Big changes are underway in the world of Natural Language Processing (NLP).
The long reign of word vectors as NLP’s core representation technique has seen an exciting new line of challengers emerge: ELMo[1], ULMFiT[2], and the OpenAI transformer[3]. These works made headlines by demonstrating that pretrained language models can be used to achieve state-of-the-art results on a wide range of NLP tasks. Such methods herald a watershed moment: they may have the same wide-ranging impact on NLP as pretrained ImageNet models had on computer vision.
From Shallow to Deep Pre-Training
Pretrained word vectors have brought NLP a long way. Proposed in 2013 as an approximation to language modeling, word2vec[4] found adoption through its efficiency and ease of use in a time when hardware was a lot slower and deep learning models were not widely supported. Since then, the standard way of conducting NLP projects has largely remained unchanged: word embeddings pretrained on large amounts of unlabeled data via algorithms such as word2vec and GloVe[5] are used to initialize the first layer of a neural network, the rest of which is then trained on data of a particular task. On most tasks with limited amounts of training data, this led to a boost of two to three percentage points[6]. Though these pretrained word embeddings have been immensely influential, they have a major limitation: they only incorporate previous knowledge in the first layer of the model---the rest of the network still needs to be trained from scratch.
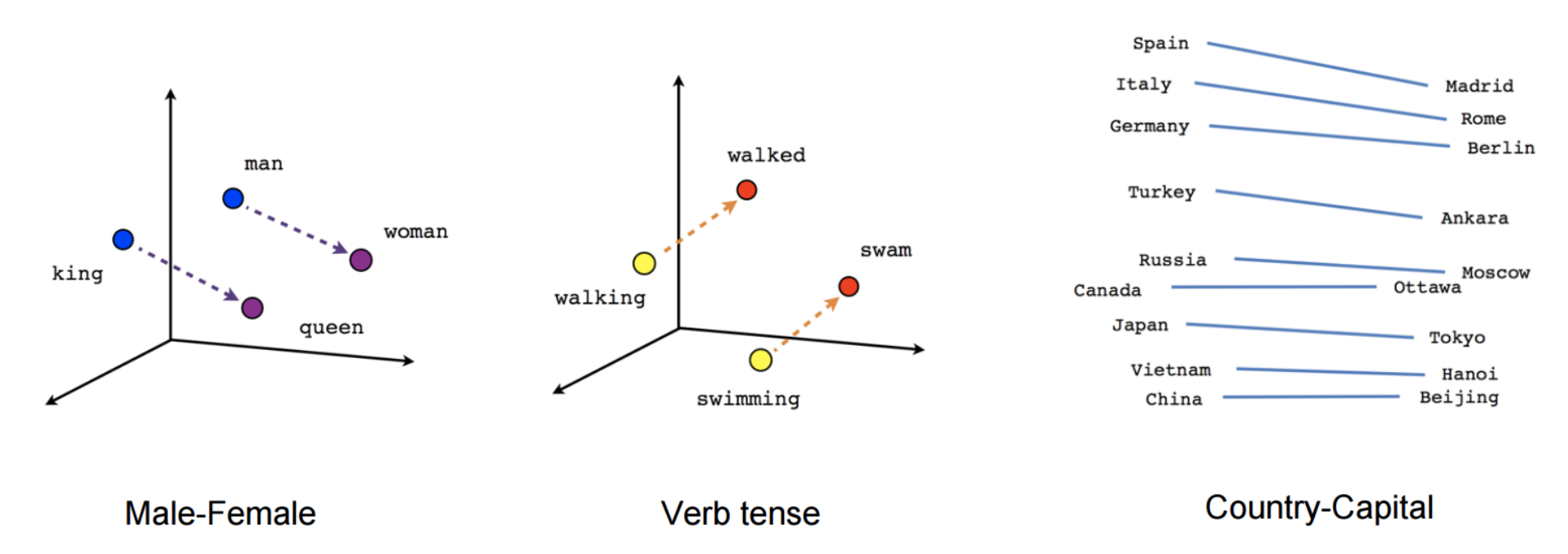
Word2vec and related methods are shallow approaches that trade expressivity for efficiency. Using word embeddings is like initializing a computer vision model with pretrained representations that only encode edges: they will be helpful for many tasks, but they fail to capture higher-level information that might be even more useful. A model initialized with word embeddings needs to learn from scratch not only to disambiguate words, but also to derive meaning from a sequence of words. This is the core aspect of language understanding, and it requires modeling complex language phenomena such as compositionality, polysemy, anaphora, long-term dependencies, agreement, negation, and many more. It should thus come as no surprise that NLP models initialized with these shallow representations still require a huge number of examples to achieve good performance.
