
In response to Dear OpenAI: Please Open Source Your Language Model
In a world where researchers and corporations emphasize their goals of "democratizing AI" and "AI for everyone," there is an almost-universal perception that access to AI is an inherent good. However, as AI becomes more powerful, it becomes increasingly important that they are being used to optimize goals beneficial to humanity.
OpenAI's new GPT-2 language model can often generate long paragraphs of coherent text; their choice not to make it open-source has inspired a fair amount of controversy. While references to previous technologies like Photoshop which allowed for fake media may seem relevant, fake media has never been so easy to generate and we have never been more reliant on social media as a source of truth. If you haven't, I strongly recommend reading their initial post, Better Language Models and Their Implications. I argue that OpenAI's choice in this case is justified: considering the impact and misuse of released models is the only sustainable path to progress in AI research.

Misuses of GPT-2
GPT-2 probably won't break the internet, but it could make it a much worse place.
Astroturfing
Astroturfing is creating the false appearance (typically online) that something is widely supported, basically as artificial grassroots support.
It's been engaged in by companies including Exxon Mobil, McDonald's, Comcast, Walmart, and several lobbyist firms. Astroturfing was used during the 2016 election, used to create fake support for the FCC's choice to reject net neutrality which the FCC later justified their choice with, and is used by foreign governments to derail online conversations. There are other avenues by which this happens today: Some news organizations allow native advertising, where corporations publish what are, in effect, advertisements, as if they were news stories.
While the texts generated by GPT-2 have some internal consistency issues, especially the longer ones, it nevertheless poses a genuinely worrying prospect: the ability to easily generate arbitrarily many diverse, short, realistic, practically undetectable snippets of text immediately in support of any issue in response to any article (or, honestly, headline). The same can be done by any collection of individuals that want to create the appearance of support on the internet. While the FCC's large-scale astroturfing was given away by its choice to use almost exactly the same formats for all of its fake posts in support of ending net neutrality, and human astroturfing is time-consuming and expensive, models such as GPT-2 allow the two to be married without much effort.
The Verge quotes Jeremy Howard, the co-founder of fast.ai:
We have the technology to totally fill Twitter, email, and the web up with reasonable-sounding, context-appropriate prose, which would drown out all other speech and be impossible to filter.
Note that this really isn't about spam, but about shaping the conversation and creating the appearance of consensus where it doesn't exist. The capacity to perform AI-powered astroturfing is not something we've dealt with before, and it'll only become harder to detect as language models improve. I'll note that Google's reCAPTCHA has shifted towards more identity/activity-based anti-spam verification, which should, at least temporarily, help with these kinds of attacks.

Fake News
Closely connected to the topic of astroturfing, as tabloid-style journalism has been given a breath of fresh air by social media, roughly 23% of Americans admit to having shared fake news. While the hope is that this could be counteracted with increased awareness and technological countermeasures, fake news continues to improve. GPT-2 may not able to generate convincing internally-consistent fake news, but fake news already didn't need to be internally consistent or convincing. It just needed to roughly reiterate what the headline said (and fake-news headline generation has long been solved). The Guardian has released some especially worrying examples with Brexit, showing how easily the model generates realistic text about its effects.
GPT-2 is Not Not a Big Deal
OpenAI's full language model, while not a massive leap algorithmically, is a substantial (compute and data-driven) improvement in modeling long-range relationships in text, and consequently, long-form language generation.
Perplexity
There's a recurring trope about the new OpenAI model that comes up in a lot of online discussion of the new paper: it's not that much better or different than state of the art or even OpenAI's previously released algorithms. I don't think the exact degree of improvement is central to my argument, but I do think this is an important point to respond to, since it's often used to dismiss this conversation out of hand. This new model corresponds to a step forward over state-of-the-art (SotA) in performance on several datasets, especially those which evaluate long-range relationships within text. The LAMBADA and WikiText datasets are the two measurements of this long-range structure which I'll focus on here.
