History of Deep Learning
We are witnessing the third rise of deep learning. The first two waves — 1950s–1960s and 1980s–1990s — generated considerable excitement but slowly ran out of steam, since these neural networks neither achieved their promised performance gains nor aided our understanding of biological vision systems. The third wave — 2000s–present — is different because deep learning has blown past its competition on a plethora of benchmarks and real world applications. While most of the basic ideas of deep learning were already developed during the second wave, their power could not be unleashed until large datasets and powerful computers (GPUs) became available.
The rise and fall of deep learning reflects changes in intellectual fashion and popularity of learning algorithms. The second wave saw the limitations of classical AI in the form of underwhelming performances on overwhelming promises. Thus began the AI winter of the mid-1980s. The decline of the second wave transitioned to the rise of support vector machines, kernel methods, and related approaches. We applaud the neural network researchers who carried on despite discouragement, but note that the pendulum has swung once again. Now it is difficult to publish anything that is not neural network related. This is not a good development. We suspect that the field would progress faster if researchers pursued a diversity of approaches and techniques instead of chasing the current vogue. It is doubly worrying that student courses in AI often completely ignore the older techniques in favor of the current trends.
Successes and Failures
The computer vision community was fairly skeptical about deep learning until AlexNet [1] demolished all its competitors on Imagenet [2] in 2011. In the coming years, vision researchers would propose a variety of neural network architectures with increasingly better performance on object classification, e.g., [3] [4] [5].
Deep Learning was also rapidly adapted to other visual tasks such as object detection, where the image contains one or more objects and the background is much larger. For this task, neural networks were augmented by an initial stage which made proposals for possible positions and sizes of the objects. These methods outperformed the previous best methods, the Deformable Part Models [6], for the PASCAL object detection challenge [7], which was the main object detection and classification challenge before ImageNet. Other Deep Net architectures also gave enormous performance jumps in other classic tasks, many of which are illustrated in Figure 1.

But despite deep learning outperforming alternative techniques, they are not general purpose. Here, we identify three main limitations.
Firstly, deep learning nearly always requires a large amount of annotated data. This biases vision researchers to work on tasks where annotation is easy instead of tasks that are important.
There are methods which reduce the need for supervision, including transfer learning [8] [9] [10], few-shot learning [11] [12] [13], unsupervised learning [14] [15], and weakly supervised learning [16]. But so far they achievements have not been as impressive as for supervised learning.
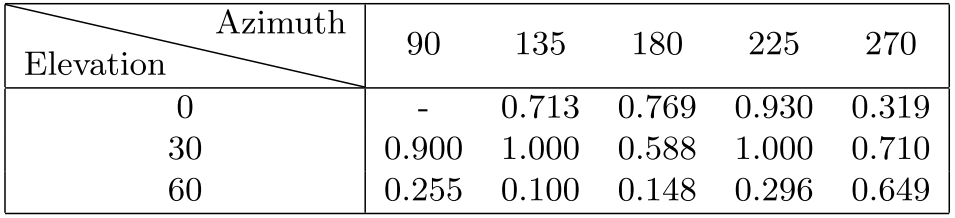
Secondly, Deep Nets perform well on benchmarked datasets, but can fail badly on real world images outside the dataset. All datasets have biases. These biases were particularly blatant in the early vision datasets and researchers rapidly learned to exploit them for example by exploiting the background context (e.g., detecting fish in Caltech101 was easy because they were the only objects whose backgrounds were water). These problems are reduced, but still remain, despite the use of big datasets and Deep Nets. For example, as shown in Figure 2, a Deep Net trained to detect sofas on ImageNet can fail to detect them if shown from viewpoints which were underrepresented in the training dataset. In particular, Deep Nets are biased against "rare events" which occur infrequently in the datasets. But in real world applications, these biases are particularly problematic since they may correspond to situations where failures of a vision system can lead to terrible consequences. Datasets used to train autonomous vehicles almost never contain babies sitting in the road.

Thirdly, Deep Nets are overly sensitive to changes in the image which would not fool a human observer. Deep Nets are not only sensitive to standard adversarial attacks which cause imperceptible changes to the image [17] [18] but are also over-sensitive to changes in context. Figure 3 shows the effect of photoshopping a guitar into a picture of a monkey in the jungle. This causes the Deep Net to misidentify the monkey as a human and also misinterpret the guitar as a bird, presumably because monkeys are less likely than humans to carry a guitar and birds are more likely than guitars to be in a jungle near a monkey [19]. Recent work gives many examples of the over-sensitivity of Deep Nets to context, such as putting an elephant in a room [20].
