
Will Artificial Intelligence soon replace radiologists? Recently, researchers trained a deep neural network to classify breast cancer, achieving a performance of 85%. When used in combination with three other neural network models, the resulting ensemble method reached an outstanding 99% classification accuracy, rivaling expert radiologists with years of training.
The result described above is true, with one little twist: instead of using state-of-the-art artificial deep neural networks, researchers trained “natural” neural networks - more precisely, a flock of four pigeons - to diagnose breast cancer.
Somehow surprisingly, however, pigeons were never regarded as the future of medical imaging and major companies have yet to invest billions in the creation of large-scale pigeon farms: Our expectations for pigeons somehow pale in comparison to our expectations for deep neural networks (DNNs).
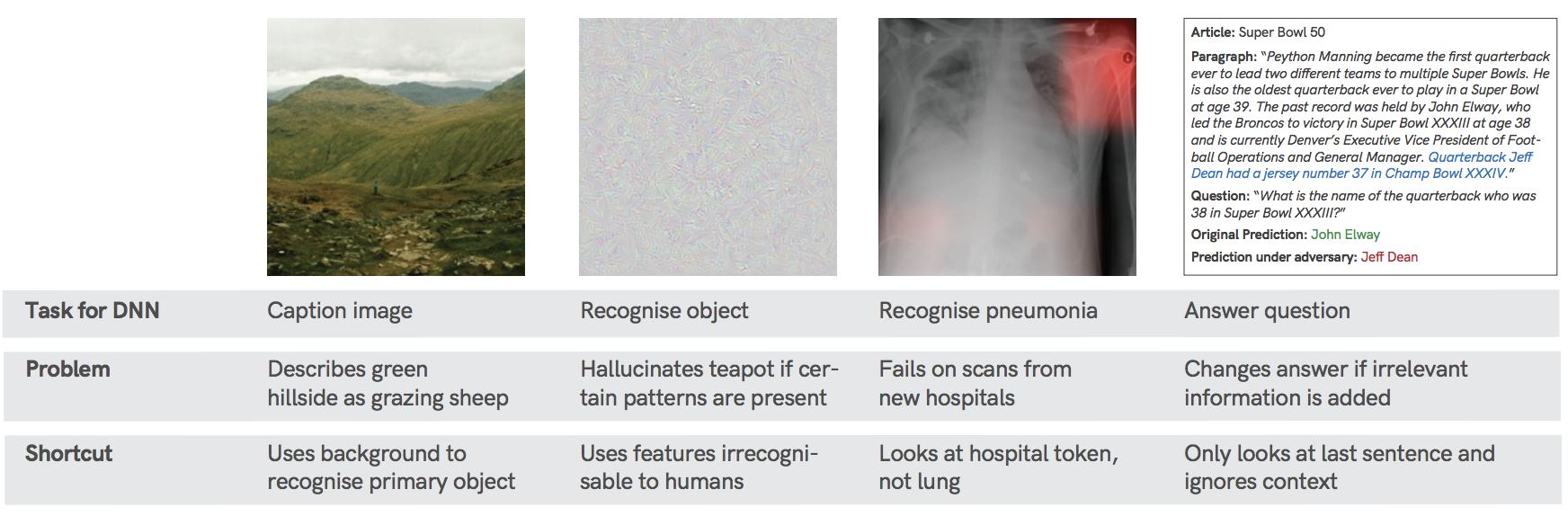
And in many ways, DNNs have indeed lived up to the hypes and the hopes: their success story across society, industry and science is undeniable, and new breakthroughs still happen in a matter of months, sometimes weeks. Slowly but steadily, however, seemingly disconnected failure cases have been accumulating: DNNs achieve superhuman performance in recognizing objects, but even small invisible changes or a different background context can completely derail predictions. DNNs can generate a plausible caption for an image, but—worryingly—they can do so without really looking at that image. DNNs can accurately recognize faces, but they show high error rates for faces from minority groups. DNNs can predict hiring decisions on the basis of résumés, but the algorithm’s decisions are biased towards selecting men.
