
What is intelligence? The project to define what the late Marvin Minsky refers to as a suitcase word — words that have so much packed inside them, making it difficult for us to unpack and understand this embedded intricacy in its entirety — has not been without its fair share of challenges. The term does not have a single agreed-upon definition, with the dimensions of description shifting from optimization or efficient search space exploration to rationality and the ability to adapt to uncertain environments, depending on which expert you ask. The confusion becomes more salient when one hears news of machines achieving super-human performance in activities like Chess or Go — traditional stand-ins for high intellectual aptitude — but fail miserably in tasks like grabbing objects or moving across uneven terrain, which most of us do without thinking.
But, several themes do emerge when we try to corner the concept. Our ability to explain why we do what we do makes a fair number of appearances in the list of definitions proposed by multiple disciplines. If we are to extend this to algorithms — and there is no reason why we cannot or should not — we should expect intelligent machines to explain themselves in ways sensible to us. That is precisely where interpretability and explainability fits into the picture.
Table of ContentsWhat is interpretability?
Although there is no agreed-upon formal or mathematical definition of interpretability as of yet, there are still useful non-mathematical definitions that strike at the heart of what the concept stands for. For instance, Miller (2017) defines interpretability as the degree to which human beings can understand the cause of a decision. Other equally valid definitions have also been proposed — the degree to which a machine's output can be consistently predicted (Kim et. al. (2016)). Both definitions allude to the common theme of the ability to explain why a particular decision or prediction was made for a given input or a range of inputs. Closely connected to interpretability is explainability, which was popularised in the conceptualisation of Explainable Artificial Intelligence (XAI) systems (Turek, 2016). Explainability is typically associated with learnt model internals (like neural network weights or node splits of a tree), which expose the internal mechanics and functioning to some degree. However, since no formal and precise definitions exist for either concept, they have been used interchangeably by many researchers to refer to a general ability to understand or explain why a model behaves the way it does.
Motivating the Need for Interpretability
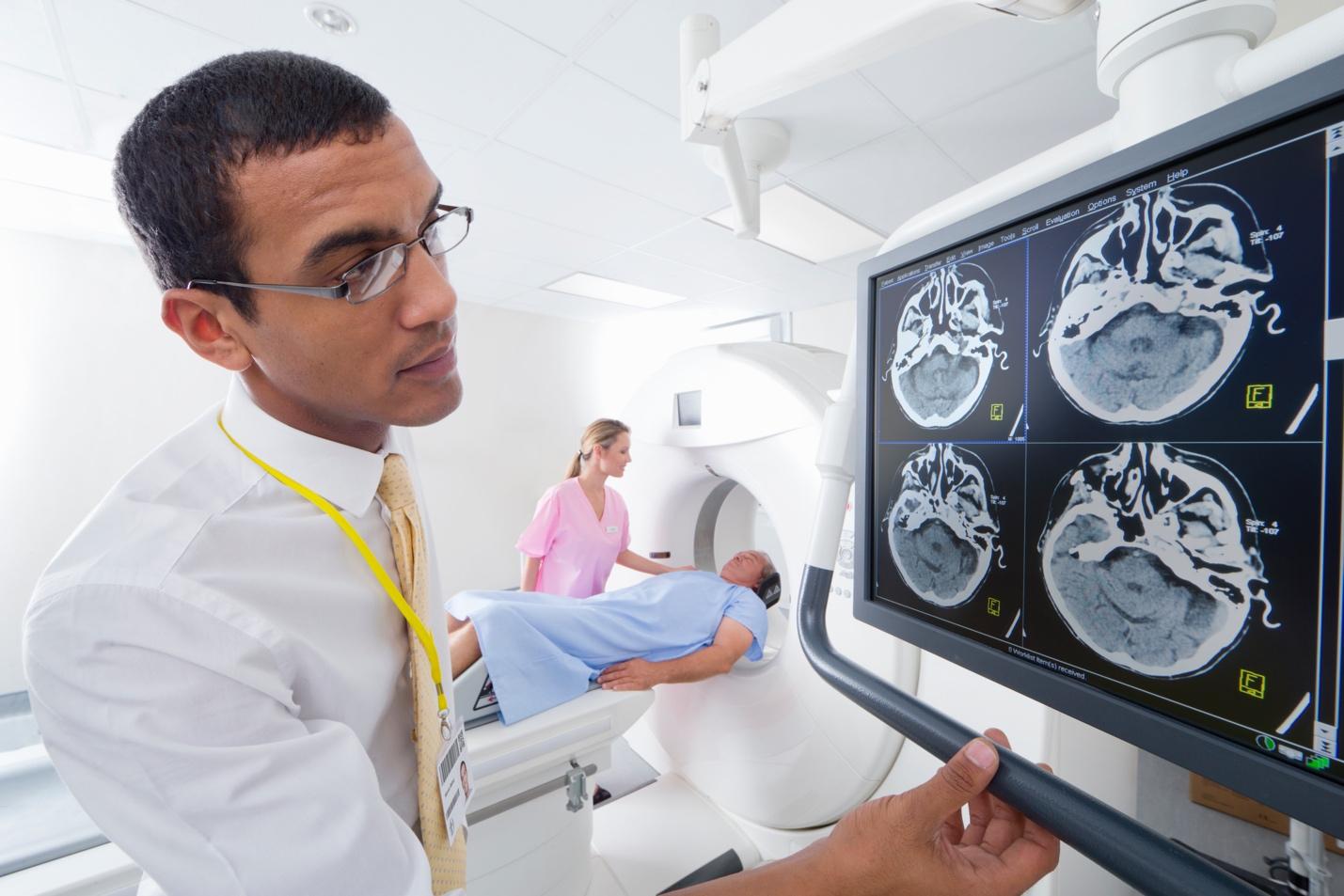
Fig 1: Higher the stakes of model decision, the more relevant it is to have a supporting explanation.