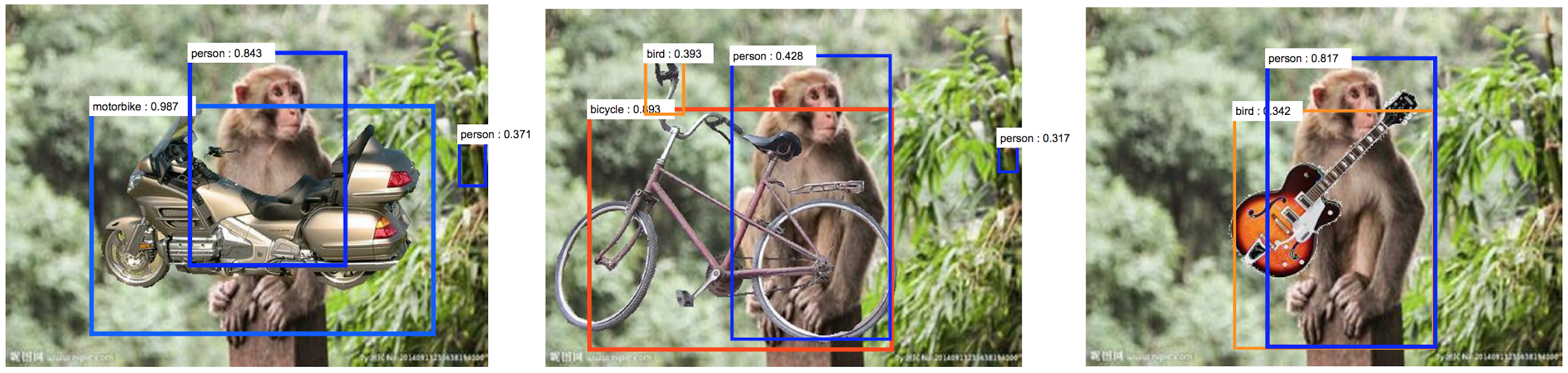
This over-sensitivity to context can also be traced back to the limited size of datasets. For any object only a limited number of contexts will occur in the dataset and so the neural network will be biased towards them. For example, in early image captioning datasets it was observed that giraffes only occurred nearby trees and so the generated captions failed to mention giraffes in images without trees even if they were the most dominant object.
The difficulty of capturing the enormous varieties of context, as well as the need to explore the large range of nuisance factors, is highly problematic for data driven methods like Deep Nets. It seems that ensuring that the networks can deal with all these issues will require datasets that are arbitrarily big, which raises enormous challenges for both training and testing datasets. We will discuss these issues next.
When Big Datasets Are Not Big Enough
The Combinatorial Explosion
None of the problems identified above are necessarily deal-breakers for deep learning, but we argue that these are early warning signs of a problem. Namely, that the set of real world images is combinatorially large, and so it is hard for any dataset, no matter how big, to be representative of the complexity of the real world.
What does it mean for a set to be combinatorially large? Imagine constructing a visual scene by selecting objects from an object dictionary and placing them in different configurations. This can clearly be done in an exponential number of ways. We can obtain similar complexity even for images of a single object since it can be partially occluded in an exponential number of ways. We can also change the context of an object in an infinite number of ways.
Although humans naturally adapt to changes in visual context, Deep Nets are much more sensitive and error-prone, as illustrated in Figure 3. We note that this combinatorial explosion may not happen for some visual tasks and Deep Nets are likely to be extremely successful for medical image application because there is comparatively little variability in context (e.g., the pancreas is always very close to the duodenum). But for many real world applications, the complexity of the real world cannot be captured without having an exponentially large dataset.
This causes big challenges, as the standard paradigm of training and testing models on a finite number of randomly drawn samples becomes impractical, as they will never be large enough to be representative of the underlying distribution of the data. This forces us to address two new problems:
(I) How can we train algorithms on finite sized datasets so that they can perform well on the truly enormous datasets required to capture the combinatorial complexity of the real world?
