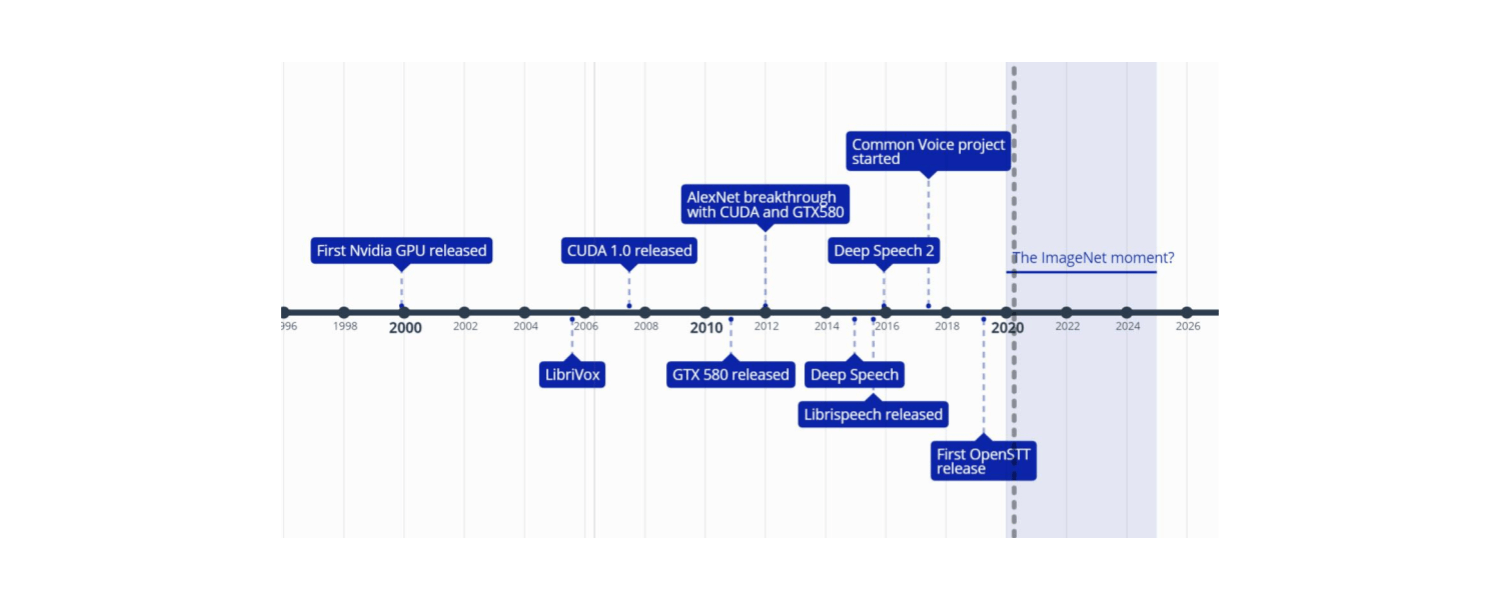
This is a follow-up article to our article on building speech-to-text (STT) models, Towards an ImageNet Moment for Speech-to-Text. In the first article we mostly focused on the practical aspects of building STT models. In this article we would like to answer the following questions:
- What is the so-called ImageNet moment and why does it matter?
- Why has it not arrived yet in speech, and how did academia and industry indirectly contribute to it not having arrived yet?
- What are the deficiencies of the approach we presented in the previous article?
Table of Contents
What is the ImageNet Moment?
As discussed in our last piece Towards an ImageNet Moment for Speech-to-Text, in our opinion, the ImageNet moment in a given Machine Learning (ML) sub-field arrives when:
- The architectures and model building blocks required to solve 95% of standard "useful" tasks are widely available as standard and tested open-source framework modules;
- Most popular models are available with pre-trained weights from large datasets that enable fine-tuning on downstream tasks with relatively little data;
- This sort of fine-tuning from standard tasks using pre-trained models to different everyday tasks is solved (i.e. tends to work well);
- The compute required to train models for everyday tasks is minimal (e.g. 1-10 GPU days in STT) compared to the compute requirements previously reported in papers (100-1000 GPU days in STT);
- The compute for pre-training large models is available to small independent companies and research groups;
If the above conditions are satisfied, one can develop new useful applications with reasonable costs. Also democratization occurs - one no
longer has to rely on giant companies such as Google as the only source
of truth in the industry.
