Over the past decade, machine learning (ML) has become a critical component of countless applications and services in a variety of domains. Fields ranging from healthcare to autonomous vehicles have been transformed by the use of ML techniques.
Machine learning’s increasing importance to real-world applications brought awareness of a new field focused on ML in practice - machine learning systems (or, as some call it, MLOps). This field acts as a bridging point between the domains of computer systems and machine learning, considering the new challenges of machine learning with a lens shaped by traditional systems research.
So what are these “ML challenges”?
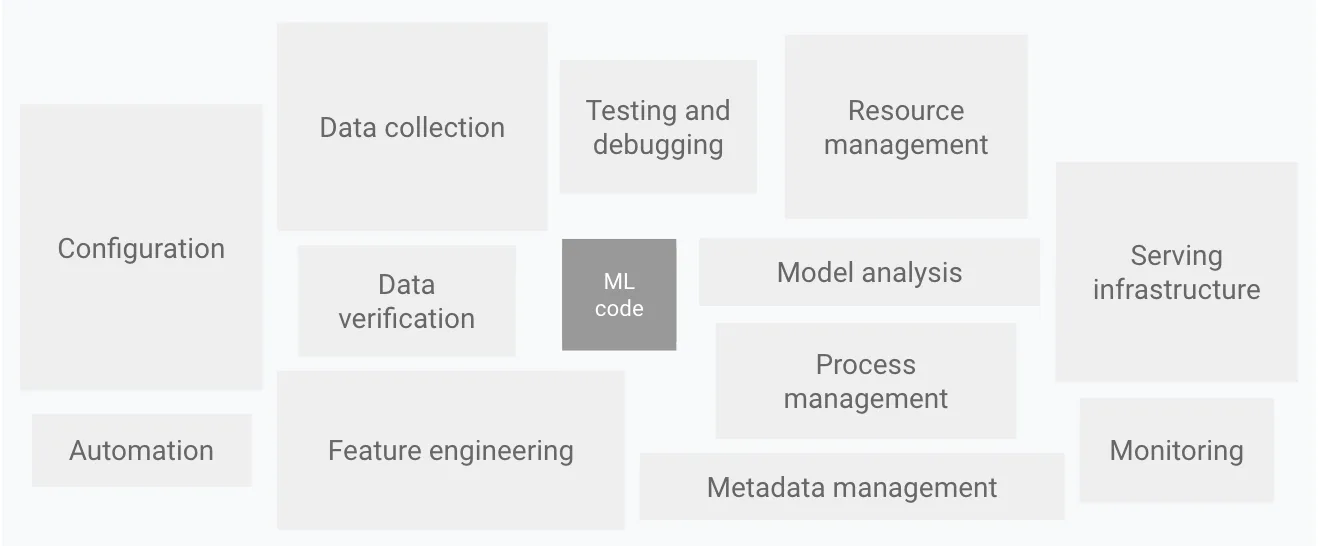
To describe the problems of a typical ML system and break down its components, I’ll use the architecture proposed in D. Sculley’s “Hidden Technical Debt in Machine Learning Systems” (2015).
I’ll primarily focus on challenges in data collection, verification, and serving tasks. I’ll also discuss some of the problems in model training, as it’s become an increasingly expensive part of system development in recent years.
Data Collection
While researchers may be content to use readily available datasets such as CIFAR or SQuAD, industry practitioners often need to manually label and generate custom datasets for model training. But creating such datasets, particularly when domain expertise is required, can be tremendously expensive.
This is certainly a major challenge for machine learning system developers.
Fittingly, one of the most successful solutions to this problem borrows research from both systems and machine learning. Combining data management techniques with work on self-supervised learning, SnorkelAI uses a “weakly-supervised data programming” approach.
SnorkelAI reimagines dataset creation as a programming problem, where users can specify functions for weakly supervised labeling that can then be combined and weighted to produce high quality labels. Expert-labelled data (high quality) and auto-labelled data (low quality) can be merged and tracked to ensure that model training is accurately weighted to account for varying levels of label quality.