(II) How can we efficiently test these algorithms to ensure that they work in these enormous datasets if we can only test them on a finite subset?
Overcoming Combinatorics
It seems highly unlikely that methods like Deep Nets, in their current forms, can deal with the combinatorial explosion. The datasets may never be large enough to either train or test them. We sketch some potential solutions below.
Compositionality
Compositionality is a general principle which can be described poetically as "an embodiment of faith that the world is knowable, that one can tease things apart, comprehend them, and mentally recompose them at will". The key assumption is that structures are composed hierarchically from more elementary substructures following a set of grammatical rules. This suggests that the substructures and the grammars can be learned from finite amounts of data but will generalize to combinatorial situations.
Unlike deep nets, compositional models require structured representations which make explicit their structures and substructures. Compositional models offer the ability to extrapolate beyond data they have seen, to reason about the system, intervene, do diagnostics, and to answer many different questions based on the same underlying knowledge structure. To quote Stuart Geman: "the world is compositional or God exists," since otherwise it would seem necessary for God to handwire human intelligence [21]. We note that although Deep Nets capture a form of compositionality, e.g., high level features are composed from the responses from lower level features, they are not compositional in the sense that we mean in this article.
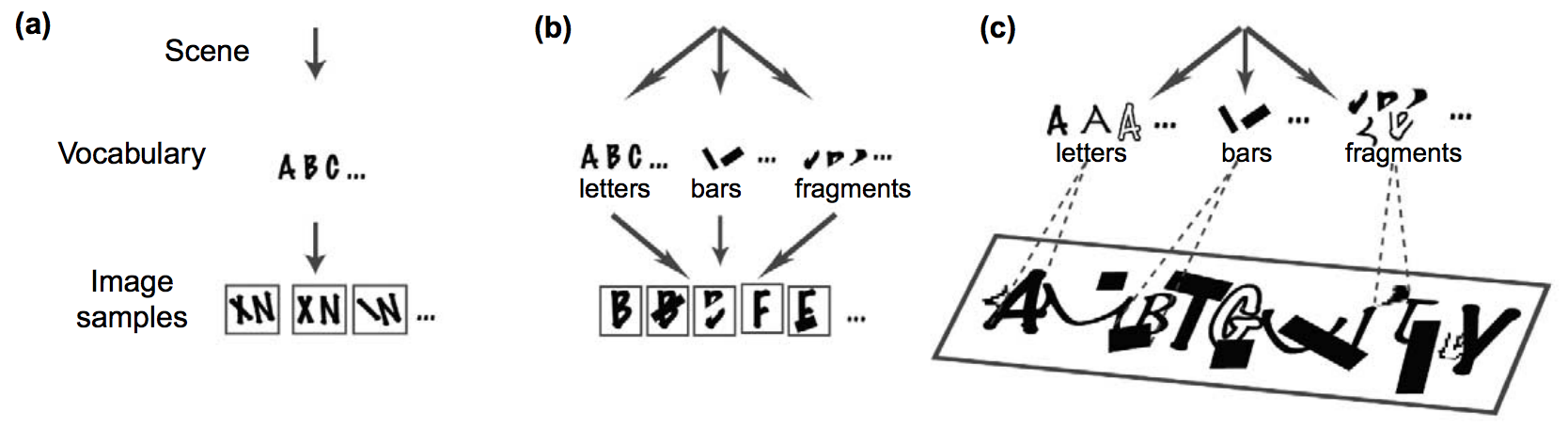
Figure 4 illustrates an example of compositionality [22], which relates to analysis by synthesis [23].
Several of these conceptual strengths of compositional models have been demonstrated on visual problems such as the ability to perform several tasks with the same underlying model [24] and to recognize CAPTCHAs [25]. Other non-visual examples illustrate the same points. Attempts to train Deep Nets to do IQ tests were not successful. [26] In this task the goal is to predict the missing image in a 3x3 grid, where the other 8 images are given, and where the underlying rules are compositional (and distractors can be present). Conversely, for some natural language applications Neural Module Networks [27], whose dynamic architecture seems flexible enough to capture some meaningful compositions, outperform traditional deep learning networks. In fact, we recently verified that the individual modules indeed performed their intended compositional functionalities (e.g. AND, OR, FILTER(RED) etc) after joint training [28].