How can this discrepancy between super-human performance on one hand and astonishing failures on the other hand be reconciled? As we argue in the paper “Shortcut Learning in Deep Neural Networks” and elaborate in this piece, we believe that many failure cases are not independent phenomena, but are instead connected in the sense that DNNs follow unintended “shortcut” strategies. While superficially successful, these strategies typically fail under slightly different circumstances.
Shortcuts are decision rules that perform well on standard benchmarks but fail to transfer to more challenging testing conditions. Shortcut opportunities come in many flavors and are ubiquitous across datasets and application domains. A few examples are visualized here:
At a principal level, shortcut learning is not a novel phenomenon: variants are known under different terms such as “learning under covariate shift”, “anti-causal learning”, “dataset bias”, the “tank legend” and the “Clever Hans effect”. We here discuss how shortcut learning unifies many of deep learning’s problems and what we can do to better understand and mitigate shortcut learning.
What is a shortcut?
In machine learning, the solutions that a model can learn are constrained by data, model architecture, optimizer and objective function. However, these constraints often don’t just allow for one single solution: there are typically many different ways to solve a problem. Shortcuts are solutions that perform well on a typical test set but fail under different circumstances, revealing a mismatch with our intentions.
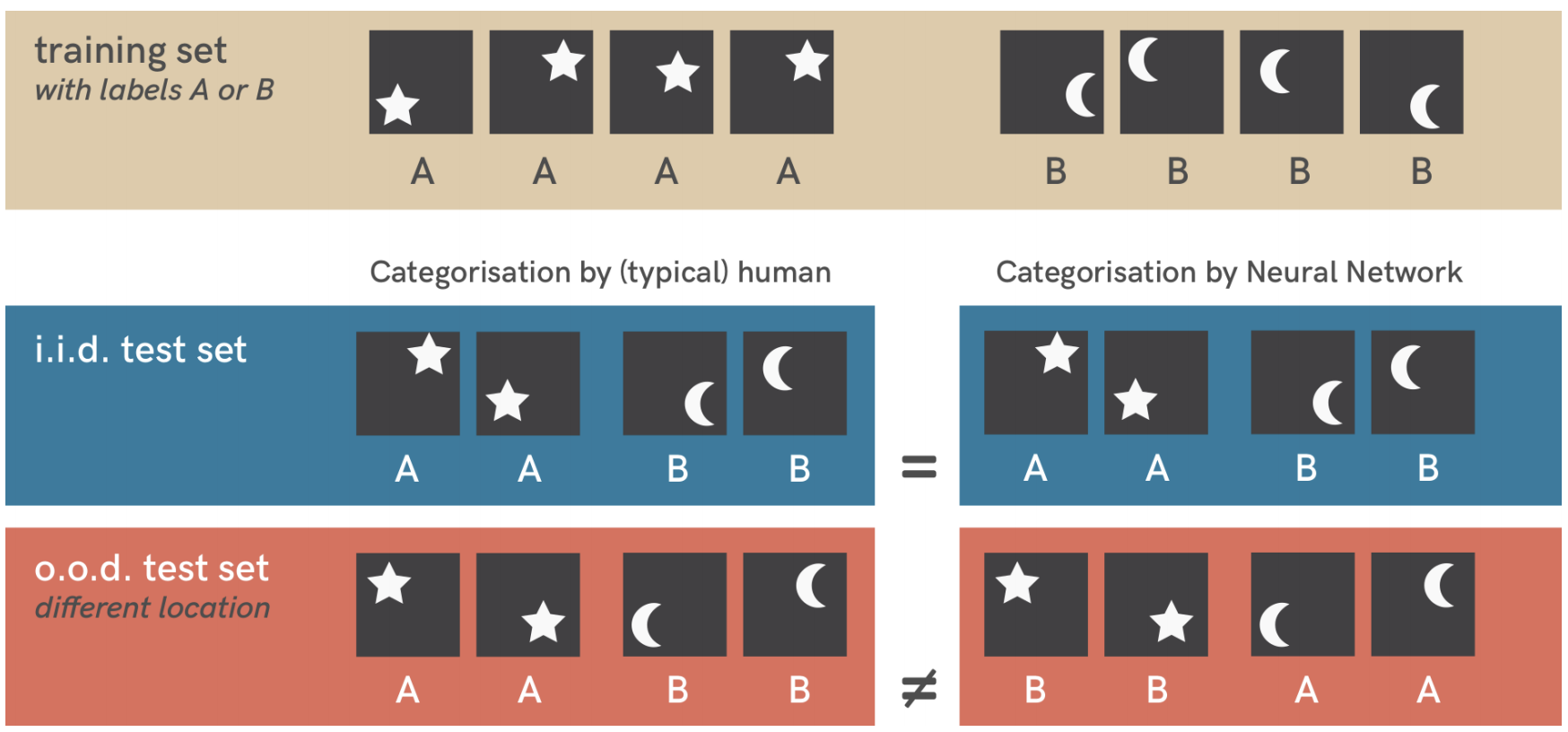