At the core of the recent advances of ULMFiT, ELMo, and the OpenAI transformer is one key paradigm shift: going from just initializing the first layer of our models to pretraining the entire model with hierarchical representations. If learning word vectors is like only learning edges, these approaches are like learning the full hierarchy of features, from edges to shapes to high-level semantic concepts.
Interestingly, pretraining entire models to learn both low and high level features has been practiced for years by the computer vision (CV) community. Most often, this is done by learning to classify images on the large ImageNet dataset. ULMFiT, ELMo, and the OpenAI transformer have now brought the NLP community close to having an "ImageNet for language"---that is, a task that enables models to learn higher-level nuances of language, similarly to how ImageNet has enabled training of CV models that learn general-purpose features of images. In the rest of this piece, we’ll unpack just why these approaches seem so promising by extending and building on this analogy to ImageNet.
ImageNet

ImageNet’s impact on the course of machine learning research can hardly be overstated. The dataset was originally published in 2009 and quickly evolved into the ImageNet Large Scale Visual Recognition Challenge (ILSVRC). In 2012, the deep neural network[7] submitted by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton performed 41% better than the next best competitor, demonstrating that deep learning was a viable strategy for machine learning and arguably triggering the explosion of deep learning in ML research.
The success of ImageNet highlighted that in the era of deep learning, data was at least as important as algorithms. Not only did the ImageNet dataset enable that very important 2012 demonstration of the power of deep learning, but it also allowed a breakthrough of similar importance in transfer learning: researchers soon realized that the weights learned in state of the art models for ImageNet could be used to initialize models for completely other datasets and improve performance significantly. This "fine-tuning" approach allowed achieving good performance with as little as one positive example per category (Donahue et al., 2014)[8].
Pretrained ImageNet models have been used to achieve state-of-the-art results in tasks such as object detection[9], semantic segmentation[10], human pose estimation[11], and video recognition[12]. At the same time, they have enabled the application of CV to domains where the number of training examples is small and annotation is expensive. Transfer learning via pretraining on ImageNet is in fact so effective in CV that not using it is now considered foolhardy (Mahajan et al., 2018)[13].
What’s in an ImageNet?
In order to determine what an ImageNet for language might look like, we first have to identify what makes ImageNet good for transfer learning. Previous studies[14] have only shed partial light on this question: reducing the number of examples per class or the number of classes only results in a small performance drop, while fine-grained classes and more data are not always better.
Rather than looking at the data directly, it is more prudent to probe what the models trained on the data learn. It is common knowledge that features of deep neural networks trained on ImageNet transition from general to task-specific from the first to the last layer[15]: lower layers learn to model low-level features such as edges, while higher layers model higher-level concepts such as patterns and entire parts or objects[16] as can be seen in the figure below. Importantly, knowledge of edges, structures, and the visual composition of objects is relevant for many CV tasks, which sheds light on why these layers are transferred. A key property of an ImageNet-like dataset is thus to encourage a model to learn features that will likely generalize to new tasks in the problem domain.

Beyond this, it is difficult to make further generalizations about why transfer from ImageNet works quite so well. For instance, another possible advantage of the ImageNet dataset is the quality of the data. ImageNet’s creators went to great lengths to ensure reliable and consistent annotations. However, work in distant supervision serves as a counterpoint, indicating that large amounts of weakly labelled data might often be sufficient. In fact, recently researchers at Facebook showed that they could pre-train a model by predicting hashtags on billions of social media images to state-of-the-art accuracy on ImageNet.