Interpretability makes black-box models less opaque and imbues it with explanatory power to explain its predictions and decisions to its users. Why not just trust a model with state-of-the-art performance and ignore how the results were calculated? (Doshi-Velez and Kim 2017) proposes that correct predictions do not solve real-world problems in full and it is equally important to know why predictions are made. Consider a computer vision model used by oncologists to assess the presence of cancerous tumours in a patient's scan report to determine the next course of treatment. Such decisions have wide-ranging physical and psychological implications for the patient, who is well within their legal right in most countries to seek clarification on the doctor's diagnosis. An answer that the prediction was made by a sophisticated Computer Vision model with state-of-the-art classification performance on multiple datasets is neither sufficient nor sensible an explanation to provide to individuals with fatal ailments or their loved ones, who would have to reorient their lives around the new development. The spirit of the example can be extended towards many scenarios where the unexpected happens — a rejected loan application, a misclassified threat by automated defence systems etc. Our research (Kartha et. al. 2020) on providing explanatory power to anomaly detection systems is motivated by how explanations are particularly required of models deployed in mission-critical domains and detecting anomalous behaviour. They are the first countermeasure against ignorance of the inner workings of these powerful algorithms that are increasingly being integrated into several domains, which govern different aspects of our personal, professional and social lives.
We need to tread with caution as we offload more and more social and cultural responsibilities to algorithms. The process of increasing integration must come through increasing informed social acceptance that, in turn, requires trust. (Doshi-Velez and Kim 2017) outlines several first-order and second-order benefits to engendering models with explainability, the result of all of which is the engendering of trust in these algorithms to govern more of our lives. Some of these benefits include:
- Fairness: An interpretable model will be able to tell you which features it deemed as important in making its decision, allowing you to double-check and clarify whether it has picked up patterns discriminatory towards specific identity groups. Since the training data is likely to have such historical biases embedded in them and targeted discrimination can still appear implicitly in entangled features (for e.g. racial segregation policies of the past is likely to correlate an attribute like ethnicity with the neighbourhood of the individual —a discriminatory signal that the model can learn — even if you drop ethnicity in the feature selection process).