To give an example, when trained on a simple dataset of stars and moons (top row), a standard neural network (three layers, fully connected) can easily categorise novel similar examples (mathematically termed i.i.d. test set). However, testing it on a slightly different dataset (o.o.d. test set, bottom row) reveals a shortcut strategy: The network has learned to associate object location with a category. During training, stars were always shown in the top right or bottom left of an image; moons in the top left or bottom right. This pattern is still present in samples from the i.i.d. test set (middle row) but not in o.o.d. test images (bottom row), exposing the shortcut. The most important insight here is that both location and shape are valid solutions under the training setup constraints, so there is no reason to expect the neural network to prefer one over the other. Humans however have a strong intuition to use objects shape. As contrived as this example may seem, adversarial examples, biased machine learning models, lack of domain generalization, and failures on slightly changed inputs can all be understood as instances of the same underlying phenomenon: shortcut learning.
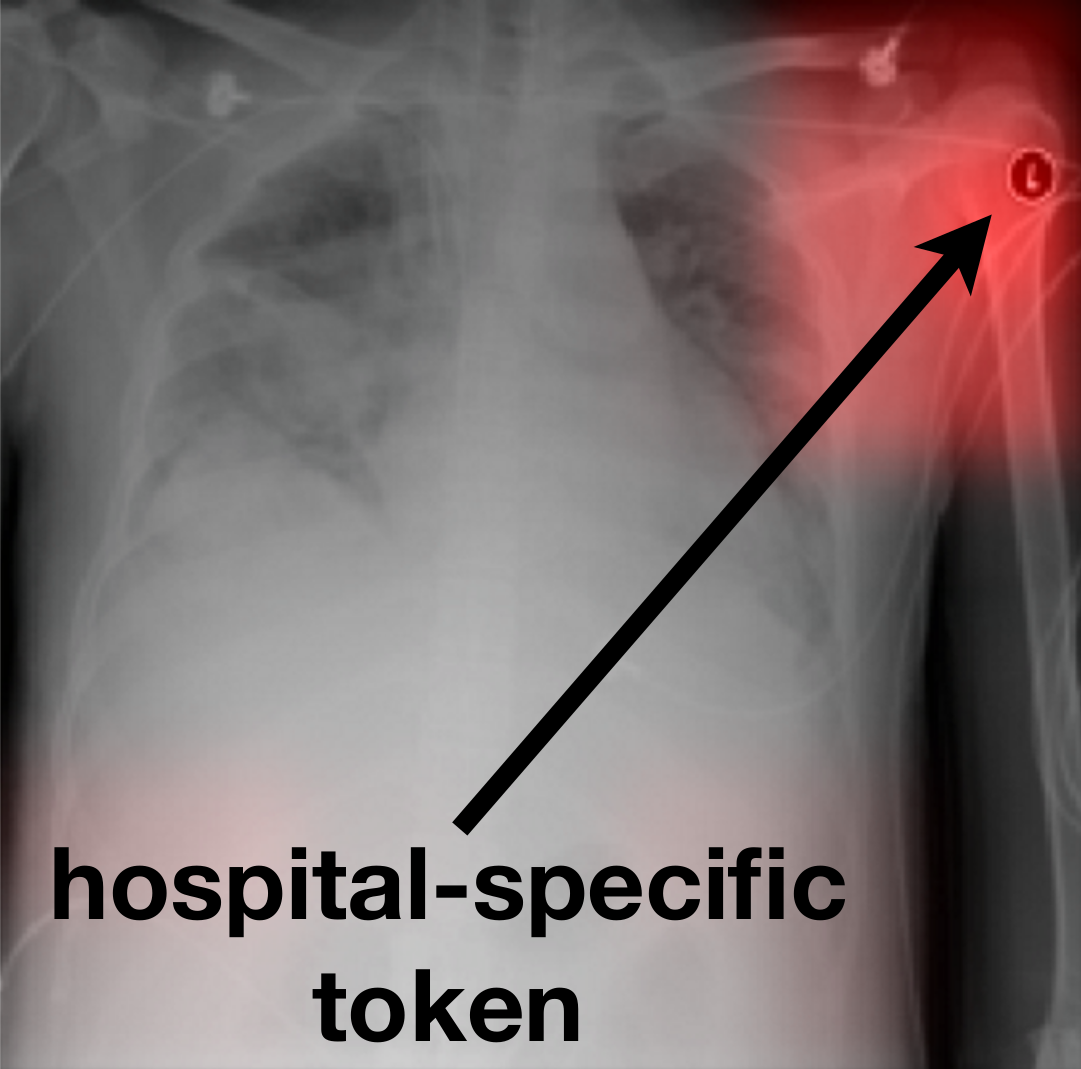
For example, researchers developed a machine classifier able to successfully detected pneumonia from X-ray scans of a number of hospitals, but its performance was surprisingly low for scans from novel hospitals: the model had unexpectedly learned to identify particular hospital systems with near-perfect accuracy (e.g. by detecting a hospital-specific metal token on the scan, see left). Together with the hospital's pneumonia prevalence rate it was able to achieve a reasonably good prediction during training - without learning much about pneumonia at all. Instead of learning to “understand” pneumonia, the classifier chose the easiest solution and only looked at token types.
Shortcut learning beyond deep learning