Why There is No ImageNet Moment Yet
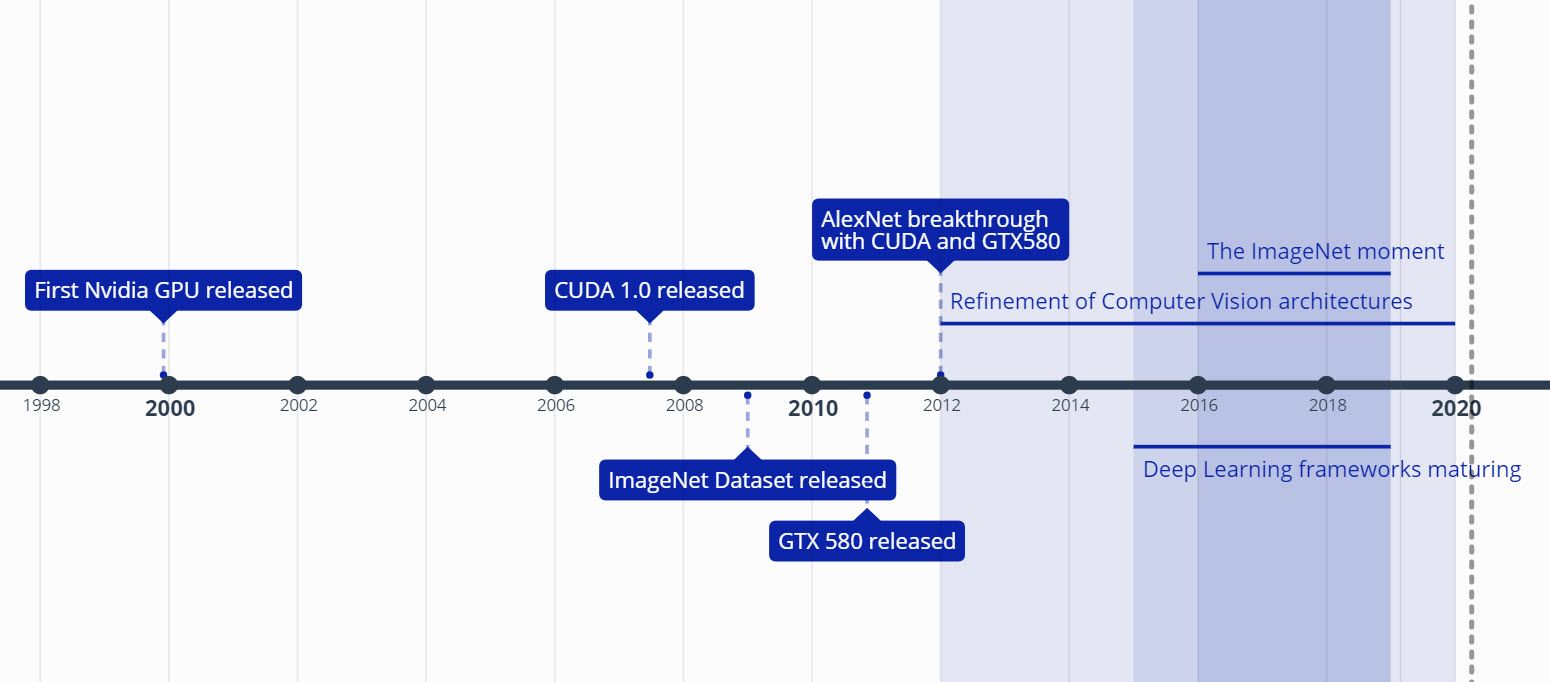
To understand this, let us try to understand which events and trends led
its arrival in computer vision (CV).
The short story is:
- NVIDIA has been making and optimizing consumer GPUs for decades. It is a widely accepted fact that now you can build a “super-computer” by simply putting 4-8 top line GPUs together;
- It is rumored that in late 2000s NVIDIA envisaged that the GPU performance would be enough for ML and around that time they started investing in CUDA (its first release happening in 2007) - a low level matrix multiplication framework that lies at the basis of the majority of GPU-accelerate ML applications;
- In 2009 a team led by Professor Fei-Fei Li released the ImageNet dataset, and then a competition now known as the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) was started in 2011. In 2012 Alex Krizhevsky et al. used NVIDIA GPUs and CUDA to train the now famous AlexNet neural net to achieve performance far beyond what has been achieved before.
- Deep Learning frameworks have been developing since, reaching their maturity around 2017-2018. At the moment of publication of this piece PyTorch and TensorFlow are the go-to solutions, which also boast a plethora of pre-trained models for many tasks besides image classification;
- Over the same period, the model architecture for achieving SOTA performance on ImageNet kept being refined, and as that happened the code for training and evaluating these models was also released along with the pretrained weights in these same popular frameworks.
So, by 2018 or so the ‘ImageNet Moment’ had fully happened for the vision community:
“It has become increasingly common within the CV community to treat image classification on ImageNet [35] not as an end in itself, but rather as a “pre-text task” for training deep convolutional neural networks (CNNs [25, 22]) to learn good general-purpose features. This practice of first training a CNN to perform image classification on ImageNet (i.e. pre-training) and then adapting these features for a new target task (i.e. fine-tuning) has become the de facto standard for solving a wide range of CV problems. Using ImageNet pre-trained CNN features, impressive results have been obtained on several image classification datasets [10, 33], as well as object detection [12, 37], action recognition [38], human pose estimation [6], image segmentation [7], optical flow [42], image captioning [9, 19] and others [2].”
To simplify the argument, we assume that STT shares the hardware acceleration options, the frameworks and some work on neural network architectures with CV. On the other hand, pre-trained models, transfer learning and datasets are lagging behind for STT compared with CV. Also the compute requirements (as stated in research papers) are still too high.
Let us understand why this is the case in more detail. The majority of research in speech is published by academics sponsored by the industry / corporations. So we will address our criticism to the academic and the industry part of their research. To be fair, we will criticize our solution as well; we welcome feedback and criticism here - [email protected].
Сriticisms of the Industry
In general, the majority of STT papers we have read were written by researchers from the industry (e.g. Google, Baidu, and Facebook). Most criticisms of STT papers and solutions can be attributed to either the"academic" part or the "industry" part of the researchers’ background.
To keep it short, these are our key concerns with the "industry" part of STT:
- Building solutions based on private data and not reporting it clearly;
- Complicated Frameworks And Toolkits;
- Solving non-existing problems;
- Obfuscated results in the papers.
