
This piece was a runner-up for the inaugural Gradient Prize.
The Empirical and Data-Driven Revolution
In the early 1990s a statistical revolution overtook artificial intelligence (AI) by a storm – a revolution that culminated by the 2000’s in the triumphant return of neural networks with their modern-day deep learning (DL) reincarnation. This empiricist turn engulfed all subfields of AI although the most controversial employment of this technology has been in natural language processing (NLP) – a subfield of AI that has proven to be a lot more difficult than any of the AI pioneers had imagined. The widespread use of data-driven empirical methods in NLP has the following genesis: the failure of the symbolic and logical methods to produce scalable NLP systems after three decades of supremacy led to the rise of what are called empirical methods in NLP (EMNLP) – a phrase that I use here to collectively refer to data-driven, corpus-based, statistical and machine learning (ML) methods.
The motivation behind this shift to empiricism was quite simple: until we gain some insights in how language works and how language is related to our knowledge of the world we talk about in ordinary spoken language, empirical and data-driven methods might be useful in building some practical text processing applications. As Kenneth Church, one of the pioneers of EMNLP explains, the advocates of the data-driven and statistical approaches to NLP were interested in solving simple language tasks – the motivation was never to suggest that this is how language works, but that “it is better to do something simple than nothing at all”. The cry of the day was: “let’s go pick up some low-hanging fruit”. In a must-read essay appropriately entitled “A Pendulum Swung Too Far”, however, Church (2007) argues that the motivation of this shift have been grossly misunderstood. As McShane (2017) also notes, subsequent generations misunderstood this empirical trend that was motivated by finding practical solutions to simple tasks by assuming that this Probably Approximately Correct (PAC) paradigm will scale into full natural language understanding (NLU). As she puts it: “How these beliefs attained quasi-axiomatic status among the NLP community is a fascinating question, answered in part by one of Church’s observations: that recent and current generations of NLPers have received an insufficiently broad education in linguistics and the history of NLP and, therefore, lack the impetus to even scratch that surface.”
This misguided trend has resulted, in our opinion, in an unfortunate state of affairs: an insistence on building NLP systems using ‘large language models’ (LLM) that require massive computing power in a futile attempt at trying to approximate the infinite object we call natural language by trying to memorize massive amounts of data. In our opinion this pseudo-scientific method is not only a waste of time and resources, but it is corrupting a generation of young scientists by luring them into thinking that language is just data – a path that will only lead to disappointments and, worse yet, to hampering any real progress in natural language understanding (NLU). Instead, we argue that it is time to re-think our approach to NLU work since we are convinced that the ‘big data’ approach to NLU is not only psychologically, cognitively, and even computationally implausible, but, and as we will show here, this blind data-driven approach to NLU is also theoretically and technically flawed.
Language Processing vs. Language Understanding
While NLP (Natural Language Processing) and NLU (Natural Language Understanding) are often used interchangeably, there is a substantial difference between the two and it is crucial to highlight this difference. In fact, recognizing the technical difference between language understanding and the mere language processing will make us realize that data-driven and machine learning approaches, while might be suitable for some NLP tasks, they are not even relevant to NLU. Consider the most common ‘downstream NLP’ tasks:
- summarization
- topic extraction
- named-entity recognition (NER)
- (semantic) search
- automatic tagging
- clustering
All of the above tasks are consistent with the Probably Approximately Correct (PAC) paradigm that underlies all machine learning approaches. Specifically, evaluating the output of some NLP system regarding the above tasks is subjective: there is no objective criteria to judge if one summary is better than another; or if the (key) topics/phrases extracted by some system are the better than those extracted by another system, etc. However, language understanding does not admit any degrees of freedom. A full understanding of an utterance or a question requires understanding the one and only one thought that a speaker is trying to convey. To appreciate the complexity of this process, consider the following natural language query (posed to some database/knowledge graph):
- Do we have a retired BBC reporter that was based in an East European
country during the Cold War?