The LAMBADA dataset measures the ability to predict the next word in long-form text. There's a great discussion of the challenges that come from the LAMBADA dataset in Chu et. al's Broad Context Language Modeling as Reading Comprehension. Essentially, it was too hard and all existing approaches performed very poorly. Here's an example question:
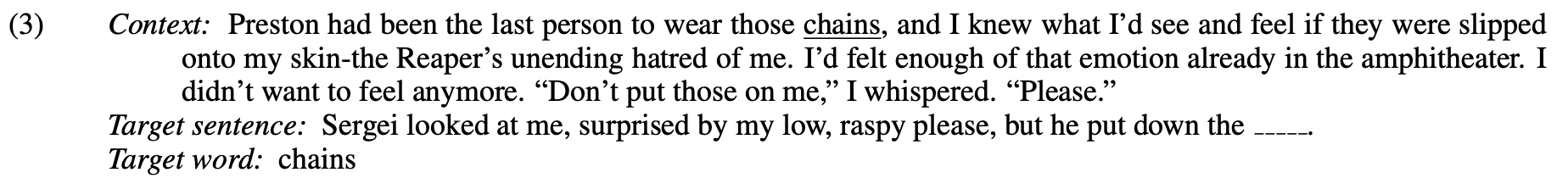
The LAMBADA dataset: Word prediction requiring a broad discourse context
For context, a useful measure of generative ability is perplexity (distributional distance), which not only rewards accurate guesses, but prioritizes confident accurate guesses. Humans manage a perplexity of roughly 1-2 on LAMBADA, where lower is better, while OpenAI claims that previous the SotA solution perform over an order of magnitude worse at 99. However, GPT-2 earns an 8.6, which is by far the closest natural language algorithms have ever come to anticipating long-form discourse.
Something that has been lost in a lot of conversation is that most of the NLP-originating criticism of the model is not that it's a minor improvement: it's that the model is algorithmically similar to existing ones that have been released, so much of the improvement is said to come from additional data and computational power. This is a fair criticism, but there is value in recognizing what is possible with models which are algorithmically similar to the ones that exist when given more resources. As shown in the graph below, there are several improvements over state-of-the-art from their approach (I'll talk more about LAMBADA in a bit). However, existing models like Transformer-XL (which is in many ways similar to GPT-2) also score well in perplexity on several problems. While there is no data on Transformer-XL's perplexity performance on LAMBADA, the Universal Transformer model only scored a 136, worse than the 2016 paper.
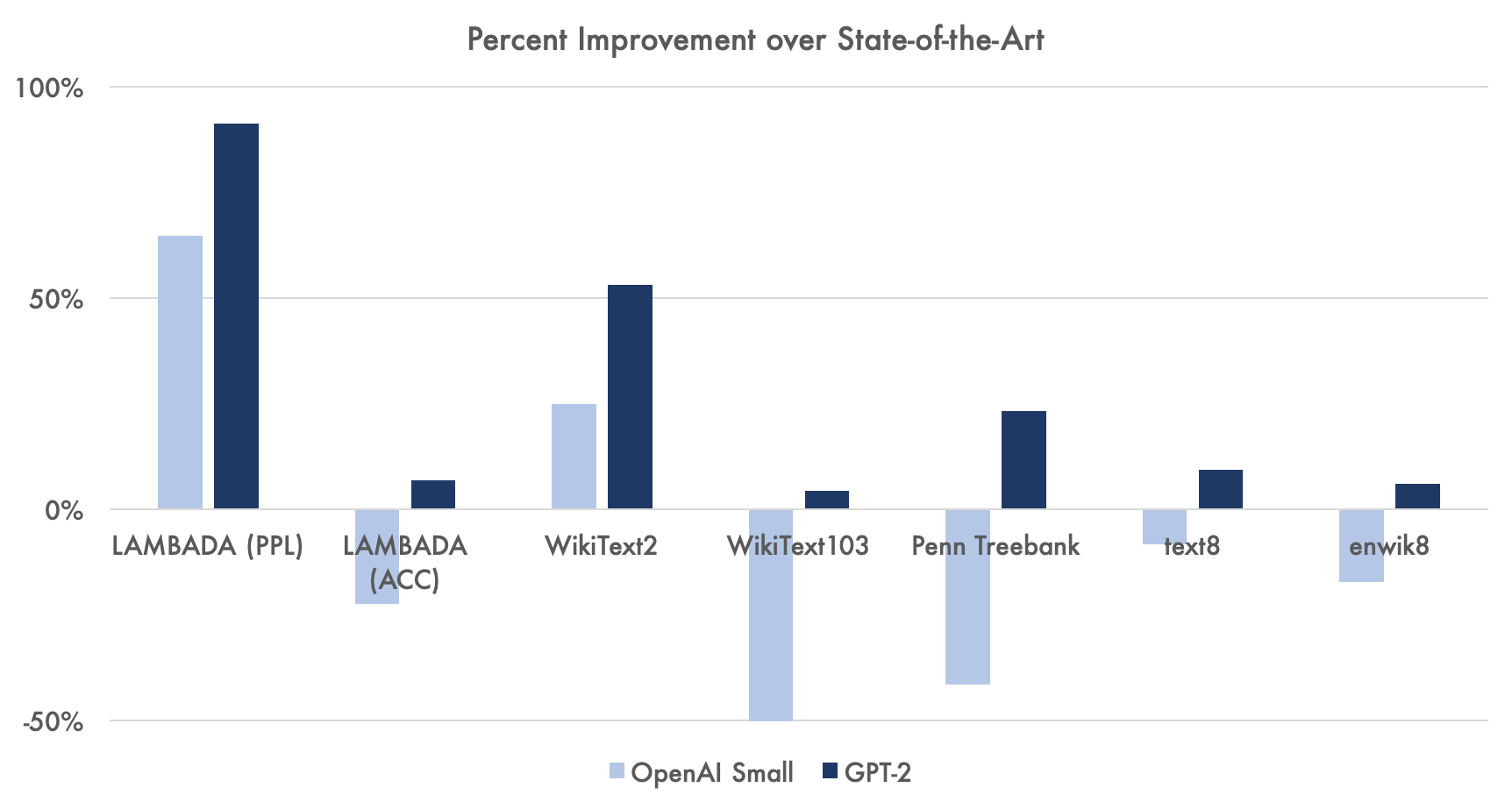
For some comparison, the WikiText-103 dataset includes high-quality Wikipedia articles and, like LAMBADA, is used to evaluate how well language models understand long-range dependencies in language. It's also said to be a lot easier than LAMBADA. A tuned version of Transformer-XL, trained specifically on the massive WikiText-103 corpus, earned the former SotA perplexity of 18.3. Without any tweaking or training specific to WikiText, GPT-2 earned 17.48. OpenAI describes this as zero-shot learning, though 2-9% of the WikiText data overlaps with their