Building Solutions Based on Private Data and Not Reporting it Properly
The famous Deep Speech 2 paper (2015) has this chart:
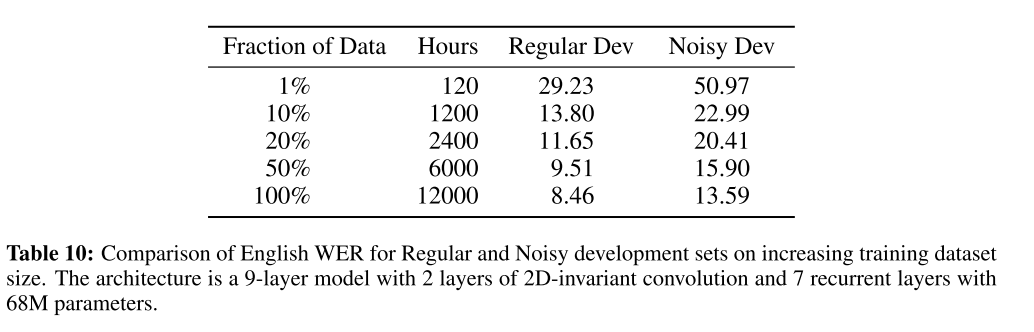
Basically, it says that to have a good quality model a lot of data is required. It is one of a few papers that explicitly reports this and performs out-of-dataset validation. The majority of modern STT papers usually just heavily overfit on the LibriSpeech ASR corpus (LibriSpeech) with increasingly more extravagant methods.
It is likely that Google, Facebook, and Baidu have private 10,000 - 100,000 hour datasets at their disposal that they use to train their models. This is fine, but what is not fine is when they use that data in order to increase their performance without reporting it. This issue is further compounded by the fact that annotating speech takes a long time, so smaller players in the field can’t build their own datasets due to exorbitant costs. Even if they used methods of obtaining annotations similar to ours, it takes a lot of resources, time, and effort to produce labels and verify them on a large scale.
Annotation of 1 hour of speech may take from 2 to 10 hours depending on how challenging the dataset is and whether some form of automated labels are at hand (i.e. in the form of other STT system output). Unlike in CV, where useful datasets can be annotated with a fraction of such effort, annotation in speech is expensive. This leads to the current situation - everyone is claiming top results on a revered public dataset (LibriSpeech), but has zero or little motivation to report how these models perform in real life and which models trained on what are in production. There is no clear economic incentive for Google, Facebook, or Baidu to open-source their large proprietary datasets. All in all, this erects a very challenging barrier to entry for practitioners willing to build their own STT systems. Projects like the Common Voice make things easier, but they do not have nearly enough data yet.
Complicated Frameworks And Toolkits
| Toolkit | Commits | Contributors | Language | Comment |
|---|---|---|---|---|
| Wav2Letter++ | 256 | 21 | C++ | Commits here might be more similar to releases |
| FairSeq | 956 | 111 | PyTorch | |
| OpenNMT | 2,401 | 138 | PyTorch | |
| EspNet | 5,441 | 51 | PyTorch | |
| Typical Project | 100-500 | 1 - 10 | PyTorch |
It is common in to rely on frameworks or toolkits instead of writing everything from scratch. One would expect that if there are dedicated frameworks and toolkits for STT, then it would be better to build upon the models provided by those frameworks than tobuild your own models on bare PyTorch or TensorFlow. Unfortunately this is not the case in speech. It is unreasonable to use these solutions to kickstart your STT project for a number of reasons:
- The code is optimized to run on large compute;
- The recipes (end-to-end examples showing how to use these frameworks) exist only for small academic datasets and fail to scale to large data without huge compute;
- The recipes are highly sample-inefficient (our favorite example is training 10GB LMs on datasets with a hundred of megabytes worth of text);
- Even if you pre-train a model on LibriSpeech, it most likely will not transfer to the real world;
- If you want to build an internal STT solution, internalize it, properly understand it, and optimize it - you would probably need either a large team or a significant amount of time to internalize said toolkits;
- Said toolkits are either published internal solutions or are meant as a PR, first-to-market, or ecosystem building tools. That means that most likely the toolkits will serve as a proper MVP or baseline, but you will not be able to optimize such pipelines easily without investing a lot of resources (and if you are a corporation the chances are that will write your own toolkit anyway);
On a more personal note, we tried several times to internalize some of FairSeq and EspNet pipelines, but we could not do it in a reasonable amount of time and effort. Maybe our ML engineering skills leave much to be desired, but we heard similar opinions from people with much better engineering skills (i.e. full-time C++ ML coders).
Solving Non-Existing Problems
Building a new or better toolkit for LibriSpeech that works on 8 US $10k GPUs does not help with real world applications.
Creating and publishing free, open, and public domain datasets on real life data and then publishing models pre-trained on them is the solution (this is what happened in CV). However, we have yet to see a worthy initiative except for the Common Voice project by Mozilla.
Irreproducible Results
There is a common pattern in ML, where every week there is someone claiming a state-of-the-art result, but rarely are such results reproducible or accompanied by code that could be easily run.
Reproducibility is only harder to achieve when considering the difficulties of integrating with accelerated hardware and large datasets, as well as the time involved training the models.
Contrary to the "state-of-the-art" mantra, we believe that more attention should be paid to "good enough to be used in real life"solutions and public datasets.