In some database there will be one and only one correct answer to the above query. Thus, translating the above to a formal SQL (or SPARQL) query is incredibly challenging because we cannot get anything wrong. Understanding the ‘exact’ thought that underlies this question involves:
- Interpreting ‘retired BBC reporter’ properly – i.e., as the set of all reporters that worked at BBC and who are now retired.
- Filtering the above set further by keeping all those ‘retired BBC reporters’ that also worked in some ‘East European country’. In addition to the geographical constraint there’s also a temporal constraint in that the working period of those ‘retired BBC reporters’ must be ‘during the Cold War’.
- The above means attaching the prepositional phrase ‘during the Cold War’ to ‘was based in’ and not to ‘an East European country’ (think of the different prepositional phrase attachment if ‘during the Cold War’ was replaced by ‘with membership in the Warsaw Pact’)
- Doing the correct quantifier scoping: we are looking not for ‘a’ (single) reporter who worked in ‘some’ East European country, but to any reporter that worked in any East European country
None of the above challenging semantic understanding functions can be ‘approximately’ or ‘probably’ correct – but absolutely correct. In other words, we must get, from a multitude of possible interpretations of the above question, the one and only one meaning that, according to our commonsense knowledge of the world, is the one thought behind the question some speaker intended to ask. In summary, then, true understanding of ordinary spoken language is quite a different problem from mere text (or language) processing where we can accept approximately correct results – results that are also correct with some acceptable probability.
With this brief description it should become clear why NLP is different from NLU and why NLU is difficult for machines. But what exactly is the source of difficulty in NLU?
Why NLU is Difficult: The Missing Text Phenomenon
Let us start first with describing what we call the “missing text phenomenon” (MTP), that we believe is at the heart of all challenges in natural language understanding. Linguistic communication happens as shown in the image below: a speaker encodes a thought as a linguistic utterance in some natural language, and the listener then decodes that linguistic utterance into (hopefully) the thought that the speaker intended to convey!
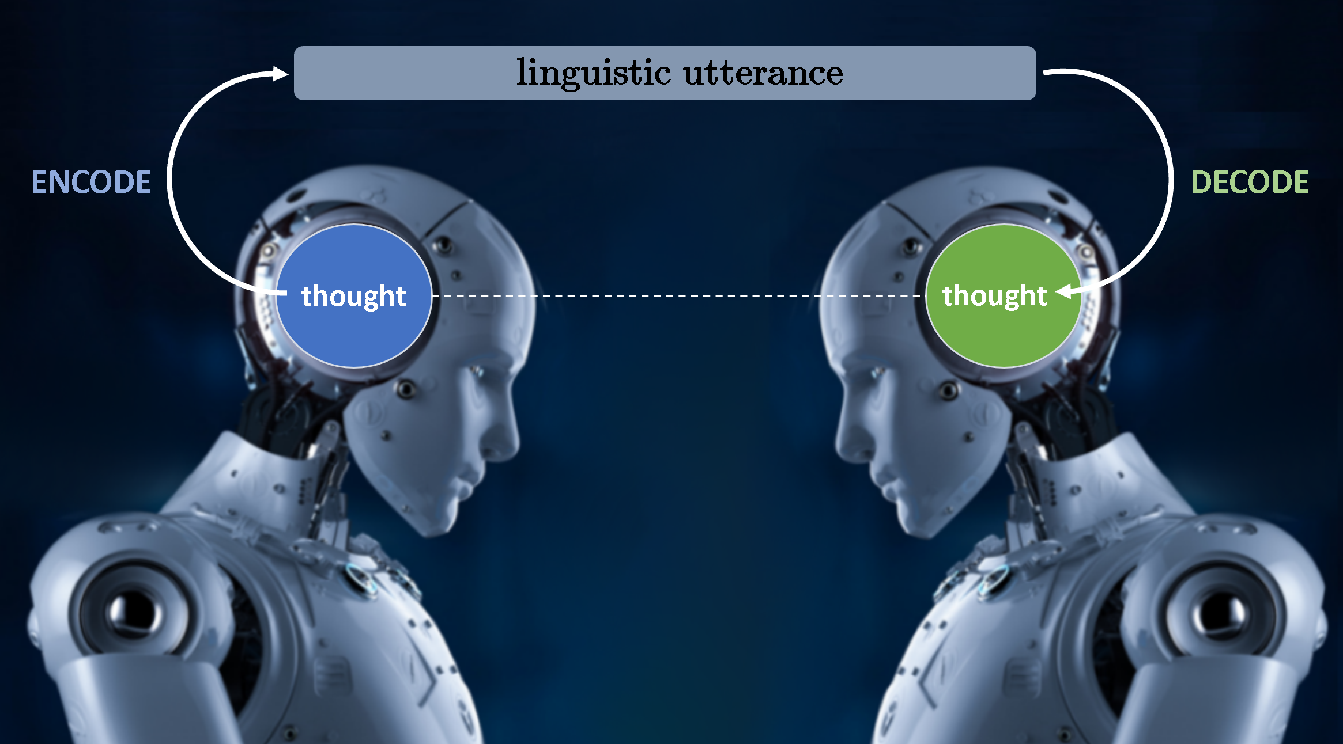