Compositional models have many desirable theoretical properties, such as being interpretable, and being able to generate samples. This makes errors easier to diagnose, and hence they are harder to fool than black box methods like Deep Nets. But learning compositional models is hard because it requires learning the building blocks and the grammars (and even the nature of the grammars is debatable). Also, in order to perform analysis by synthesis they need to have generative models of objects and scene structures. Putting distributions on images is challenging with a few exceptions like faces, letters, and regular textures [29].
More fundamentally, dealing with the combinatorial explosion requires learning causal models of the 3D world and how these generate images. Studies of human infants suggest that they learn by making causal models that predict the structure of their environment including naive physics. This causal understanding enables learning from limited amounts of data and performing true generalization to novel situations. This is analogous to contrasting Newton's Laws, which gave causal understanding with a minimal amount of free parameters, with the Ptolemaic model of the solar system, which gave very accurate predictions but required a large amount of data to determines its details (i.e. the epicycles).
Testing on Combinatorial Data
One potential challenge with testing vision algorithms on the combinatorial complexity of the real world is that we can only test on finite data. Game theory deals with this by focusing on the worst cases instead of the average cases. As we argued earlier, average case results on finite sized datasets may not be meaningful if the dataset does not capture the combinatorial complexity of the problem. Clearly paying attention to the worst cases also makes sense if the goal is to develop visual algorithms for self-driving cars, or diagnosing cancer in medical images, where failures of the algorithms can have severe consequences.
If the failure modes can be captured in a low-dimensional space, such as the hazard factors for stereo, then we can study them using computer graphics and grid search [30]. But for most visual tasks, particularly those involving combinatorial data, it will be very hard to identify a small number of hazard factors which can be isolated and tested. One strategy is to extend the notion of standard adversarial attacks to include non-local structure, by allowing complex operations which cause changes to the image or scene, e.g., by occlusion, or changing the physical properties of the objects being viewed [31], but without significantly impacting human perception. Extending this strategy to vision algorithms which deal with combinatorial data remains very challenging. But, if algorithms are designed with compositionality in mind,their explicit structures may make it possible to diagnose them and determine their failure modes.
Conclusion
A few years ago Aude Oliva and Alan Yuille (the first author) co-organized a NSF-sponsored workshop on the Frontiers of Computer Vision (MIT CSAIL 2011). The meeting encouraged frank exchanges of opinion and in particular, there was enormous disagreement about the potential of Deep Nets for computer vision. Yann LeCun boldly predicted that everyone would soon use Deep Nets. He was right. Their successes have been extraordinary and have helped vision become quite popular, dramatically increased the interaction between academia and industry, led to applications of vision techniques to a large range of disciplines, and have many other important consequences. But despite their successes there remain enormous challenges which must be overcome before we reach the goal of general purpose artificial intelligence and understanding of biological vision systems. Several of our concerns parallel those mentioned in recent critiques of Deep Nets [32] [33]. Arguably the most serious challenge is how to develop algorithms that can deal with the combinatorial explosion as researchers address increasingly complex visual tasks in increasingly realistic conditions. Although Deep Nets will surely be one part of the solution, we believe that we will also need complementary approaches involving compositional principles and causal models that capture the underlying structures of the data. Moreover, faced with the combinatorial explosion, we will need to rethink how we train and evaluate vision algorithms.
Note: this is a shorter version of our original paper "Deep Nets: What have they ever done for Vision?".[34]
Citation
For attribution in academic contexts or books, please cite this work as
Alan L. Yuille & Chenxi Liu, "Limitations of Deep Learning for Vision, and How We Might Fix Them", The Gradient, 2019.