Criticisms of Academia
Here is a brief summary of our ideas:
- If a large group of people focuses on pursuing a top result of some metric, this metric loses its meaning (see Goodhart's Law). If not updated quickly enough, academic datasets effectively become “leaderboards” that corporations use to show-off their power. To achieve state of the art, using huge and sample-inefficient networks on large compute becomes the default despite it not being accessible to smaller players;
- Ideally papers should be detailed enough so that an independent researcher could achieve at least 95% of what the paper achieved.
- In reality papers' contents and structure are often questionable in terms of their actual purpose and real life application, i.e. they are published with publish or perish mentality and complicated mathematics is used as a means to explain new concepts, despite the fact that the researchers themselves may have nothing to do with said mathematics and just used off-the-shelf instruments
- Aside from reproducibility, papers have several other common flaws:
- They are vague on the generalization of their approach, i.e. out-of-domain testing. If you just read papers it seems like neural networks beat humans in ASR, but that is just another symptom of the “leaderboard” problem - it’s not true;
- They often do not state how much compute they use.
- They hardly ever publish convergence curves, i.e. how much time and compute is required to achieve some fraction of the state-of-the-art result. Usually in ML 95% or even 99% of the result can be achieved with a small fraction of the total compute.
Bitten by the SOTA Bug
I really like the expression "being bitten by the SOTA bug". In a nut shell it means that if a large group of people focuses on pursuing a top result on some abstract metric, this metric loses its meaning (a classic manifestation of Goodhart's Law). The exact reason why this happens is usually different each time and it may be very technical, but in ML what is usually occurring is that the models are overfit to some hidden intrinsic qualities of the dataset that are used to calculate the metrics. For example, in CV such patterns are usually clusters of visually similar images.
A small idealistic under-the-radar community pursuing an academic or scientific goal is much less prone to falling victim to Goodhart's law than a larger and more popular community. Once a certain degree of popularity is reached, the community starts pursuing metrics or virtue signalling (showing off one’s moral values for the sake of showing off when no real effort is required) and the real progress stops until some crisis arrives. This is what it means to be bitten by the SOTA bug.
For example, in the field of Natural Language Processing this attitude has lead to irrational over-investment into huge models optimized on public academic benchmarks, but the usefulness of such “progress” is very limited for a number of reasons:
- Even the best state-of-the-art models have very limited understanding of the task at hand (ML is pattern matching after all);
- The recent state-of-the-art results are increasingly more difficult to compare because their compute usage may differ by orders of magnitude;
- Difficult reproducibility limits real world usage;
- More data & compute = SOTA is not research news;
- Leaderboard metrics are overrated.
A recent explosion in the number of academic NLP datasets is inspiring,
but usually their real applicability is limited by a number of factors:
- The majority of such datasets are in English;
- Such datasets are great in terms of researching what is possible, but unlike in CV it is hard to incorporate them in real pipelines;
- Though remarkable how much effort and attention goes into building datasets like SQUAD, you cannot really use them in production models;
- Stable production-grade NLP models usually are built upon data which is several orders of magnitude larger or the task at hand should be much more simple. For example - it is safe to assume that a neural network can do NER reliably, but as for answering questions or maintaining dialogue - this is just science fiction now. I like an apt analogy - building AGI with transformers is like going tothe Moon by building towers;
There is a competing point of view on ML validation and metrics (asopposed to “the higher the better” mantra) that we endorse that says that an ML pipeline should be treated as a compression algorithm, i.e. your pipeline compresses the real world into a set of compute graphs and models with memory, compute, and hardware requirements. If you manage to fit a roughly similarly performing model into a 10x smaller weight footprint or compute size then it is a much better achievement that getting an extra 0.5% on the leaderboard.
On the other hand, the good news is people in the industry are starting to think about the efficiency of their approaches and even Google is starting to publish papers on pre-training Transformers efficiently (on Google scale, of course).
Paper Contents and Structure

Traditionally, new ideas have been shared in ML in the form of mathematical formulas in papers. This practice is historic and understandable but flawed, because today with wider adoption of open-source tools there is a distinct line between building applied solutions, optimizing the existing solutions, explaining how things work (which is a separate hard job), building fundamental blocks or frameworks (like warp-ctc built by Baidu or PyTorch built by Facebook) and creating new mathematical approaches.
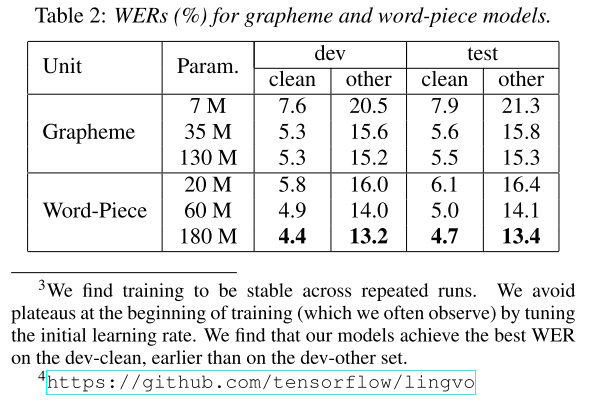
ML researchers generally agree that there is a lot of equations-for-equations' sake in papers. But do they really contribute to our understanding of how things really work? Let’s illustrate this point with the example of Connectionist Temporal Classification (CTC) loss. Almost each STT paper that uses this loss has a section dedicated to it. The chances are you will find some formulas here. But will it help you understand it?