It is that “decoding” process that is the ‘U’ in NLU — that is, understanding the thought behind the linguistic utterance is exactly what happens in the decoding process. Moreover, there are no approximations or any degrees of freedom in this ‘decoding’ process — that is, from the multitude of possible meanings of an utterance, there is one and only one thought the speaker intended to convey and the ‘understanding’ in the process of decoding the message must get at that one and only one thought, and this is precisely why NLU is difficult. Let’s elaborate.
In this complex communication there are two possible alternatives for optimization, or for effective communication: (i) the speaker can compress (and minimize) the amount of information sent in the encoding of the thought and hope that the listener will do some extra work in the decoding (uncompressing) process; or (ii) the speaker will do the hard work and send all the information needed to convey the thought which would leave the listener with little to do (see this article for a full description of this process). The natural evolution of this process, it seems, has resulted in the right balance where the total work of both speaker and listener is equally optimized. That optimization resulted in the speaker encoding the minimum possible information that is needed, while leaving out everything else that can be safely assumed to be information that is available for the listener. The information we (all!) tend to leave out is usually information that we can safely assume to be available for both speaker and listener, and this is precisely the information that we usually call common background knowledge. To appreciate the intricacies of this process, consider the (unoptimized) communication in the yellow box below, along with the equivalent but much smaller text that we usually say (in green).
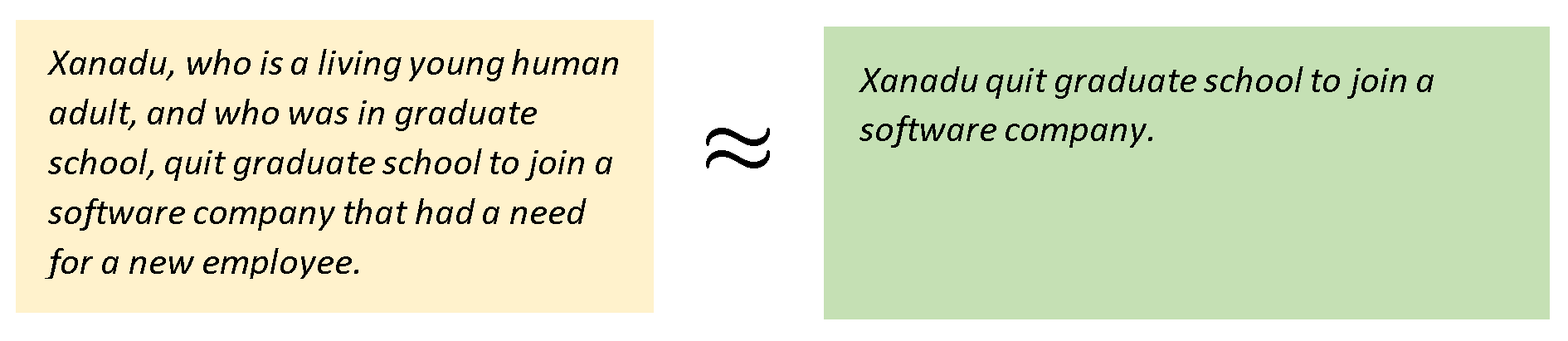
The much shorter message in the green box, which is how we usually speak, conveys the same thought as the longer one. Usually we do not explicitly state all the other stuff and precisely because we all know:

That is, for effective communication, we do not say what we can assume we all know! This is also precisely why we all tend to leave out the same information — because we all know what everyone knows , and that is precisely what we call “common” background knowledge. This genius optimization process that humans have developed in about 200,000 years of evolution works quite well, and precisely because we all know what we all know. But this is where the problem is in NLU: machines don’t know what we leave out, because they don’t know what we all know. The net result? NLU is very very difficult, because a software program cannot fully understand the thoughts behind our linguistic utterances if they cannot somehow “uncover” all that stuff that humans leave out and implicitly assume in their linguistic communication. That, really, is the NLU challenge (and not parsing, stemming, POS tagging, named-entity recognition, etc.)