Without any more concrete insights, we are left with two key desiderata:
-
An ImageNet-like dataset should be sufficiently large, i.e. on the order of millions of training examples.
-
It should be representative of the problem space of the discipline.
An ImageNet for language
In NLP, models are typically a lot shallower than their CV counterparts. Analysis of features has thus mostly focused on the first embedding layer, and little work has investigated the properties of higher layers for transfer learning. Let us consider the datasets that are large enough, fulfilling desideratum #1. Given the current state of NLP, there are several contenders[17].
Reading comprehension is the task of answering a natural language question about a paragraph. The most popular dataset for this task is the Stanford Question Answering Dataset (SQuAD)[18], which contains more than 100,000 question-answer pairs and asks models to answer a question by highlighting a span in the paragraph as can be seen below.

Natural language inference is the task of identifying the relation (entailment, contradiction, and neutral) that holds between a piece of text and a hypothesis. The most popular dataset for this task, the Stanford Natural Language Inference (SNLI) Corpus[19], contains 570k human-written English sentence pairs. Examples of the dataset can be seen below.

Machine translation, translating text in one language to text in another language, is one of the most studied tasks in NLP, and---over the years---has accumulated vast amounts of training data for popular language pairs, e.g. 40M English-French sentence pairs in WMT 2014. See below for two example translation pairs.

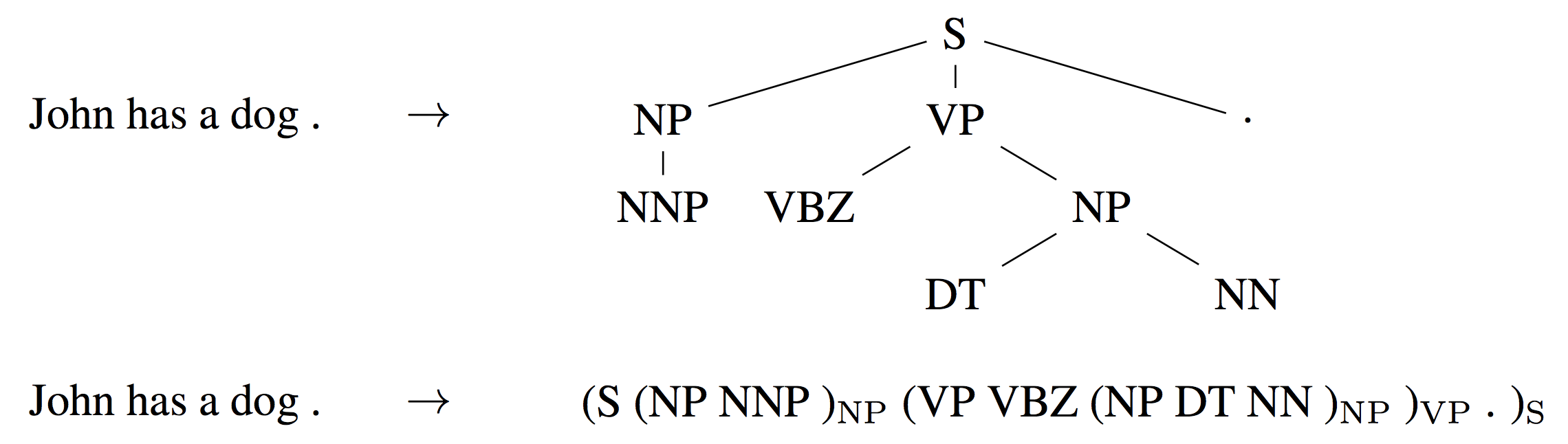
Constituency parsing seeks to extract the syntactic structure of a sentence in the form of a (linearized) constituency parse tree as can be seen below. In the past, millions of weakly labelled parses[20] have been used for training sequence-to-sequence models for this task.
Language modeling (LM) aims to predict the next word given its previous word. Existing benchmark datasets consist of up to 1B words, but as the task is unsupervised, any number of words can be used for training. See below for examples from the popular WikiText-2 dataset consisting of Wikipedia articles.