CTC loss is a complex thing, and probably the largest enabler for STT research, but rarely papers mention which implementation they used. I have not yet seen the following ideas in any of the papers I read, so is it my ignorance, quirks of implementations that I used or are they purposely omitting this stuff?
- Each 3 months I compare warp-ctc (ported to PyTorch) with native CTC loss from PyTorch, and the latter just did not work properly for real data;
- CTC loss is quite “aggressive” compared to standard losses;
- Usually some form of clipping or warm-up is required, CTC loss “likes” to explode;
- You should be very careful with which data you show to you network during its first epoch;
Of course you can refer to the original paper (which is written by a mathematician) or to a stellar piece on Distill on CTC, which is much more accessible. But to be honest - the best accessible explanation I could find was an obscure YouTube video in Russian, where 2 guys just sit down and explain how it works with examples, step-by-step using some slides. So all this space in papers is used up by formulas, that while most likely being technically correct, bring nothing to the table? Actually doing a job done by people like 3Blue1Brown is extremely hard, but probably referencing proper accessible explanations is a solution?
Just imagine how much easier it would be to deliver results, if ML papers and publications would follow the following template:
- Used these toolkits, implementations, and ideas;
- Made these major changes;
- Run these experiments and here are our conclusions.
Sample Inefficient Overparameterized Networks Trained on "Small" Academic Datasets
Let's see how much progress has been made since the original paper that popularized ASR, Deep Speech 2.
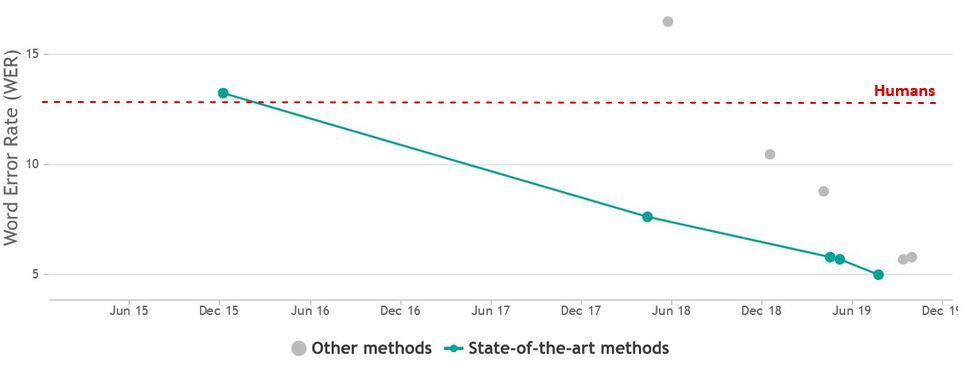
Does it seem that character error rate (CER) and word error rate (WER)metrics have actually decreased by 60% and overpassed the human level? So why can't we see ideal STT popping up in every second app on every device, if it works so well? Why are voice interfaces still considered just a cool feature, especially in business applications?
While we would agree with the below table that humans typically make
5-10% errors when transcribing audio, the table is misleading. We read
some of the papers below and noticed a few things:
- Newer papers rarely perform ablation tests with smaller models;
- ASR papers claiming state-of-the-art performance rarely post convergence curves;
- The papers rarely report the amount of compute used for hyper-param search and model convergence;
- Out of the papers we read, only Deep Speech 2 paid attention to how performance on a smaller dataset transfers to real-life data (i.e.
out-of domain validation); - Sample efficiency and scalability to real datasets is not optimized for. Several papers in 2019 did something like this (Time-Depth Separable Convolutions, QuartzNet) - but they focused on reducing the model size, not its training time;
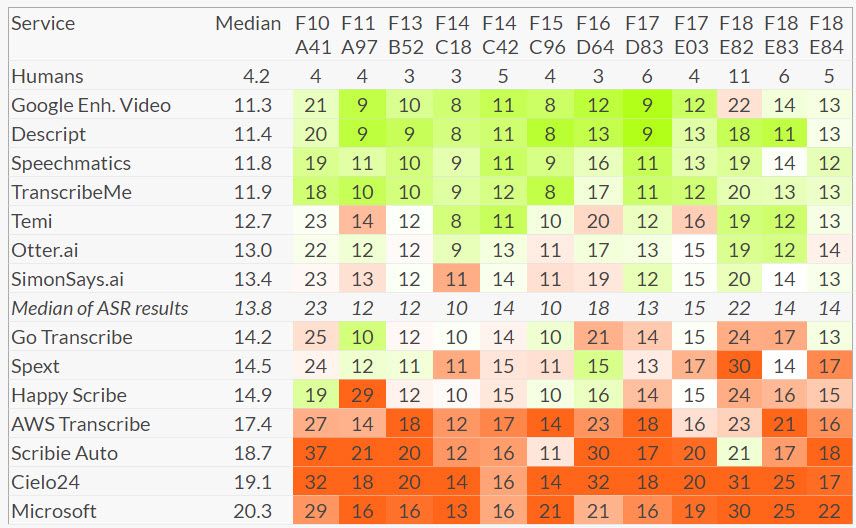
I understand that research follows cycles (make something new
inefficiently, optimize it, then achieve new grounds again), but it
seems that ASR research is a good example of Goodhart's law in practice.
- If you read the release notes of pre-trained Deep Speech in PyTorch and saw "Do not expect these models to perform well on your own data!", you may be amazed - it is trained on 1,000 hours of speech and has a very low CER and WER! In practice though, systems fitted on some ideal large 10,000 hour dataset will have WER upwards of 25-30% (instead of 5% on clean speech and 10% on noisy speech as advertised).