Here are some well-known challenges in NLU — with the label such problems are usually given in computational linguistics. Shown in figure 2 are (just some of) the missing text highlighted in red.

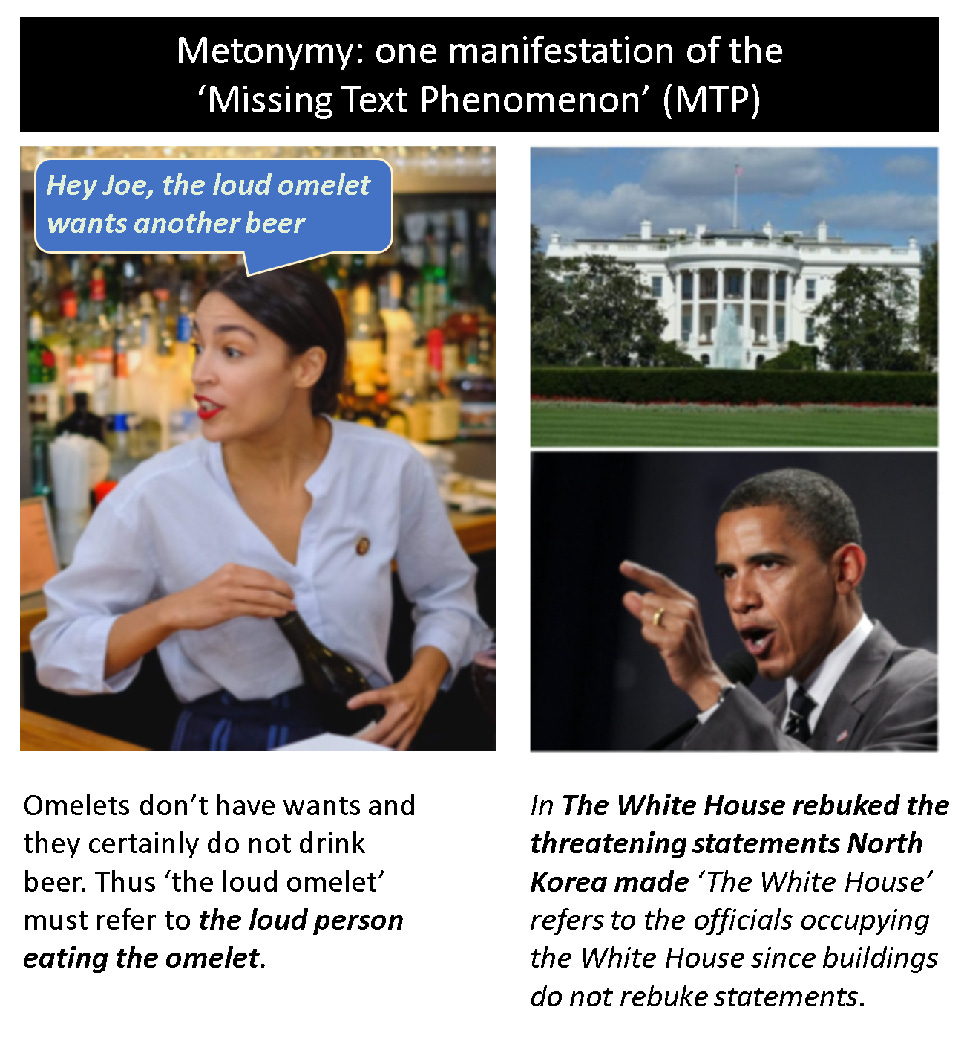
In figure 2 above a set of well-known challenges in NLU are shown. What these examples show is that the challenge in NLU is to discover (or uncover) that information that is missing and implicitly assumed as shared and common background knowledge. Shown in figure 3 below are further examples of the ‘missing text phenomenon’ as they relate the notion of metonymy as well as the challenge of discovering the hidden relation that is implicit in what are known as nominal compounds.