All of these tasks provide---or would allow the collection of---a sufficient number of examples for training. Indeed, the[21] above[22] tasks[23] (and many others such as sentiment analysis[24], constituency parsing [20:1], skip-thoughts[25], and autoencoding[26]) have been used to pretrain representations in recent months.
While any data contains some bias[27], human annotators may inadvertently introduce additional signals that a model can exploit. Recent[28] studies[29] reveal that state-of-the-art models for tasks such as reading comprehension and natural language inference do not in fact exhibit deep natural language understanding but pick up on such cues to perform superficial pattern matching. For instance, Gururangan et al. (2018)[29:1] show that annotators tend to produce entailment examples simply by removing gender or number information and generate contradictions by introducing negations. A model that simply exploits these cues can correctly classify the hypothesis without looking at the premise in about 67% of the SNLI dataset.
The more difficult question thus is: Which task is most representative of the space of NLP problems? In other words, which task allows us to learn most of the knowledge or relations required for understanding natural language?
The case for language modelling
In order to predict the most probable next word in a sentence, a model is required not only to be able to express syntax (the grammatical form of the predicted word must match its modifier or verb) but also model semantics. Even more, the most accurate models must incorporate what could be considered world knowledge or common sense. Consider the incomplete sentence "The service was poor, but the food was". In order to predict the succeeding word such as “yummy” or “delicious”, the model must not only memorize what attributes are used to describe food, but also be able to identify that the conjunction “but” introduces a contrast, so that the new attribute has the opposing sentiment of “poor”.