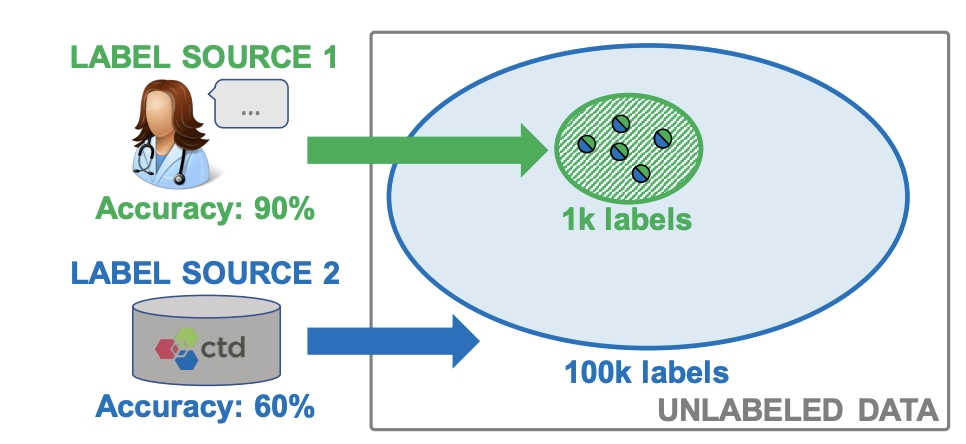
The technique is reminiscent of data fusion from database management systems - the application to machine learning is a pivot and redesign rather than a revolutionary creation made solely for ML. By identifying a shared problem in both systems and ML - combining data sources - we can apply traditional systems techniques to a machine learning setting.
Data Verification
Data verification serves as a natural follow-up to data collection. Data quality is a critical problem for machine learning pipelines. To use the common phrase, “garbage in, garbage out.” To produce high quality models for their system, the maintainer has to ensure that the data they’re feeding in is also high quality.
The problem cannot easily be solved by adjusting our approach to machine learning - we need to adjust the system. Fortunately, while data validation for ML is a new problem, data validation is not.
To quote the TensorFlow Data Validation (TFDV) paper:
“Data validation is neither a new problem nor unique to ML, and so we borrow solutions from related fields (e.g., database systems). However, we argue that the problem acquires unique challenges in the context of ML and hence we need to rethink existing solutions”
Once again, by identifying a parallel challenge between machine learning systems and traditional computer systems, we’re able to reuse existing solutions with some ML-oriented modifications.
TFDV’s solution uses a “battle-tested” solution from data management systems - schemas. A database enforces properties to ensure that data inputs and updates adhere to a specified format. Similarly, TFDV’s data schemas enforce rules upon the data being inputted to the model.