With this background we now provide three reasons as to why Machine Learning and Data-Driven methods will not provide a solution to the Natural Language Understanding challenge.
ML Approaches are not even Relevant to NLU: ML is Compression, Language Understanding Requires Uncompressing
The above discussion was (hopefully) a convincing argument that natural language understanding by machines is difficult because of MTP – that is, because our ordinary spoken language in everyday discourse is highly (if not optimally) compressed, and thus the challenge in “understanding” is in uncompressing (or uncovering) the missing text – while for us humans that was a genius invention for effective communication, language understanding by machines is difficult because machines do not know what we all know. But the MTP phenomenon is precisely why data-driven and machine learning approaches, while might be useful in some NLP tasks, are not even relevant to NLU. And here we present the formal proof for this (admittedly) strong claim:
The equivalence between (machine) learnability (ML) and compressibility (COMP) has been mathematically established. That is, it has been established that learnability from a data set can only happen if the data is highly compressible (i.e., it has lots of redundancies) and vice versa (see this article and the important article “Learnability can be Undecidable” that appeared in 2019 in the journal Nature). While the proof between compressibility and learnability is quite technically involved, intuitively it is easy to see why: learning is about digesting massive amounts of data and finding a function in multi-dimensional space that ‘covers’ the entire data set (as well as unseen data that has the same pattern/distribution). Thus, learnability happens when all the data points can be compressed into a single manifold. But MTP tells us that NLU is about uncompressing. Thus, what we now have is the following:

What the above says is the following: machine learning is about discovering a generalization of lots of data into a single function. Natural language understanding, on the other hand, and due to MTP, requires intelligent ‘uncompressing’ techniques that would uncover all the missing and implicitly assumed text. Thus, machine learning and language understanding are incompatible – in fact, they are contradictory.
ML Approaches are not even Relevant to NLU: Statistical Insignificance
ML is essentially a paradigm that is based on finding some patterns (correlations) in the data. Thus, the hope in that paradigm is that there are statistically significant differences to capture various phenomenon in natural language. However, consider the following (see this and this for a discussion on this example as it relates to the Winograd Schema Challenge):
- The trophy did not fit in the suitcase because it was too
1a. small
1b. big
Note that antonyms/opposites such as ‘small’ and ‘big’ (or ‘open’ and ‘close’, etc.) occur in the same contexts with equal probabilities. As such, (1a) and (1b) are statistically equivalent, yet even for a 4-year old (1a) and (1b) are considerably different: “it” in (1a) refers to “the suitcase” while in (1b) it refers to “the trophy”. Basically, and in simple language, (1a) and (1b) are statistically equivalent, although semantically far from it. Thus, statistical analysis cannot model (not even approximate) semantics — it is that simple!
One could argue that with enough examples a system could establish statistical significance. But how many examples would be needed to ‘learn’ how to resolve references in structures such as those in (1)?