- Unlike CV research, where better Imagenet performance actually transfers to real tasks with much smaller datasets, in speech, better performance on LibriSpeech does not transfer to real world data! You cannot "just quickly tune" your network on 1,000 hours of speech like you would train your network on 1,000 images in CV;
- All of this means that the academic and corporate worlds have produced more and more elaborate methods of overfitting to LibriSpeech.
Although it is understandable researchers want to make progress on their problems and work with the data available, ultimately this shows that an ImageNet-like project for creating a truly large and very challenging dataset first would be far more useful.
Over Reliance on large Compute
The following table represents our analysis of the compute used in prominent or recent ASR papers:
| Year | Approach | Compute | Convergence | GPU hours | Dataset (hours) | Params | Full epochs |
|---|---|---|---|---|---|---|---|
| 2019 | Transformer-based... | 32 x P100 | 4 days | 3,072 | Librispeech (960) | ~94M | 100 |
| 2019 | QuartzNet | 8 x V100 | 5 days | 960 | Librispeech (960) | ~20M | 400 |
| 2019 | TDS | 8 x V100 | ? | ? | Librispeech (960) | ~37M | ? |
| 2019 | Our approach (smaller network) | 2 x 1080 Ti | 3 - 6 days | 144 - 288 | Open STT v0.5 (5000) | ~25-35M | 10-15 (0) |
| 2019 | Our approach (large network) | 4 x 1080 Ti | 3 - 6 days | 288 - 576 | Open STT v0.5 (5000) | ~50-60M | 10-15 (0) |
| 2019 | Jasper (10x5 model) | ? | ? | ? | Librispeech (960) | >200M | 50-400 |
| 2019 | Jasper (10x3 model) | ? | ? | ? | Librispeech (960) | ~200M | 50-400 |
| 2019 | SpecAugment | 32 TPUs | 7 days | ~ 5,000 - 10,000 | Librispeech (960) | ? | ? |
| 2019 | Choice of Modeling Unit... | 16 GPUs | 7 days | 2688 | Librispeech (960) | ~20 - 180M | 80 |
| 2018 | Wav2Letter | ? | ? | ? | Librispeech (960) | ~30M | ? |
| 2018 | Gated ConvNets | ? | ? | ? | Librispeech (960) | ~130M - 208M | 40 |
| 2015 | Deep Speech 2 | 8 - 16 GPUs | "a few days" | ? | incl. Librispeech (960) | ~35M | 400 |
Russian is a more difficult language than English as it has much more variation. Although our dataset cannot be directly compared to LibriSpeech because it contains many domains, LibriSpeech is more homogenous and less noisy.
Look at this table, we can observe the following:
- Most models trained on LibriSpeech do this in a cyclical fashion, i.e. show full dataset N times. This is very cost inefficient. Therefore we use a curriculum learning approach;
- QuartzNet. The paper focuses a lot on efficiency. But it seems that the amount of compute used for training is comparable with other papers;
- TDS. Though they do not report explicitly how much time is needed to train their networks (we tried to replicate their networks, but we failed), they have a whole plethora of sound ideas - using Byte Pair Encoding (BPE), using model strides more than 2 or 3, using what is in a nutshell a separable convolution;
- JasperNet. They report that they trained networks either for 50 epochs or for 500 epochs without explicitly mentioning training time or the amount of hardware used;