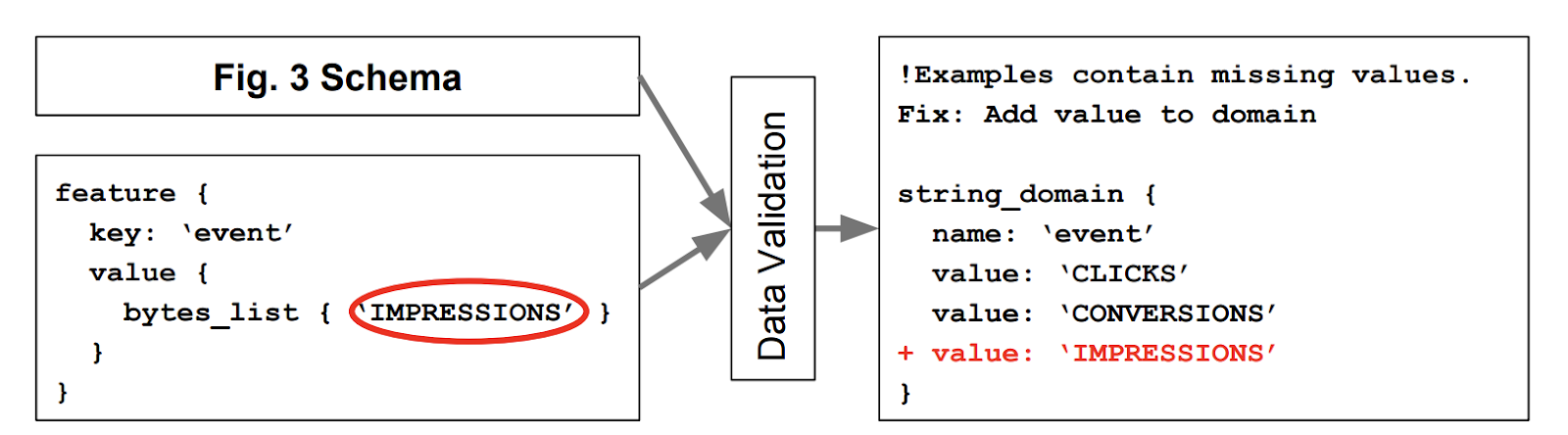
Of course, there are some differences, reflecting how machine learning systems differ from the traditional paradigm. ML schemas need to evolve and adapt over time to account for distribution shifts, and also need to account for changes that could be made to the model itself over the system’s lifecycle.
It’s evident that machine learning presents a new type of systems challenge. But these systems bring in as much of the old as they do of the new. Before we look to reinvent the wheel, we should leverage what’s already available.
Model Training
ML practitioners may be surprised at the inclusion of model training as an area for system optimizations. After all, if there’s one area of machine learning applications that truly relies on ML techniques, it’s training. But even here, systems research has a role to play.
Let’s take the example of model parallelism. With the rise of Transformers, various applied ML domains have seen a dramatic increase in model sizes. A few years back, BERT-Large pushed boundaries at 345M parameters, and now Megatron-LM boasts over a trillion parameters.
The sheer memory costs of these models can reach hundreds of gigabytes. No single GPU can hold them. The traditional solution, model parallelism, takes a relatively simplistic approach - partitioning the model across different devices to distribute memory costs.