- Privacy: Similar in spirit to the previous scenario, we can identify whether uniquely identifying signals are being picked by machine learning models in making their predictions and take necessary preventive steps (like anonymization) to arrest such privacy violations. Such measures are not after-thoughts but are requirements for organizations to work in contexts defined within legally binding privacy frameworks like GDPR.
- Robustness: As adoption rises, the predictions that they make can inform decisions in the real world. For example, a policing model that predicts the likelihood of crime given a neighbourhood, trained on data with historical biases, can perpetuate a dangerous positive feedback loop, assigning higher probabilities of crime to neighbourhoods that have been victims of discriminatory policies in the past. Higher the assigned probability, higher the patrolling. Higher the patrolling, higher the reported crime rate. Longitudinal studies around the cumulative aspects of such design choices in real life settings have not been undertaken as the field is still nascent. However, such extrapolations are not necessarily speculative fantasies, as the perpetuation of different biases by feedback loops in machine learning systems have been actively studied in experimental contexts.
Last but not the least, we can postulate with reasonable confidence that interpretability is a necessary condition in super-intelligent systems to ensure compliance/alignment with human values and goals. For instance, in his famous thought experiment about superintelligent paperclip manufacturing AI, (Bostrom, 2003) highlights how potential misalignment could lead to feedback loops that have disastrous consequences like the system deciding to transform most of the planet and life on it, into manufacturing facilities and raw materials. It is human to ask why and hence, if such systems are to share our values, they too need to have the ability to do so.
The Current Landscape of Interpretability
Current techniques to imbue models with explanatory power, come in many different shapes and sizes. There also exists several criteria used to create an overall taxonomy of such methods. (Molnar, 2019) provides an excellent and comprehensive overview of contemporary interpretability techniques and the different criteria that we can use to differentiate between them, some of which includes:
- Intrinsic/Post-hoc?: This criteria is used to differentiate between making the model simpler & interpretable on one hand and running certain methods on a complex model after training it, in a post-hoc fashion. A simpler linear regression model is intrinsically interpretable, with the coefficients determining the influence the corresponding feature has on the target output. However, the inner workings of deep neural networks are much more obfuscated. In such settings, you can generate good visual intuitive explanations by pairing the model with a post-hoc method like SHAP (Lundberg and Lee, 2017) or LIME (Ribeiro et al., 2017).
- Model-Specific/Model-Agnostic?: This criteria is used to differentiate between interpretability techniques that work only with a specific type of model and those that work with a reasonably wide range of model families. For instance, MDI (Mean Decrease in Impurity) based feature importance (Breiman, 2001) is a technique specific to the Random Forest. Our main research contribution is the development of a weighting scheme specific to rendering Isolation Forests interpretable (Kartha et. al. 2020). On the other hand, the previously mentioned techniques, LIME and SHAP, can be used to explain most models and hence, are examples of model-agnostic methods.
- Local/Global?: This criteria is used to differentiate methods that are able to explain specific predictions from methods that are able to provide only a global overview. For instance, LIME is a common example of a local interpretability method whereas feature importance measures or partial dependence plots (Friedman, 2001) provide global overviews. It is not necessarily a dichotomy as techniques like SHAP, fundamentally based on local predictions, can provide aggregate measures and global overviews.
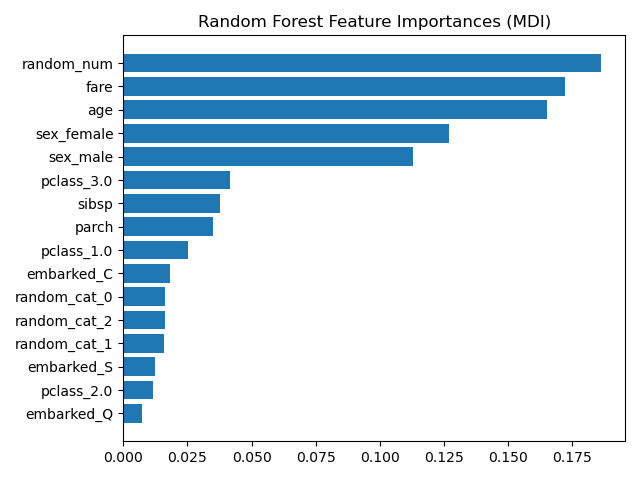


Fig 2: A collection of outputs from different post-hoc interpretability techniques. (a) shows the SHAP explanations for 2 input images, where the “redness” of pixels represent higher SHAP values, which increase the probability of that particular class while the “blueness” represents the opposite. (b) highlights the aggregate feature importance measures for different attributes of the Titanic dataset in the fitting of a Random Forest model. (c) shows LIME explanations highlighting how important certain tokens of the text is in explaining the predicted class label of an instance.