- Wav2Letter. In retrospect, it is amazing that the Wav2Letter paper actually did not report any of these metrics. We played with Wav2Letter-like networks and they have around 20-30M parameters, but they fail to deliver for Russian language;
- Deep Speech 2. It is hard to include the original Deep Speech paper in this list, mainly because of how many different things they tried, popularized, and pioneered. We just include their most cited experiments with LibriSpeech with their recurrent models;
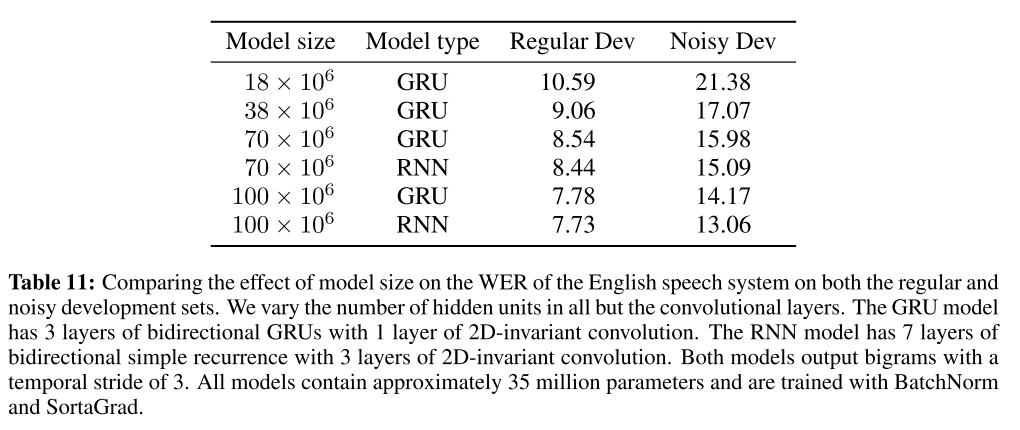
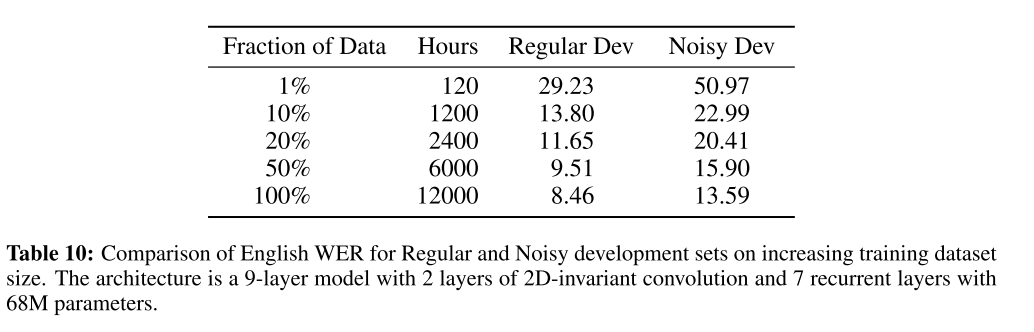
Looking at the table, we can also immediately spot a few trends:
- Large compute is used almost everywhere, and there are no clear visible hardware requirement trends (even in paper claiming to alleviate the computation burden);
- Networks range from compact to huge, but overall it is safe to assume that the majority of networks overfit on LibriSpeech regardless of compute used;
- If you jump to Overall Progress Made and see our convergence curves and the below convergence curves, you will see that 90% of convergence with our best networks happens during the first 2-3 days, which is consistent with the industry (but we use much less compute overall);
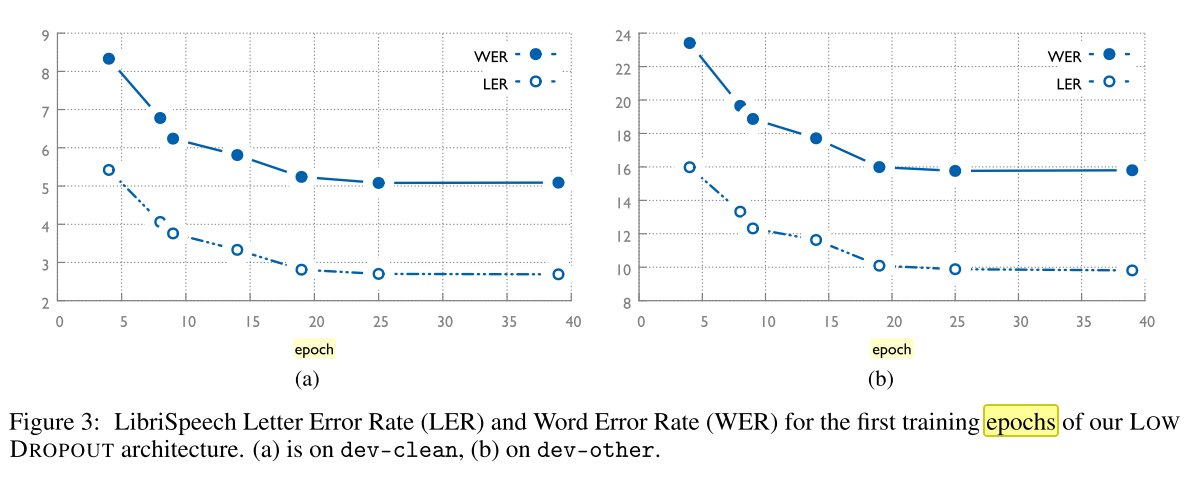
Other Common Criticisms
Common criticisms when dealing with ML or STT:
- Usually papers are vague on the generalization of their approach, i.e. out-of-domain testing;
- Very little attention is paid to hyper-parameter stability;
- Brand new semi-supervised and unsupervised learning approaches (wav2vec, cyclic STT-TTS training) do not perform any sanity or back-of-the envelope checks for sample efficiency, robustness, or generalization and mostly focus on the factor of novelty;
- Doing everything end-to-end mantra. Academic papers usually overfit their LMs and post-processing on a small and idealistic dataset (LibriSpeech) and methods claiming top end-to-end results are extremely suboptimal because the amount of data available in text domain is at least 1000x higher (e.g. compare the size of Wikipedia to all texts in LibriSpeech);
- Over-reliance on Mel Frequency Cepstral Coefficients. We have not yet seen a proper comparison of Short-time Fourier transform, Mel Frequency Cepstral Coefficients, Mel-filter banks, wavelets, etc. In our experiments on smaller datasets, in the end there was no difference between what to use, but on real-life noisy data
- Short-time Fourier transforms were the best. Additionally, we failed to run any meaningful experiments with newer network filters like SincNet.
Criticisms of Our Solution
To be fair, we are guilty of some of our own criticisms:
- We used private data to train our models, albeit the size of the private dataset is orders of magnitude smaller than the whole dataset size, i.e. around 500 hours (100 of them manually annotated) for the “high quality benchmark” versus 20,000 hours in the public dataset.
- Additionally, the main results reported in this article were achieved with only negligible amounts of manual annotation (i.e. we manually annotated only the validation sets). We used these small amounts of private data mainly because we needed production results in our main domain.