In ML/Data-driven approaches there is no type hierarchy where we can make generalized statements about a ‘bag’, a ‘suitcase’, a ‘briefcase’ etc. where all are considered subtypes of the general type ‘container’. Thus, each one of the above, in a purely data-driven paradigm, are different and must be ‘seen’ separately in the data. If we add to the semantic differences all the minor syntactic differences to the above pattern (say changing ‘because’ to ‘although’ — which also changes the correct referent to “it”) then a rough calculation tells us a ML/Data-driven system would need to see something like 40,000,000 variations of the above to learn how to resolve references in sentences such as (2). If anything, this is computationally implausible. As Fodor and Pylyshyn once famously quoted the renowned cognitive scientist George Miller, to capture all syntactic and semantic variations that an NLU system would require, the number of features a neural network might need is more than the number of atoms in the universe! The moral here is this: statistics cannot capture (nor even approximate) semantics.
ML Approaches are not even Relevant to NLU: intenSion
Logicians have long studied a semantic notion that is called ‘intension’ (with an ‘s’). To explain what ‘intension’ is let us start with what is known as the meaning triangle, shown below with an example:
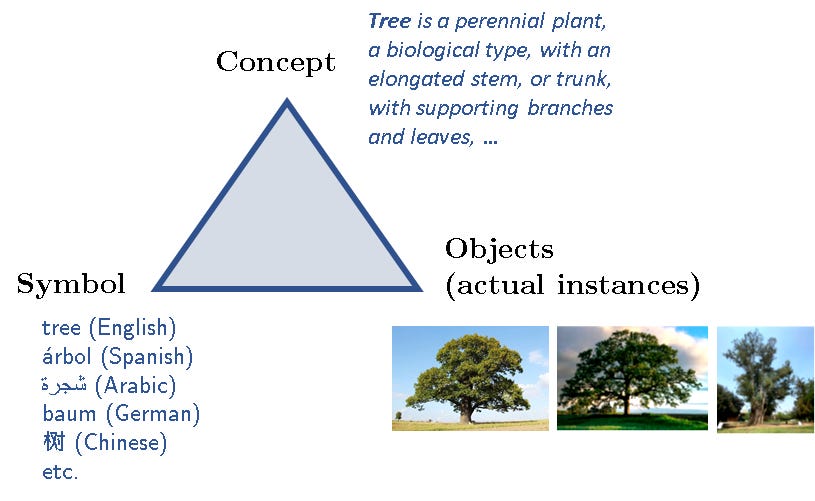
Thus every “thing” (or every object of cognition) has three parts: a symbol that refers to the concept, and the concept has (sometimes) actual instances. I say sometimes, because the concept “unicorn” has no “actual” instances, at least in the world we live in! The concept itself is an idealized template for all its potential instances (and thus it is close to the idealized Forms of Plato!) You can imagine how philosophers, logicians and cognitive scientists might have debated for centuries the nature of concepts and how they are defined. Regardless of that debate, we can agree on one thing: a concept (which is usually referred to by some symbol/label) is defined by a set of properties and attributes and perhaps with additional axioms and established facts, etc. Nevertheless, a concept is not the same as the actual (imperfect) instances. This is also true in the perfect world of mathematics. So, for example, while the arithmetic expressions below all have the same extension, they have different intensions:
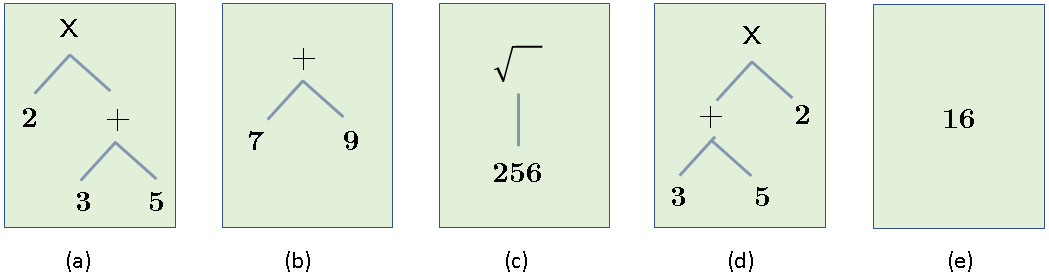
Thus, while all the expressions evaluate to 16, and thus are equal in one sense (their VALUE), this is only one of their attributes. In fact, the expressions above have several other attributes, such as their syntactic structure (that’s why (a) and (d) are different), number of operators, number of operands, etc. The VALUE (which is just one attribute) is called the extension, while the set of all the attributes is the intension. While in applied sciences (engineering, economics, etc.) we can safely consider these objects to be equal if they are equal in the VALUE attribute only, in cognition (and especially in language understanding) this equality fails! Here’s one simple example:
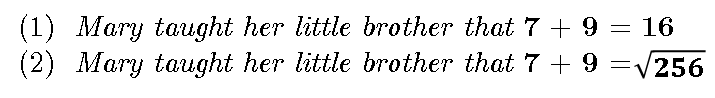