Intrinsic Interpretability
Naturally, the most straightforward way to have interpretability in your system is to use an interpretable model to generate your predictions. An extreme example of this advice would involve swapping in your deep, complex yet opaque neural network with a more transparent but simpler linear or logistic regression as one needs to look only at the coefficients to understand the marginal influence each corresponding feature has on the target variable. At first glance, it might seem like following such advice would almost always have an extremely detrimental impact on the performance (or whichever metric that you care most about) of your system, which could very well be the reason why such a system was built. However, (Rudin, 2018) highlights there is not always a marked trade-off between accuracy and interpretability, in contrast to commonly held belief. (Lou et al., 2012) illustrated this very same point earlier, through a thorough empirical evaluation between the more transparent generalised additive models (GAMs) and the more obfuscated tree ensemble methods. Although the ensemble methods do have lower error rates on average, the actual values often lie within a standard deviation of one another. (Rudin, 2018) further makes the point of using such interpretable models squarely in situations like criminal recidivism, where high-stakes decisions are involved. Higher the stakes, higher the required interpretability of the model taking the decision.
Post-hoc Methods
There are convincing arguments to the counter as well, whose critics cite several benefits in separating the 2 concerns of modelling complexity and interpretability, the most notable of which is greater flexibility as one can pair these post-hoc methods with any machine learning model in production regardless of how interpretable they are (Ribeiro et al., 2016). It becomes possible to evaluate different post-hoc interpretability techniques on the same underlying model, giving us more nuanced insights. Post-hoc techniques can either be model-specific or model-agnostic, both with their fair share of advantages and disadvantages. The most mature and adopted from the model-agnostic school of post-hoc interpretability techniques are SHAP and LIME, both of which have robust and mature implementations in popular programming languages (refer here and here). Based on traditional Shapley values, SHAP uses a game-theoretic framework to reframe the task of explaining the contribution of different features to the model output for a particular instance, into one of finding the most optimal allocation of payoff to this coalition of features, where the payoff is the difference between the model output for the particular instance compared to a base value. LIME, on the other hand, employs a practical strategy of generating an explanation for a specific instance by perturbing a small local neighbourhood in vector space around it, drawing several synthetic samples from this space and fitting an interpretable model. The process is fast and works for many situations but is empirically unstable, particularly when decision boundaries are far away from the local neighbourhood of points of interest, especially in contexts like anomaly detection (Kartha et. al. 2020). Both approaches involve creating and wrapping an Explainer object around the trained model, which has associated attributes and methods amenable to visual inspection of how relevant/important each feature is to the model output. Covering the wide range of post-hoc techniques is beyond the scope of this article and interested readers can refer to this document as a springboard into the domain.