Often such failures serve as examples for why machine learning algorithms are untrustworthy. However, biological learners suffer from very similar failure modes as well. In an experiment in a lab at the University of Oxford, researchers observed that rats learned to navigate a complex maze apparently based on subtle colour differences - very surprising given that the rat retina has only rudimentary machinery to support at best somewhat crude colour vision. Intensive investigation into this curious finding revealed that the rats had tricked the researchers: They did not use their visual system at all in the experiment and instead simply discriminated the colours by the odour of the colour paint used on the walls of the maze. Once smell was controlled for, the remarkable colour discrimination ability disappeared.
Animals often trick experimenters by solving an experimental paradigm (i.e., dataset) in an unintended way without using the underlying ability one is actually interested in. This highlights how incredibly difficult it can be for humans to imagine solving a tough challenge in any other way than the human way: Surely, at Marr’s implementational level there may be differences between rat and human colour discrimination. But at the algorithmic level there is often a tacit assumption that human-like performance implies human-like strategy (or algorithm). This “same strategy assumption” is paralleled by deep learning: even if DNN units are different from biological neurons, if DNNs successfully recognise objects it seems natural to assume that they are using object shape like humans do. As a consequence, we need to distinguish between performance on a dataset and acquiring an ability, and exercise great care before attributing high-level abilities like “object recognition” or “language understanding” to machines, since there is often a much simpler explanation:
Never attribute to high-level abilities that which can be adequately explained by shortcut learning.