Suppose that (1) is true — that is, suppose (1) actually happened, and we saw it/witnessed it. Still, that does not mean we can assume (2) is true, although all we did was replace ‘16’ in (1) by a value that is (supposedly) equal to it. So what happened? We replaced one object in a true statement by an object that is supposedly equal to it, and we have inferred from something that is true something that is not! Well, what happened is this: while in physical sciences we can easily replace an object by one that is equal to it with one attribute, this does not work in cognition! Here’s another example that is perhaps more relevant to language:
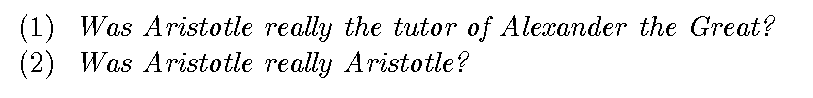
We obtained (2), which is obviously ridiculous, by simply replacing ‘the tutor of Alexander the Great’ by a value that is equal to it, namely Aristotle. Again, while ‘the tutor of Alexander the Great’ and ‘Aristotle’ are equal in one sense (they both have the same value as a referent), these two objects of thought are different in many other attributes. So, what is the point from this discussion on ‘intension’? Natural language is rampant with intensional phenomena, since objects of thoughts — that language conveys — have an intensional aspect that cannot be ignored. But all variants of the ML/Data-Driven approaches are purely extensional – they operate on numeric (vector/tensor) representations of objects and not their symbolic and structural properties and thus in this paradigm we cannot model various intensional phenomena in natural language. Incidentally, that fact that neural networks are purely extensional and thus cannot represent intensions is the real reason they will always be susceptible to adversarial attacks, although this issue is beyond the scope of this article.
Concluding Remarks
I have discussed in this article three reasons that proves Machine Learning and Data-Driven approaches are not even relevant to NLU (although these approaches might be used in some text processing tasks that are essentially compression tasks). Each of the above three reasons is enough on its own to put an end to this runaway train, and our suggestion is to stop the futile effort of trying to memorize language. In conveying our thoughts we transmit highly compressed linguistic utterances that need a mind to interpret and ‘uncover’ all the background information that was missing, but implicitly assumed.
Languages are the external artifacts that we use to encode the infinite number of thoughts that we might have. In so many ways, then, in building larger and larger language models, Machine Learning and Data-Driven approaches are trying to chase infinity in futile attempt at trying to find something that is not even ‘there’ in the data.
Ordinary spoken language, we must realize, is not just linguistic data.
Author Bio
Walid Saba is the Founder and Principal NLU scientist at ONTOLOGIK.AI and has previously worked at AIR, AT&T Bell Labs and IBM, among other places. He has also spent seven years in academia and has published over 40 articles including an award-wining paper that he presented in Germany in 2008. He holds a PhD in Computer Science which he obtained from Carleton University in 1999.
Citation
For attribution in academic contexts or books, please cite this work as
Walid Saba, "Machine Learning Won't Solve Natural Language Understanding", The Gradient, 2021.
BibTeX citation:
@article{saba2021nlu,
author = {Saba, Walid},
title = {Machine Learning Won't Solve Natural Language Understanding},
journal = {The Gradient},
year = {2021},
howpublished = {\url{https://thegradient.pub/machine-learning-wont-solve-the-natural-language-understanding-challenge/} },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.



{kind=link}
{kind=link}
{kind=link}
{kind=link}