Interpretability in Neural Networks
Feedforward neural networks with sigmoid activation functions have been theoretically shown to approximate any arbitrary continuous non-linear functions at the turn of the last decade of the 20th century (Cybenko, 1989). Ever since then, the proof cited as the Universal Approximation Theorem, has been extended to different activation functions and different neural network architectures like CNNs and RNNs. The neural network's flexibility and power, supported by an explosion in data generation, proliferation of cheap compute and breakthrough moments in benchmark tests, have contributed to them being the dominant force they are today. However, this flexibility comes at a cost. Neural networks, especially those that are several layers deep, are notorious for being black-box models as they capture the complexity of the domain through decomposable but complex and intertwined combinations of more well-understood non-linear functions. Both LIME and SHAP can be used to explain a neural network's predictions as they are model-agnostic. There also exists post-hoc model-specific methods that leverage the structure of the fitted neural network to explain its predictions. If one wants finer explainability (e.g. what has a specific neuron, nested deep within the network architecture, learnt?), one has to resort to such model-specific methods. Such methods involve investigating the feature values resulting in maximal activation for each neuron (Feature Visualization), abstract concepts that groups of neurons have learnt (Concept Activation Vectors), correspondence between input subcomponents (e.g. a pixel in the input image) and output prediction (e.g. Saliency Maps) and the like. Efforts have also been made to create network architectures that are more explainable by design, while striving to produce comparable levels of performance than their black-box counterparts, as post-hoc explanations could be sensitive to factors that are actually not relevant to the model output (Kindermans et. al, 2017). An example development in this direction comes in the form of Logic Explained Networks (Ciravegna et. al., 2021), which imposes certain constraints on the inputs and generates explanations as First-Order Logic formulas.
The Limitations of Interpretability
It must be noted that interpretability is only the first countermeasure and not the final say against not knowing the underlying relationships and hence, must be considered cautiously. This mistrust one must always keep in mind, is baked into the very paradigm of the field of Supervised Learning. It is correlational in nature and hence, not guaranteed to learn and reveal true cause-and-effect relationships. This resource comically highlights one of the problems at the heart of it by considering correlations between attributes so patently unrelated to one another in any context useful to human activity, but happen to be correlated by pure accident. For instance, consider the strongly correlated relationship between the number of films Nicholas Cage has appeared in a year with the people who drowned by falling into a pool in the United States.
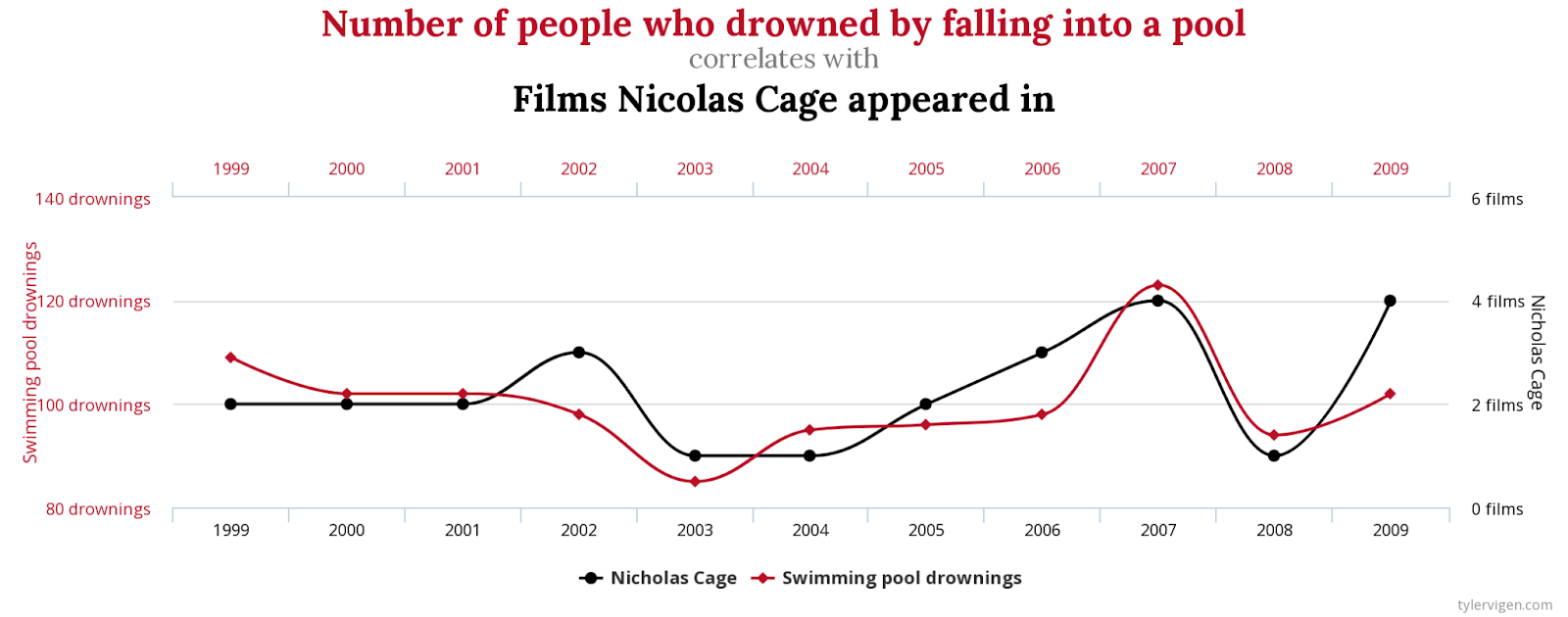
Fig 3: Is Nicholas Cage appearing in films a factor behind swimming pool drownings? No.