Language modelling, the last approach mentioned, has been shown to capture many facets of language relevant for downstream tasks, such as long-term dependencies[30], hierarchical relations[31], and sentiment[32]. Compared to related unsupervised tasks such as skip-thoughts and autoencoding, language modelling performs better on syntactic tasks even with less training data.
Among the biggest benefits of language modelling is that training data comes for free with any text corpus and that potentially unlimited amounts of training data are available. This is particularly significant, as NLP deals not only with the English language. More than 4,500 languages are spoken around the world by more than 1,000 speakers. Language modeling as a pretraining task opens the door to developing models for previously underserved languages. For very low-resource languages where even unlabeled data is scarce, multilingual language models may be trained on multiple related languages at once, analogous to work on cross-lingual embeddings[33].
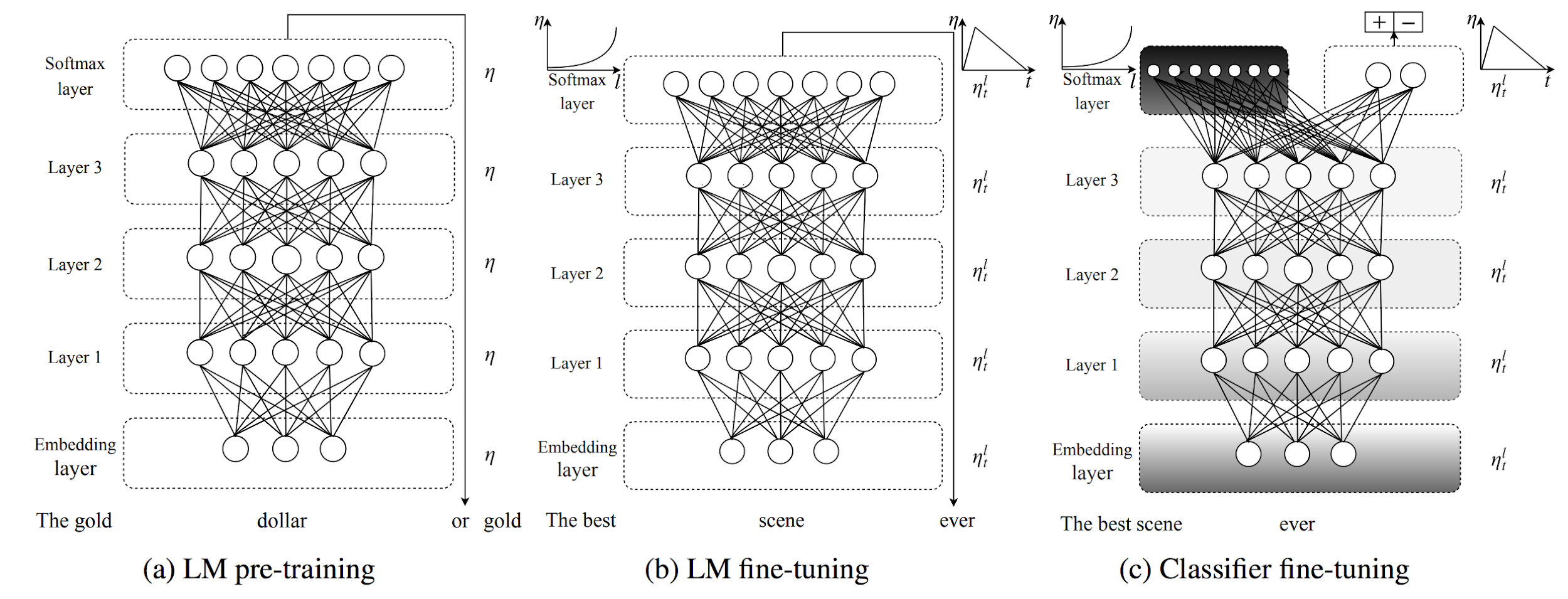
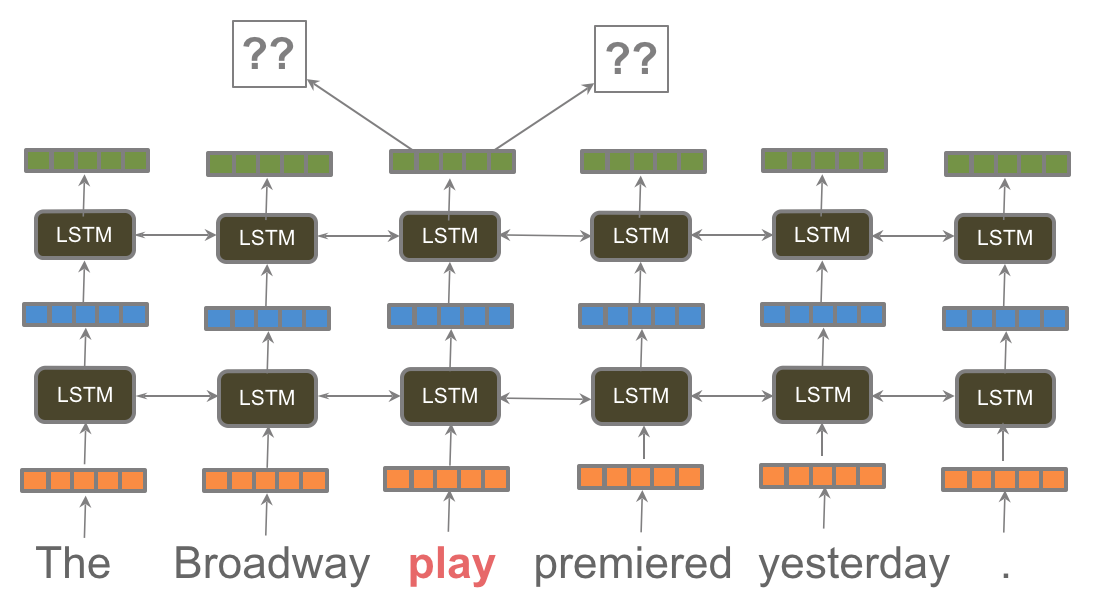
So far, our argument for language modeling as a pretraining task has been purely conceptual. Pretraining a language model was first proposed in 2015[34], but it remained unclear whether a single pretrained language model was useful for many tasks. In recent months, we finally obtained overwhelming empirical proof: Embeddings from Language Models (ELMo), Universal Language Model Fine-tuning (ULMFiT), and the OpenAI Transformer have empirically demonstrated how language modeling can be used for pretraining, as shown by the above figure from ULMFiT. All three methods employed pretrained language models to achieve state-of-the-art on a diverse range of tasks in Natural Language Processing, including text classification, question answering, natural language inference, coreference resolution, sequence labeling, and many others.