data, which is to be expected. However, getting a generalist model to outperform a task-specific model is always impressive and challenging, and this difficulty shows. As a function of the number of parameters, GPT-2 is much more computationally taxing than its smaller versions, and even the smallest OpenAI language model has 117 million parameters, while Transformer-"XL" had up to 151 million, as shown in the graph of perplexity vs parameter Count.
Previous Long-form Text Generation Approaches
Here's another example from Facebook AI's fairly impressive Hierarchical Neural Story Generation from last year:

Note that this text, while still impressive, is shorter and more repetitive and has simpler and more uniform prompts. Even in this short text, there are internal consistency problems: for example, do the scientists think they found a virus, a chemical, something unknown made of some chemical, or a monster? I would include more examples of long-form text generation, but remarkably few papers have released them. What I will note is that even on easier long-form text generation challenges, scores lower than 40 are challenging and rare.
In short, a lot of the criticism from the NLP community isn't that the model doesn't perform well: it really is a non-negligible bit better than existing models at long-form text generation. However, it's often said to be not that algorithmically novel. That is, most of the improvement comes from the massive data and compute power they threw at something which wasn't all-that-different from what's already out there. One might ask, if most of the improvement comes from the additional resources used for this model, is it even worth publishing with only the smaller model? My answer is an unequivocal yes: it is valuable to see what's actually currently possible, and seeing as this model doesn't seem to plateau, it is likely possible to improve even more.
The reality is, regardless of whether or not OpenAI releases the model, it is unlikely that this will last. An implementation of this model will probably be available online within a few months, if not to some collective's message to spite OpenAI then perhaps by some foreign power which recognizes the value of further deteriorating communication on the internet.
How Can We Adapt?
One line of argument goes, essentially, that if you can't stop the flood, you should figure out how to live underwater. That is, when people know a threat exists, they are better able to deal with it.