- Unlike our dataset, we did not share our training pipeline, the particular hyper-parameters and model settings as well as pre trained models because all of this research was done for a self funded commercial project. We could have opted for sharing under a non-commercial license, but the general consensus is that intellectual property law does not work in Russia unless you are a state-backed monopoly. We are looking for financing options that would enable us to open-source everything, including future work on other languages;
Conclusion
There has been a wide wave of disenchantment in supervised ML in mass media lately. This happens because there was irrational exuberance and over-investment in the field driven by the hype fueled by the promises that cannot be delivered.
This is sad, because such a situation may lead to under investment in
fields that would benefit the society as a whole. For example, a story of autonomous truck company Starsky perfectly illustrates this point. They delivered the working product, but the market was not ready for it in part due to “AI-disenchantment”. Borrowing the concept and image from this article, you can visualize the reaction of the society to a new technology with a curve below. If technology has reached L1, it will be widely adopted and everyone will benefit. If L2 is reachable, but requires a lot of investment and time, probably only large corporations or state-backed monopolies will reap its fruits. If L3 is the case, then probably people will just revisit this technology in future.
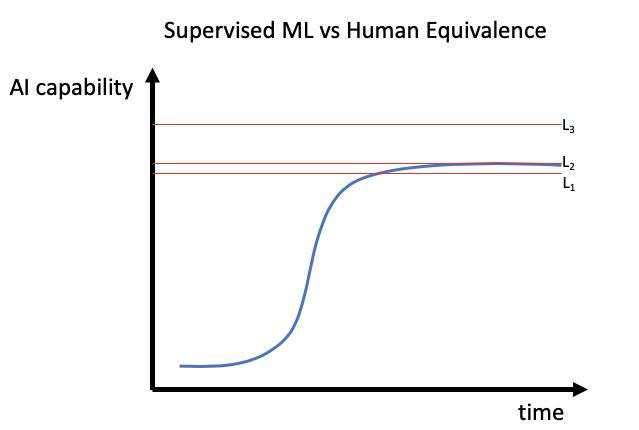

Andrej Karpathy explains in his technical lecture why it is difficult to get the last 1% of quality in self-driving cars.
But what shall we take away from this? Why should we care and participate? Speech as a technology has a wide potential of automating boring tasks and giving people leverage to spend more of their attention to things that matter. This has happened before. 20 years ago such a “miracle” technology was a relational database. Please read this amazing post by Benedict Evans on this topic.
“Relational databases were a new fundamental enabling layer that
changed what computing could do. Before relational databases appeared in the late 1970s, if you wanted your database to show you, say, 'all customers who bought this product and live in this city', that would generally need a custom engineering project. Databases were not built with structure such that any arbitrary cross-referenced query was an easy, routine thing to do. If you wanted to ask a question, someone would have to build it. Databases were record-keeping systems; relational databases turned them into business intelligence systems.
This changed what databases could be used for in important ways, and so created new use cases and new billion dollar companies. Relational databases gave us Oracle, but they also gave us SAP, and SAP and its peers gave us global just-in-time supply chains - they gave us Apple and Starbucks. By the 1990s, pretty much all enterprise software was a relational database - PeopleSoft and CRM and SuccessFactors and dozens more all ran on relational databases. No-one looked at SuccessFactors or Salesforce and said "that will never work because Oracle has all the database" - rather, this technology became an enabling layer that was part of everything.
So, this is a good grounding way to think about ML today - it’s a step change in what we can do with computers, and that will be part of many different products for many different companies. Eventually, pretty much everything will have ML somewhere inside and no-one will care. An important parallel here is that though relational databases had economy of scale effects, there were limited network or ‘winner takes all’ effects. The database being used by company A doesn't get better if company B buys the same database software from the same vendor: Safeway's database doesn't get better if Caterpillar buys the same one. Much the same actually applies to machine learning: machine learning is all about data, but data is highly specific to particular applications. More handwriting data will make a handwriting recognizer better, and more gas turbine data will make a system that predicts failures in gas turbines better, but the one doesn't help with the other. Data isn’t fungible.”
Developing his notion “machine learning = just an enablement stack to answer some questions, like the ubiquitous relational database” it is only up to us to decide the fate of speech technologies. Whether their benefits will be reaped by the select few or by the society as a whole remains unseen. We firmly believe that it is certain that speech technologies will become a commodity within 2-3 years. The only question remaining - will they more look like PostgreSQL or Oracle? Or will 2 models co-exist?
Author Bio
Alexander Veysov is a Data Scientist in Silero, a small company building NLP / Speech / CV enabled products, and author of Open STT - probably the largest public Russian spoken corpus (we are planning to add more languages). Silero has recently shipped its own Russian STT engine. Previously he worked in a then Moscow-based VC firm and Ponominalu.ru, a ticketing startup acquired by MTS (major Russian TelCo). He received his BA and MA in Economics in Moscow State University for International Relations (MGIMO). You can follow his channel in telegram (@snakers41).
Acknowledgments
Thanks to Andrey Kurenkov and Jacob Anderson for their contributions to this piece.
Citation
For attribution in academic contexts or books, please cite this work as
Alexander Veysov, "A Speech-To-Text Practitioner’s Criticisms of Industry and Academia", The Gradient, 2020.
BibTeX citation:
@article{veysov2020sttcriticism,
author = {Veysov, Alexander},
title = {A Speech-To-Text Practitioner’s Criticisms of Industry and Academia},
journal = {The Gradient},
year = {2020},
howpublished = {\url{https://thegradient.pub/a-speech-to-text-practitioners-criticisms-of-industry-and-academia/ } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.




{kind=link}
{kind=link}
{kind=link}
{kind=link}