In many cases such as with ELMo in the figure below, these improvements ranged between 10-20% better than the state-of-the-art on widely studied benchmarks, all with the single core method of leveraging a pretrained language model. ELMo furthermore won the best paper award at NAACL-HLT 2018, one of the top conferences in the field. Finally, these models have been shown to be extremely sample-efficient, achieving good performance with only hundreds of examples and are even able to perform zero-shot learning.
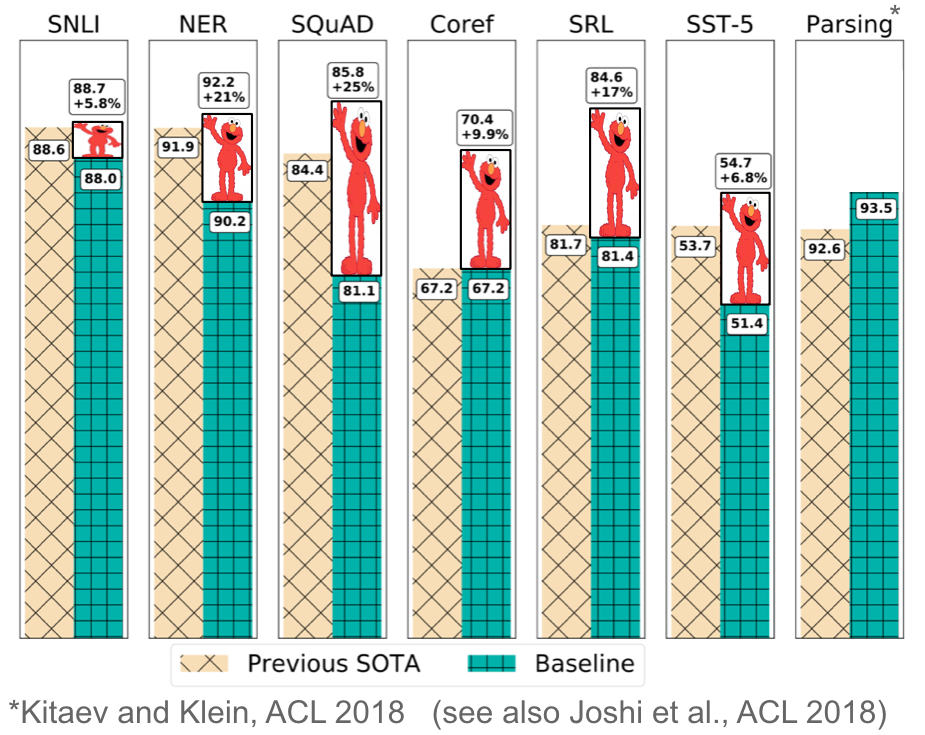
In light of this step change, it is very likely that in a year’s time NLP practitioners will download pretrained language models rather than pretrained word embeddings for use in their own models, similarly to how pre-trained ImageNet models are the starting point for most CV projects nowadays.
However, similar to word2vec, the task of language modeling naturally has its own limitations: It is only a proxy to true language understanding, and a single monolithic model is ill-equipped to capture the required information for certain downstream tasks. For instance, in order to answer questions about or follow the trajectory of characters in a story, a model needs to learn to perform anaphora or coreference resolution. In addition, language models can only capture what they have seen. Certain types of information, such as most common sense knowledge, are difficult to learn from text alone[35] and require incorporating external information.
One outstanding question is how to transfer the information from a pre-trained language model to a downstream task. The two main paradigms for this are whether to use the pre-trained language model as a fixed feature extractor and incorporate its representation as features into a randomly initialized model as used in ELMo, or whether to fine-tune the entire language model as done by ULMFiT. The latter fine-tuning approach is what is typically done in CV where either the top-most or several of the top layers are fine-tuned. While NLP models are typically more shallow and thus require different fine-tuning techniques than their vision counterparts, recent pretrained models are getting deeper. The next months will show the impact of each of the core components of transfer learning for NLP: an expressive language model encoder such as a deep BiLSTM or the Transformer, the amount and nature of the data used for pretraining, and the method used to fine-tune the pretrained model.