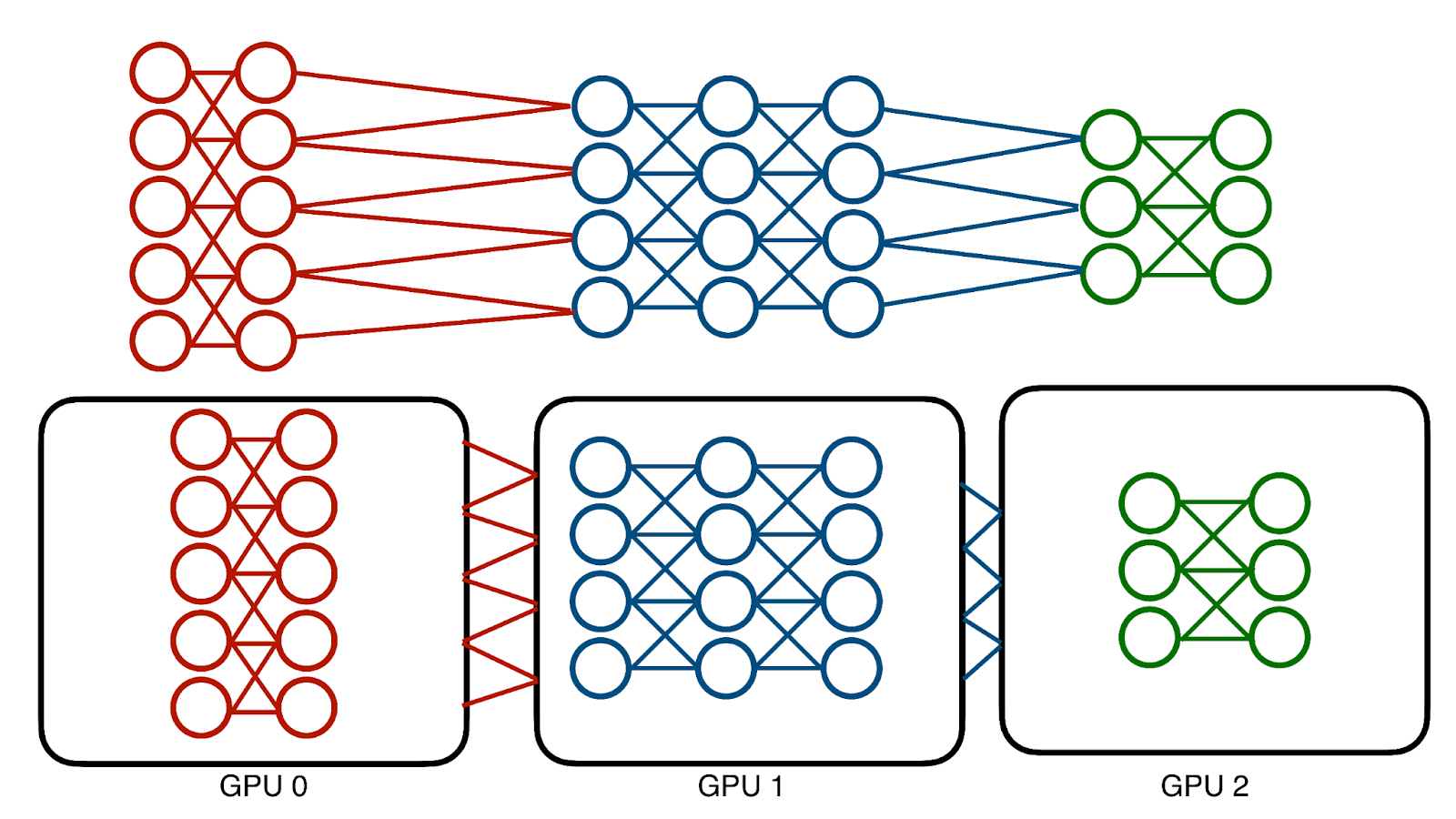
But this technique is problematic: the model is sequential by its very nature, and training it requires passing data backwards and forwards through layers. Only one layer, and only one device, can be used at a time. This translates to terrible device under-utilization,,.
But how can systems research help?
Consider a deep neural network. Broken down to its lowest components, it can be considered a series of operators transforming data. Training simply refers to the process wherein we pass data through the operators, produce gradients, and feed the gradients back through the operators to update them.
Broken down at this level, the model starts to resemble other staged operations - a CPU’s instruction pipeline, for example. Two systems, GPipe and Hydra, attempt to use this parallel to apply system optimizations for scalability and parallelism.
GPipe embraces this CPU instruction parallel to turn model training into a pipelining problem. Each partition of the model is considered a different stage of the pipe, and minibatches are staged out through the partitions to maximize utilization.