While the public in general has become wary of photos as evidence online because of Photoshop, and is increasingly wary of online videos as documentation because of the increasing ease of video editing and generating deep fakes, there are several things that make this different. First, photos and video are not and have never been the primary means by which we tell one another something: written and spoken language are, and likely always will be, the basis of almost all human communication of information about the world. While sites like Instagram and YouTube are popular, when they're used in an informational context, the images are usually used to reinforce rather than to prove the underlying spoken or written content. As social media tends towards reliance on individual trust in verifying information and trust in the press (and in general) declines in the US, the communication of ideas on social media is already at a low point.
We have to ask ourselves, what exactly does it mean to "learn to live underwater" in this context? If generating realistic but entirely fake networks of communication stopped being expensive and requiring large-scale effort, our relationship with online communication would change dramatically. It seems like at least one of a few characteristics of the internet might be lost, where the loss of any of these features seems unappealing. If we assume it's eventually or currently possible to produce short text which is indistinguishable from human text, it seems to become necessary to either push at the limits of the technical capabilities or to make sure the text is actually human.

De-anonymization
One solution that presents itself seems to be the removal of anonymity. This carries several issues with it. First, while a large number of people use sites like Twitter or Facebook to keep track of the thoughts of particular users, on Twitter, a minuscule roughly 0.1% of its users are verified. This means that, aside from a friend directly inviting someone to follow their account, there's little guarantee that any account that's followed is a human rather than a robot. Verifying every user seems like the only effective way to remove anonymity, because many of the conversations on these sites (certainly the ones that are public) happen between groups of people where not every person knows every other person. This is even more true for sites which the people posting usually have no explicit association with their online identities. These sites include reddit, which receives a similar amount of traffic as Twitter, and would be basically flooded with fake-but-realistic biased posting if a complete generative text model was published. One intermediate solution is verified but anonymous accounts, which seems like a likely outcome. This has the vulnerability of people selling their accounts and is generally much harder to grow, but it creates some stability. This approach also becomes more tricky as language style transfer improves, and you can just pay someone to publish something that looks like it was written by them.
Trust
Alternatively, we can rely on people being careful with who they trust online, building a tight web of people they trust, where everyone believes the people they trust are also following the same strategy. I'm skeptical of this solution. First, it basically formalizes echo chambers. Second, trust isn't transitive, so you don't necessarily trust someone that someone you trust trusts. Also, it's pretty fundamentally incompatible with the idea with a forum, so this only really works on a small-conversation level. You can't just ignore bot accounts on a forum when most of the accounts are bot accounts and their comments are indistinguishable from normal comments.
Complexity
Another (temporary) solution that sounds feasible at a glance is just increasing the length and complexity of the things we write online. OpenAI's approach fails to generate perfect and compelling long-form pieces, but people also don't tend to want to write an essay every time they comment on something. Perhaps this solution is unavoidable, though, some kind of reverse-Twitter, where instead of a character-max there would be a character-min. It seems unlikely that this would develop unless this was already a rampant problem though, and it's also unclear how permanent of a fix it would be, since it's plausible that with more data and a few tweaks an OpenAI-style model would be able to overcome these challenges too.

Caveats
Legitimate Actors
I think there are legitimate research uses for OpenAI's model, and it probably makes sense to distribute it to some non-profit institutions, under contract for specific and well-defined research objectives, for the sake of the safe advancement of AI research. One point absolutely carries over from the photoshop comparison, and that is that awareness of a technology and its function is still crucial in order to counter that technology.
Illegitimate Actors
There is a second, worrying issue: some of the actors which I've discussed which can get the most value out of a model like this are exactly the ones that would be able to replicate the results of the model in the first place. Large corporations and governments can easily fund their own version of this open-source model, possibly uniquely suited for their tasks. This is, to me, a compelling argument for strict and explicit policy guidelines on the online use and distribution of generative models by corporations (though, of course, the enforcement becomes challenging for non-US based companies, requiring some level of international cooperation). OpenAI's choice not to open-source their model gives lawmakers some opportunity to respond to this.