But where’s the theory?
Our analysis thus far has been mostly conceptual and empirical, as it is still poorly understood why models trained on ImageNet---and consequently on language modeling---transfer so well. One way to think about the generalization behaviour of pretrained models more formally is under a model of bias learning (Baxter, 2000)[36]. Assume our problem domain covers all permutations of tasks in a particular discipline, e.g. computer vision, which forms our environment. We are provided with a number of datasets that allow us to induce a family of hypothesis spaces $\mathrm{H} = {\mathcal{H}}$. Our goal in bias learning is to find a bias, i.e. a hypothesis space $\mathcal{H} \in \mathrm{H}$ that maximizes performance on the entire (potentially infinite) environment.
Empirical and theoretical results in multi-task learning (Caruana, 1997; Baxter, 2000)[36:1][37] indicate that a bias that is learned on sufficiently many tasks is likely to generalize to unseen tasks drawn from the same environment. Viewed through the lens of multi-task learning, a model trained on ImageNet learns a large number of binary classification tasks (one for each class). These tasks, all drawn from the space of natural, real-world images, are likely to be representative of many other CV tasks. In the same vein, a language model---by learning a large number of classification tasks, one for each word---induces representations that are likely helpful for many other tasks in the realm of natural language. Still, much more research is necessary to gain a better theoretical understanding why language modeling seems to work so well for transfer learning.
The ImageNet moment
The time is ripe for practical transfer learning to make inroads into NLP. In light of the impressive empirical results of ELMo, ULMFiT, and OpenAI it only seems to be a question of time until pretrained word embeddings will be dethroned and replaced by pretrained language models in the toolbox of every NLP practitioner. This will likely open many new applications for NLP in settings with limited amounts of labeled data. The king is dead, long live the king!
Sebastian Ruder is a final year PhD Student in natural language processing and deep learning at the Insight Research Centre for Data Analytics and a research scientist at Dublin-based NLP startup AYLIEN. His main interests are transfer learning for NLP and making ML more accessible. He has published first-author papers in top NLP conferences and is a co-author of ULMFiT. You can find him at his website or on Twitter.
Cover image due to Matthew Peters.
Citation
For attribution in academic contexts or books, please cite this work as
Sebastian Ruder, "NLP's ImageNet moment has arrived", The Gradient, 2018.
BibTeX citation:
@article{ruder2018nlpimagenet,
author = {Ruder, Sebastian}
title = {NLP's ImageNet moment has arrived},
journal = {The Gradient},
year = {2018},
howpublished = {\url{https://thegradient.pub/nlp-imagenet/ } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.
Peters, Matthew E., et al. "Deep contextualized word representations." Proceedings of NAACL-HLT (2018). ↩︎
Howard, Jeremy, and Sebastian Ruder. "Fine-tuned Language Models for Text Classification." Proceedings of ACL (2018). ↩︎
Radford, Alec, et al. "Improving Language Understanding by Generative Pre-Training." ↩︎
Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Advances in neural information processing systems. 2013. ↩︎
Pennington, Jeffrey, Richard Socher, and Christopher Manning. "Glove: Global vectors for word representation." Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014. ↩︎
Kim, Yoon. "Convolutional neural networks for sentence classification." Proceedings of EMNLP (2014). ↩︎
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems. 2012. ↩︎
Donahue, Jeff, et al. "Decaf: A deep convolutional activation feature for generic visual recognition." International conference on machine learning. 2014. ↩︎
He, Kaiming, et al. "Mask r-cnn." Computer Vision (ICCV), 2017 IEEE International Conference on. IEEE, 2017. ↩︎
Zhao, Hengshuang, et al. "Pyramid scene parsing network." IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). 2017. ↩︎