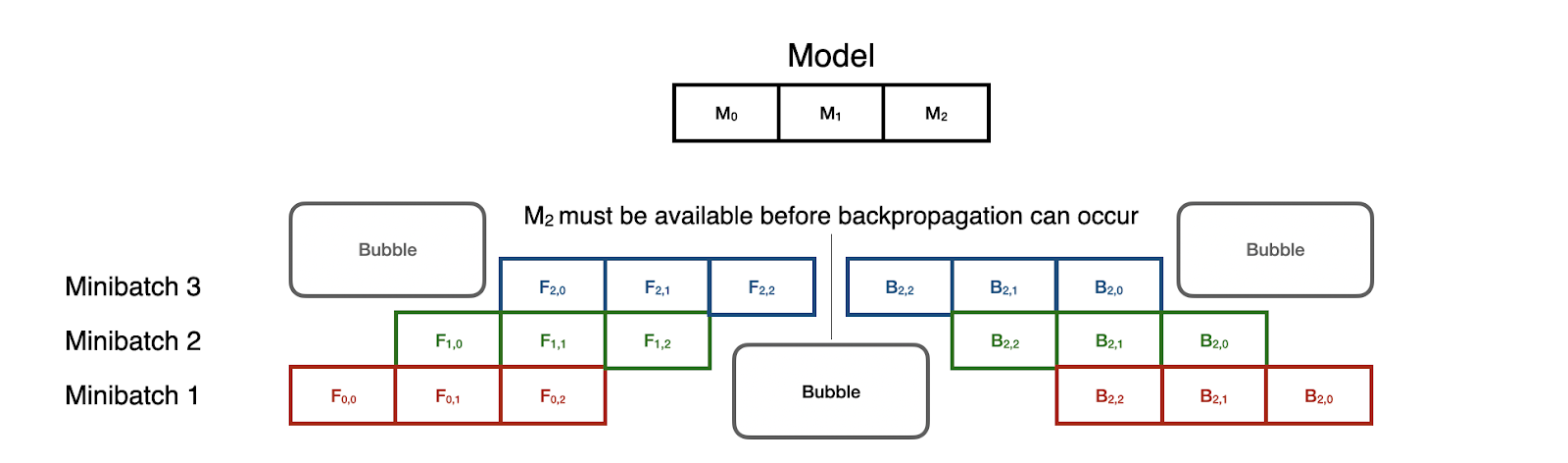
Note, however, that stages are reused in reverse order for backpropagation. This means that backprop can’t start until the forward pipeline is fully clear. Nevertheless, this technique can speed up model parallel training to a great degree - as much as 5X with 8 GPUs!
Hydra takes an alternate approach, detaching scalability and parallelism into two different steps. A common concept in database management systems is “spilling”, where excess data is sent to a lower level of the memory hierarchy. Hydra exploits sequential compute in model parallelism, and makes the observation that inactive model partitions do not need to be on a GPU! Instead, it spills unneeded data down to DRAM, swapping model partitions on and off of the GPU in order to simulate traditional model parallel execution.
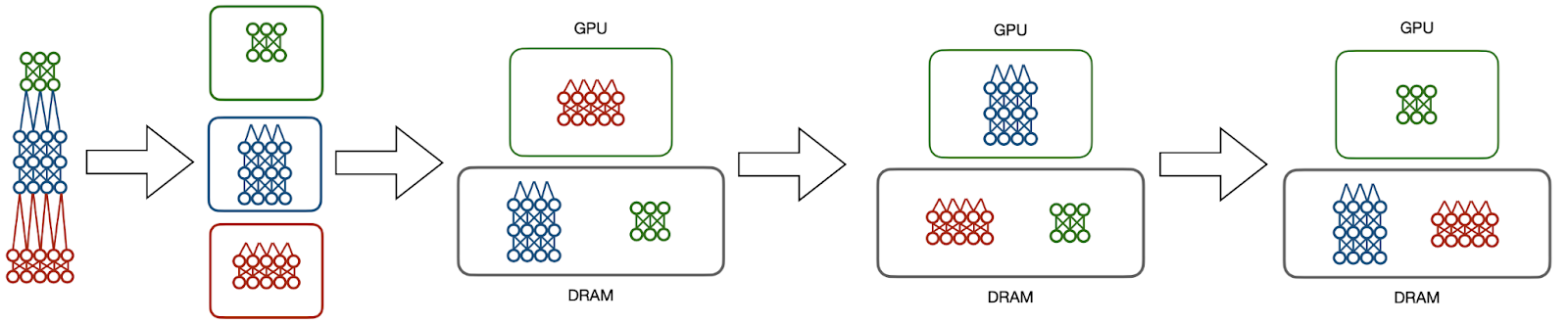
This enables us to train models only using one GPU at a time. Introducing a degree of task parallelism on top, then, is trivial. Each model, regardless of its size, only needs one GPU at a time, so the system can fully utilize every GPU simultaneously. The result is near-optimal speedups of >7.4X with 8 GPUs.