Shortcut learning requires changes in the way we measure progress
Historically, machine learning research is strongly driven by benchmarks that make algorithms comparable by evaluating them on fixed combinations of tasks and datasets. This model has led the field to enormous progress within very short timespans. But it is not without drawbacks. One effect is that it creates strong incentives for researchers to focus more on the development of novel algorithms that improve upon existing benchmarks rather than understanding their algorithms or the benchmarks. This neglect of understanding is part of the reason why shortcut learning has become such a widespread problem within deep learning.
Let’s look at a prominent example: The ImageNet dataset and challenge were created in 2009 as a new way of measuring progress in object recognition, the ability of algorithms to identify and classify objects. Due to its enormous size ImageNet presented itself as an unsolved problem on a scale that nobody dared to tackle before. It was its variety and scale that paved the way for the current deep learning revolution. With their 2012 paper and challenge contribution Krizhevsky et. al. demonstrated that deep neural networks with learned weights were uniquely adapted to handle this complexity (in contrast to the prevalent methods of that time that used handcrafted features for image analysis). In the following few years, ImageNet became a driving force for progress and performance on the ImageNet benchmark synonymous with progress in computer vision.
Only in the last few years this slowly started to change when more and more failure cases of DNNs emerged. One main reason behind all these failure cases is that despite its scale and variety ImageNet does not require true object recognition, in the sense that the models have to correctly identify and classify the foreground object we use as a label. Instead in many cases objects can be equally well identified by their background, their texture or some other shortcut less obvious to humans. If it is easier to identify the background than the main object in the scene the network will often learn to exploit this for classification.
The consequences of this behaviour are striking failures in generalization. Have a look at the figure below. On the left side there are a few directions in which humans would expect a model to generalize. A five is a five whether it is hand-drawn and black and white or a house number photographed in color. Similarly slight distortions or changes in pose, texture or background don’t influence our prediction about the main object in the image. In contrast a DNN can easily be fooled by all of them. Interestingly this does not mean that DNNs can’t generalize at all: In fact, they generalize perfectly well albeit in directions that hardly make sense to humans. The right side of the figure below shows some examples that range from the somewhat comprehensible - scrambling the image to keep only its texture - to the completely incomprehensible.

The key problem that leads to shortcut learning and the subsequent generalization failures is the discrepancy between our perception of a task and what it actually incentivises models to learn. How can we mitigate this issue and provide insight into shortcut learning? A central shortcoming of most current benchmarks is that they test on images from the same data distribution that is used during training (i.i.d. testing). This type of evaluation requires only a weak form of generalization. What we however want are strong generalization capabilities that are roughly aligned with our intuition. To test these we need good out-of-distribution tests (o.o.d. tests) that have a clear distribution shift, a well-defined intended solution and expose where models learn a shortcut.
But it doesn’t stop there: as models get better and better they will learn to exploit ever subtler shortcuts, so we envision o.o.d. benchmarks to evolve as well over time towards stronger and stronger tests. This type of “rolling benchmark” could ensure that we don’t lose track of our original goals during model development but constantly refocus our efforts to solve the underlying problems we actually care about, while increasing our understanding of the interplay between the modeling pipeline and shortcut learning.
Favoring the Road to Understanding over Shortcuts, but how?
Science aims for understanding. While deep learning as an engineering discipline has seen tremendous progress over the last few years, deep learning as a scientific discipline is still lagging behind in terms of understanding the principles and limitations that govern how machines learn to extract patterns from data. A deeper understanding of how to mitigate shortcut learning is of relevance beyond the current application domains of machine learning and there might be interesting future opportunities for cross-fertilisation with other disciplines such as Economics (designing management incentives that do not jeopardise long-term success by rewarding unintended “shortcut” behaviour) or Law (creating laws without “loophole” shortcut opportunities). However, it is important to point out that we will likely never fully solve shortcut learning. Models always base their decisions on reduced information and thus generalization failures should be expected: Failures through shortcut learning are the norm, not the exception. To increase our understanding of shortcut learning and potentially even mitigate instances of it, we offer the following five recommendations:
(1) Connecting the dots: shortcut learning is ubiquitous
Shortcut learning appears to be a ubiquitous characteristic of learning systems, biological and artificial alike. Many of deep learning's problems are connected through shortcut learning - models exploit dataset shortcut opportunities, select only a few predictive features instead of carefully considering all available evidence, and consequently suffer from unexpected generalization failures. “Connecting the dots” between affected areas is likely to facilitate progress, and making progress can generate highly valuable impact across various application domains.