Papandreou, George, et al. "Towards accurate multi-person pose estimation in the wild." CVPR. Vol. 3. No. 4. 2017. ↩︎
Carreira, Joao, and Andrew Zisserman. "Quo vadis, action recognition? a new model and the kinetics dataset." Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on. IEEE, 2017. ↩︎
Mahajan, Dhruv, et al. "Exploring the Limits of Weakly Supervised Pretraining." arXiv preprint arXiv:1805.00932 (2018). ↩︎
Huh, Minyoung, Pulkit Agrawal, and Alexei A. Efros. "What makes ImageNet good for transfer learning?." arXiv preprint arXiv:1608.08614 (2016). ↩︎
Yosinski, Jason, et al. "How transferable are features in deep neural networks?." Advances in neural information processing systems. 2014. ↩︎
Olah, Chris, Alexander Mordvintsev, and Ludwig Schubert. "Feature visualization." Distill 2.11 (2017): e7. ↩︎
For a comprehensive overview of progress in NLP tasks, you can refer to this GitHub repository. ↩︎
Rajpurkar, Pranav, et al. "Squad: 100,000+ questions for machine comprehension of text." Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP, 2016). ↩︎
Bowman, Samuel R., et al. "A large annotated corpus for learning natural language inference." Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP, 2015). ↩︎
Vinyals, Oriol, et al. "Grammar as a foreign language." Advances in Neural Information Processing Systems. 2015. ↩︎ ↩︎
Conneau, Alexis, et al. "Supervised learning of universal sentence representations from natural language inference data." Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP, 2017). ↩︎
Subramanian, Sandeep, et al. "Learning general purpose distributed sentence representations via large scale multi-task learning." Proceedings of the International Conference on Learning Representations, ICLR (2018). ↩︎
McCann, Bryan, et al. "Learned in translation: Contextualized word vectors." Advances in Neural Information Processing Systems. 2017. ↩︎
Felbo, Bjarke, et al. "Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm." Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP, 2017). ↩︎
Kiros, Ryan, et al. "Skip-thought vectors." Advances in neural information processing systems. 2015. ↩︎
Dai, Andrew M., and Quoc V. Le. "Semi-supervised sequence learning." Advances in neural information processing systems. 2015. ↩︎
Bolukbasi, Tolga, et al. "Man is to computer programmer as woman is to homemaker? debiasing word embeddings." Advances in Neural Information Processing Systems. 2016. ↩︎
Chen, Danqi, Jason Bolton, and Christopher D. Manning. "A thorough examination of the cnn/daily mail reading comprehension task." Proceedings of the Meeting of the Association for Computational Linguistics (2016). ↩︎
Gururangan, Suchin, et al. "Annotation artifacts in natural language inference data." Proceedings of NAACL-HLT (2018). ↩︎ ↩︎
Linzen, T., Dupoux, E., & Goldberg, Y. (2016). Assessing the Ability of LSTMs to Learn Syntax-Sensitive Dependencies. Proceedings of TACL 2016. ↩︎
Gulordava, K., Bojanowski, P., Grave, E., Linzen, T., & Baroni, M. (2018). Colorless green recurrent networks dream hierarchically. In Proceedings of NAACL-HLT 2018. ↩︎
Radford, A., Jozefowicz, R., & Sutskever, I. (2017). Learning to Generate Reviews and Discovering Sentiment. arXiv preprint arXiv:1704.01444. ↩︎
Ruder, Sebastian, Ivan Vulic, and Anders Søgaard. "A Survey of Cross-lingual Word Embedding Models." Journal of Artificial Intelligence Research (2018). ↩︎
Dai, Andrew M., and Quoc V. Le. "Semi-supervised sequence learning." Advances in neural information processing systems. 2015. ↩︎
Lucy, Li, and Jon Gauthier. "Are distributional representations ready for the real world? Evaluating word vectors for grounded perceptual meaning." Proceedings of the First Workshop on Language Grounding for Robotics (2017). ↩︎
Jonathan Baxter. 2000. A Model of Inductive Bias Learning. Journal of Artificial Intelligence Research 12:149–198. ↩︎ ↩︎
Rich Caruana. 1993. Multitask learning: A knowledge-based source of inductive bias. In Proceedings of the Tenth International Conference on Machine Learning. ↩︎



{kind=link}
{kind=link}
{kind=link}
{kind=link}