This is an example of a spurious correlation. Not always so stark as those found in the resource mentioned earlier, spurious correlations in input data can be picked up and learnt as predictive relationships by models. For instance, consider a financial loan dataset in which both business size and loan size adversely affect loan default rate and are strongly correlated with one another. If both attributes are included in the model, they will be strong predictors of loan default rate. The same will be attested to, by interpretability methods as well as the target output do get influenced by perturbing these attributes. However, the question of what causes a business to default on its loan is not really answered? Is it the size of the business or is it the size of the loan? Do smaller businesses procure smaller business loans, which are strong predictors of default rate? It makes sense that this is the case as big businesses procuring a small loan (which, in itself, is perhaps unlikely) is less likely to default. We are able to reason about these relationships and make qualitative assessments to uncover these true relationships because of implicit domain expertise. The tremendous benefits and achievements of Supervised Learning cannot be discounted but it does fall short of allowing us to reason like this. By extension, the paradigm also does not allow us to reason about cause-and-effect scenarios interventions (e.g. what would happen if we stop giving loans to businesses that have a certain size?) or counterfactuals (e.g. what would have happened if we had stopped giving loans to businesses that have a certain size 2 years ago?).
Models are simulations of reality - they abstract away the messiness and try to capture the "essence" of the underlying data generation process that they are trying to model. Since interpretability techniques are designed to make the model explainable and not to uncover the underlying relationships that the model is trying to learn, they, too, will fall prey to such spurious correlations. This becomes even more relevant in a decision-making context in mission-critical areas — the very premise that this article started with, to motivate the need for interpretability. It is poetic that the same issue be used to underscore the fact that the scope of what we need extends beyond interpretability.
What next for Interpretability?
To make good decisions using the output of any interpretability method, we typically combine it with causal knowledge, often not formally specified but simply referred to as domain expertise. Causal Inference is a promising field that formalises this process. Inferring causal relationships from generated data is difficult, even more so when the data is not experimental but observational in nature where we cannot actively intervene in the data generation process. Hence, for causal inference, we often make simplifying modelling assumptions, one of the most popular frameworks being Structured Causal Models (Pearl, 2010), to encode and specify these causal insights aka domain expertise directly into a dependency graph.
Formulating an answer to “why” something is, is the central organising principle around which the scientific enterprise is built. With deeply fundamental questions around this principle being actively studied, this intersection of causality and interpretability is an exciting and promising research area in the field of Machine Learning. Needless to say, synthesising a comprehensive and computationally tractable framework drawing from the well of both interpretability and causality will certainly be a milestone in the path to building truly intelligent systems. Only time will tell.
Citation
For attribution in academic contexts or books, please cite this work as
Nirmal Sobha Kartha, "Explain Yourself - A Primer on ML Interpretability & Explainability", The Gradient, 2021.
BibTeX citation:
@article{kartha2021explain,
author = {Kartha, Nirmal Sobha},
title = {Explain Yourself - A Primer on ML Interpretability & Explainability},
journal = {The Gradient},
year = {2021},
howpublished = {\url{https://thegradient.pub/explain-yourself} },
}




{kind=link}
{kind=link}
{kind=link}
{kind=link}