BibTeX citation:
@article{YuilleLiuGradient2019DeepLearningVision,
author = {Yuille, Liu}
title = {Limitations of Deep Learning for Vision, and How We Might Fix Them},
journal = {The Gradient},
year = {2019},
howpublished = {\url{https://thegradient.pub/the-limitations-of-visual-deep-learning-and-how-we-might-fix-them } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems. 2012. ↩︎
Deng, Jia, et al. "Imagenet: A large-scale hierarchical image database." Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. Ieee, 2009. ↩︎
Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014). ↩︎
He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. ↩︎
Liu, Chenxi, et al. "Progressive neural architecture search." Proceedings of the European Conference on Computer Vision (ECCV). 2018. ↩︎
Felzenszwalb, Pedro F., et al. "Object detection with discriminatively trained part-based models." IEEE transactions on pattern analysis and machine intelligence 32.9 (2010): 1627-1645. ↩︎
Everingham, Mark, et al. "The pascal visual object classes (voc) challenge." International journal of computer vision 88.2 (2010): 303-338. ↩︎
Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. ↩︎
Long, Jonathan, Evan Shelhamer, and Trevor Darrell. "Fully convolutional networks for semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. ↩︎
Chen, Liang-Chieh, et al. "Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs." IEEE transactions on pattern analysis and machine intelligence 40.4 (2017): 834-848. ↩︎
Mao, Junhua, et al. "Learning like a child: Fast novel visual concept learning from sentence descriptions of images." Proceedings of the IEEE International Conference on Computer Vision. 2015. ↩︎
Vinyals, Oriol, et al. "Matching networks for one shot learning." Advances in neural information processing systems. 2016. ↩︎
Qiao, Siyuan, et al. "Few-shot image recognition by predicting parameters from activations." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018. ↩︎
Doersch, Carl, Abhinav Gupta, and Alexei A. Efros. "Unsupervised visual representation learning by context prediction." Proceedings of the IEEE International Conference on Computer Vision. 2015. ↩︎
Wang, Xiaolong, and Abhinav Gupta. "Unsupervised learning of visual representations using videos." Proceedings of the IEEE International Conference on Computer Vision. 2015. ↩︎
Papandreou, George, et al. "Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation." Proceedings of the IEEE international conference on computer vision. 2015. ↩︎
Szegedy, Christian, et al. "Intriguing properties of neural networks." arXiv preprint arXiv:1312.6199 (2013). ↩︎
Xie, Cihang, et al. “Adversarial examples for semantic segmentation and object detection.” Proceedings of the IEEE International Conference on Computer Vision. 2017. ↩︎
Wang, Jianyu, et al. "Visual concepts and compositional voting." Annals of Mathematical Sciences and Applications 3.1 (2018): 151-188. ↩︎
Rosenfeld, Amir, Richard Zemel, and John K. Tsotsos. "The elephant in the room." arXiv preprint arXiv:1808.03305 (2018). ↩︎
Geman, Stuart. "Compositionality in vision." The grammar of vision: probabilistic grammar-based models for visual scene understanding and object categorization. 2007. ↩︎
Bienenstock, Elie, Stuart Geman, and Daniel Potter. “Compositionality, MDL priors, and object recognition.” Advances in neural information processing systems. 1997. ↩︎
Zhu, Song-Chun, and David Mumford. “A stochastic grammar of images.” Foundations and Trends® in Computer Graphics and Vision 2.4 (2007): 259-362. ↩︎
Zhu, Long, et al. "Part and appearance sharing: Recursive Compositional Models for multi-view." Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010. ↩︎
George, Dileep, et al. "A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs." Science 358.6368 (2017): eaag2612. ↩︎
Barrett, David, et al. "Measuring abstract reasoning in neural networks." International Conference on Machine Learning. 2018. ↩︎
Andreas, Jacob, et al. "Neural module networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016. ↩︎
Liu, Runtao, et al. "CLEVR-Ref+: Diagnosing Visual Reasoning with Referring Expressions." arXiv preprint arXiv:1901.00850 (2019). ↩︎
Tu, Zhuowen, et al. "Image parsing: Unifying segmentation, detection, and recognition." International Journal of computer vision 63.2 (2005): 113-140. ↩︎
Zhang, Yi, et al. "UnrealStereo: Controlling Hazardous Factors to Analyze Stereo Vision." 2018 International Conference on 3D Vision (3DV). IEEE, 2018. ↩︎
Zeng, Xiaohui, et al. "Adversarial attacks beyond the image space." arXiv preprint arXiv:1711.07183 (2017). ↩︎
Darwiche, Adnan. "Human-Level Intelligence or Animal-Like Abilities?." arXiv preprint arXiv:1707.04327 (2017). ↩︎
Marcus, Gary. "Deep learning: A critical appraisal." arXiv preprint arXiv:1801.00631 (2018). ↩︎
Yuille, Alan, et al. "Deep Nets: What have they ever done for Vision?" arXiv preprint arXiv:1805.04025 (2018). ↩︎



{kind=link}
{kind=link}
{kind=link}
{kind=link}