Free and Open Research
According to Nick Cammarata, Interpretability at OpenAI:
There's been a lot of discussion internally and externally about whether to release GPT-2 and future language models. In my experience I've seen that people who start with a pro-release intuition tend to soften their views after engaging with the benefits and safety concerns more thoughtfully. Personally, it makes me sad when I think about the tinkerers who could have built wonderful new applications or startups using GPT-2 as a base for understanding language that can't now. Overall though, I think we've handled things the responsible way so far. As we mention in the post, this is an experiment in responsible release, and we encourage the field to think more about release strategies and potentially find ways to capture this upside without compromising safety.
As someone who has consistently been in the "pro-release intuition" camp, I found this recent case to be a useful challenge. This raise an important question: what does this mean for AI research in general? On the immediately practicable side, in AI research, a constant consideration of the ethical consequences of one's work is crucial, especially when operating on the computing scale of the largest players in the field today. While it's essentially impossible to quantify how far we are from something that can be reasonable quantified as general AI, the technology that already exists can be used in dangerous ways and every person in the field has a responsibility to do what they can in preventing its misuse.
While one appeal of machine learning research is the ease of testing and publishing new approaches, it may also be time to ask for some of this responsibility to be taken up by often-misunderstood institutional review boards, which are currently primarily intended to protect the subjects of research. This misuse can be intentional or unintentional, and part of solving it is emphasizing the role of these ethical questions when mentoring new up-and-coming AI researchers as the field is "democratized."

Legislation Needs Hype
There's an important meta aspect to this: the choice to restrict ethically-borderline AI research which is not openly available to the overall public encourages us to have these conversations and question the intuitions which have been reinforced in most of us who were curious enough about machine learning to get involved in research. It's important we have these conversations on lower-consequence examples to build up expectations and guidelines for the harder examples. I would probably be on the "we should delay it x months" boat if I believed there was a length of time in which the implications of a study would be addressed in law and in the AI community. However, simply saying "we won't release this until better laws are in place" sounds like a threat and so there's much greater pathos in just saying just that you're not releasing the model at all. The crux of my point is that this is a good toy example, with real implications to its release, and while we're not talking about Skynet, we shouldn't wait until we reach that point to start asking these questions.
Ultimately, I don't think we can expect the field to completely self-regulate. If something is profitable and legal, even if unethical, some organization will eventually do it. Proactive laws are a must, and this case reinforces that. First, without clear multinational agreements to restrict the ways in which AI technology can be used by corporations and governments to affect the public, the choice to publish models which have substantial likelihood of large-scale social damage is unethical. Second, we need to formalize accountability structures when a corporation negligently or maliciously releases or uses AI and causes harm, most of which I suspect are already implicit in existing laws. Third, we need to discuss the increasingly close relationship between multinational tech companies and AI research, and ask whether a distinction should exist between the models which they are allowed to develop for the purpose of research and for commercial purposes. What exactly these agreements and structures are is less important than the presence of a protocol or some clear language for standard procedures.
With these considerations in mind and these legal frameworks in place, it should create an environment for safer collaboration and research. To me, OpenAI's choice to not release this model has accomplished something really valuable, and made clear why this "experiment in responsible release" needed to happen. It's forced us to confront important ethical and ideological questions, no longer in an abstract context, but in one with real though limited impacts.
Dear OpenAI: thanks for helping start this conversation.
Special thanks to Andrey Kurenkov, Hugh Zhang, Nancy Xu, and Alex Li for their feedback, suggestions, and insights.
Cover image source. Unicorn photo by Nicole Honeywill. Grass photo by Sandro Schuh. Undersea city fractal from Max Pixel. Lightbulb photo by Alexandru Goman.
Eric Zelikman is a Stanford student whose research has focused on semantic representations and biologically-feasible learning. In industry, he has worked mostly on designing novel, highly sample-efficient AI architectures and architecture-agnostic approaches to interpretability. Hear him vent about AI on Twitter!
Citation
For attribution in academic contexts or books, please cite this work as
Eric Zelikman, "OpenAI Shouldn’t Release Their Full Language Model", The Gradient, 2019.
BibTeX citation:
@article{ZelikmanOpenAI2019,
author = {Zelikman, Eric}
title = {OpenAI Shouldn’t Release Their Full Language Model},
journal = {The Gradient},
year = {2019},
howpublished = {\url{https://thegradient.pub/openai-shouldnt-release-their-full-language-model/ } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.



{kind=link}
{kind=link}
{kind=link}
{kind=link}