But model parallelism is only the beginning of what systems research has to offer to model training. Other promising contributions include data parallelism (eg PyTorch DDP), model selection (eg Cerebro or Model Selection Management Systems), distributed execution frameworks (Spark or Ray), and many more - model training is an area ripe for optimizations with systems research.
Model Serving
At the end of the day, we build machine learning models to be used. Model serving and prediction is one of the most critical aspects of machine learning practice, and it’s one of the spaces where systems research has had the biggest impact.
Prediction can be split into two primary settings: offline deployment and online deployment. Offline deployment is relatively straightforward - it involves a single large batch job of predictions run at irregular intervals. Common settings include business intelligence, insurance evaluations, and healthcare analytics. Online deployment belongs in web applications where rapid, low-latency predictions are needed for users who need fast responses to their queries.
Both settings have their own needs and demands. Generally, offline deployment requires high throughput training procedures to get through many samples quickly. Online deployment, on the other hand, will generally need extremely fast turnaround times on a single prediction, rather than many at once.
Systems research has reshaped how we approach both tasks. Consider Krypton, a tool that reimagines video analytics as a “multi-query optimization” (MQO) task.
MQO is not a new area - it’s been part of relational database design for decades. The general idea is simple: different queries may share related components, which can then be saved and reused. Krypton makes the observation that CNN inference is often done on batches of related images, such as in video analytics.
Typically, videos are produced at high frame rates, such that consecutive frames tend to be relatively similar. Most of the information in frame 1 is still present in frame 2. There’s a clear parallel to MQO here - we have a series of tasks with shared information between them.
Krypton runs a regular inference pass on the first frame, and then materializes, or saves, intermediate data that the CNN produced while predicting. Subsequent images are compared to the first frame to determine what patches of the image have changed sufficiently to be worth recomputing. Once the patch is identified, Krypton computes the “change field” of the patch through the CNN to determine what neuron outputs have changed throughout the model’s entire state. These neurons are rerun with the changed data. The rest of the data is simply reused from the base frame!
The result is end-to-end speedups of more than >4X speedups on inferencing workloads with only minor accuracy loss from data staleness. This sort of runtime improvement can be critical to long-running streaming applications such as video analytics on security footage.
Krypton is not alone in its focus on model inference. Other works such as Clipper and TensorFlow Extended address the same problem of efficient prediction serving by leveraging systems optimizations and model management techniques to offer efficient and robust predictions.
Conclusion
Machine learning has revolutionized the way we use and interact with data. It’s improved efficiency in businesses, fundamentally changed the advertising landscape, and overhauled healthcare technologies. But for machine learning to continue to grow its impact and reach, the development pipeline has to improve. Systems research is filling this need, by bringing decades of work in database systems, distributed computing, and application deployment to the machine learning space. Machine learning is novel and exciting - but many of its problems are not. By identifying the parallels and “twisting” old solutions, we can use systems to redesign ML.
Author Bio
Kabir Nagrecha is a PhD student at the University of California San Diego, advised by Arun Kumar. He previously received his B.Sc. from UC San Diego at the age of 17, and is currently interning in Apple's Siri group. His research focuses on enabling scalability in deep learning by use of systems techniques. You can find an updated list of his publications at kabirnagrecha.com and follow @KabirNagrecha on Twitter.
Citation
For attribution in academic contexts or books, please cite this work as
Kabir Nagrecha, "Systems for Machine Learning", The Gradient, 2021.
BibTeX citation:
@article{nagrecha2021systems,
author = {Nagrecha, Kabir},
title = {Systems for Machine Learning},
journal = {The Gradient},
year = {2021},
howpublished = {\url{https://thegradient.pub/systems-for-machine-learning/} },
}



{kind=link}
{kind=link}
{kind=link}
{kind=link}