuning may be required per domain.
The whole testing pipeline can be described as follows:
- Get an array of probability predictions for each utterance in the test set;
- Using the above algorithm, calculate whether there is speech in a give utterance for different thresholds ranging from 0 to 1;
- Calculate Recall and Precision for each threshold value;
- Draw a Precision-Recall curve;
Quality metrics
We decided to compare our new model with the following models:
- WebRTC VAD with a 30ms chunk;
- Another commercial VAD with a 30ms chunk;
All of the tests were run with 16 kHz sampling rate.
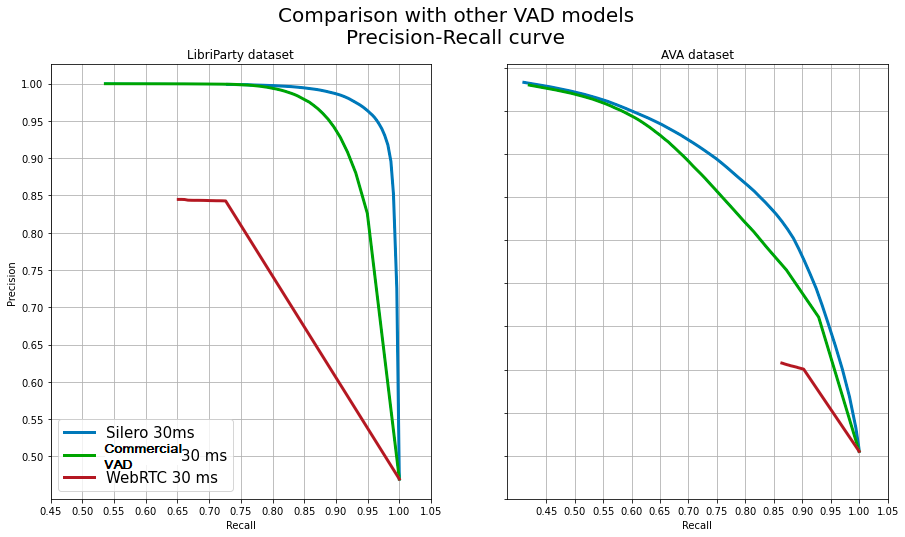
You can find all of the quality metrics and comparisons here.
Performance metrics
There is not really much to it. One chunk takes around 1 ms with a PyTorch model regardless of the chunks size. If you batch inputs across several audio streams, the throughput across several audios will become even more impressive. Surprisingly, people reported that the ONNX model is 30-60% faster, which we previously observed for small STT models. Torch freeze also provides around a 5-10% speed bump.
Conclusion
Voice activity detection seems a more or less solved task due to its simplicity and abundance of data. As it usually happens, public academic solutions have issues and enterprise / commercial solutions have strings attached (or poor quality). We tried to fill the spot where we have proper quality, easy-to-use fast minimalistic models, no strings attached and decent generalization with 100+ languages.
As for other VAD-related tasks, there remain many unsolved, partially solved, poorly defined or less researched complementary tasks like music detection, audio event classification, and generalizable wake word detection. Integrating some of these tasks inside of our VAD model or solving some of the speaker diarization challenges without sacrificing the core values we brought to the table in our VAD would be a challenge for the future releases.
References
- Social media / discussions:
- Reddit thread
- A discussion about different VADs
- А ты используешь VAD? Что это такое и зачем он нужен
- Silero VAD:
- Silero VAD repository
- Silero VAD examples
- Silero VAD quality metrics
- Silero VAD performance metrics
- Pyannote:
- PyAnnote VAD
- Streaming voice activity detection with pyannote.audio | Hervé Bredin
- NeMo:
- Voice Activity Detection Demo
- NeMo VAD Demo
- SpeechBrain:
- SpeechBrain VAD streaming
- SpeechBrain collab example
- WebRTC VAD:
- Python WebRTC VAD interface
Author Bio
Alexander Veysov is a Data Scientist in Silero, a small company building NLP / Speech / CV enabled products, and author of Open STT - probably the largest public Russian spoken corpus (we are planning to add more languages). Silero has recently shipped its own Russian STT engine. Previously he worked in a then Moscow-based VC firm and Ponominalu.ru, a ticketing startup acquired by MTS (major Russian TelCo). He received his BA and MA in Economics in Moscow State University for International Relations (MGIMO). You can follow his channel in telegram (@snakers41).
Citation
For attribution in academic contexts or books, please cite this work as
Alexander Veysov and Dimitrii Voronin, "One Voice Detector to Rule Them All", The Gradient, 2022.
BibTeX citation:
@article{veysov20202onevoice,
author = {Veysov, Alexander and Voronin, Dimitrii},
title = {One Voice Detector to Rule Them All},
journal = {The Gradient},
year = {2022},
howpublished = {\url{https://thegradient.pub/one-voice-detector-to-rule-them-all/ } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.





{kind=link}
{kind=link}
{kind=link}
{kind=link}