(2) Interpreting results carefully
Discovering a shortcut often reveals the existence of an easy solution to a seemingly complex dataset. We argue that we will need to exercise great care before attributing high-level abilities like “object recognition” or “language understanding” to machines, since there is often a much simpler explanation.
(3) Testing o.o.d. generalization
Assessing model performance on i.i.d. test data (as the majority of current benchmarks do) is insufficient to distinguish between intended and unintended (shortcut) solutions. Consequently, o.o.d. generalization tests will need to become the rule rather than the exception.
(4) Understanding what makes a solution easy to learn
DNNs always learn the easiest possible solution to a problem, but understanding which solutions are easy (and thus likely to be learned) requires disentangling the influence of structure (architecture), experience (training data), goal (loss function) and learning (optimisation), as well as a thorough understanding of the interactions between these factors.
(5) Asking whether a task should be solved in the first place
The existence of shortcuts implies that DNNs will often find solutions no matter whether the task is well-substantiated. For instance, they might try to find a shortcut to assess credit-scores from sensitive demographics (e.g. skin color or ethnicity) or gender from superficial appearance. This is concerning as it may reinforce incorrect assumptions and problematic power relations when applying machine learning to ill-defined or harmful tasks. Shortcuts can make such questionable tasks appear perfectly solvable. However, the ability of DNNs to tackle a task or benchmark with high performance can never justify the task's existence or underlying assumptions. Thus, when assessing whether a task is solvable, we first need to ask: should it be solved? And if so, should it be solved by AI?
Shortcut learning accounts for some of the most iconic differences between current ML models and human intelligence - but ironically, it is exactly this preference for “cheating” that can make neural networks seem almost human: Who has never cut corners by memorizing exam material, instead of investing time to truly understand? Who has never tried to find a loophole in a regulation, instead of adhering to its spirit? In the end, neural networks perhaps aren’t that different from (lazy) humans after all ...
This perspective is based on the following paper:
Geirhos, R., Jacobsen, J. H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., & Wichmann, F. A. (2020). Shortcut Learning in Deep Neural Networks. arXiv preprint arXiv:2004.07780.
Author Bio
Dr. Jörn-Henrik Jacobsen has conducted the research this article is based on as a PostDoc at the Vector Institute and University of Toronto. Previously he was a PostDoc at the University of Tübingen and did his PhD at the University of Amsterdam. His research is broadly concerned with what it means to learn useful and general representations of the world, with particular focus on out-of-distribution generalization, unsupervised representation learning, stability guarantees and algorithmic bias.
Robert Geirhos is a PhD student at the International Max Planck Research School for Intelligent Systems, Germany. His PhD project is jointly advised by Felix Wichmann (Neural Information Processing) and Matthias Bethge (Computational Vision and Neuroscience). He received a M.Sc. in Computer Science with distinction and a B.Sc. in Cognitive Science from the University of Tübingen, and has been fascinated by the intersection of human and computer vision ever since.
Claudio Michaelis is a PhD student at the International Max Planck Research School for Intelligent Systems in Tübingen, Germany. His PhD project is jointly advised by Alexander S. Ecker (Neural Data Science) and Matthias Bethge (Computational Vision and Neuroscience). He previously received a M.Sc. in Physics from the University of Konstanz after which he changed his field of interest from stimulating neurons with lasers to understanding artificial neural networks.
Acknowledgements
We would like to thank Rich Zemel, Wieland Brendel, Matthias Bethge and Felix Wichmann for collaboration on the article that led to this piece. We would also like to thank Arif Kornweitz for insightful discussions.
If not stated otherwise, figures are from this paper. Feature image is from https://www.pikist.com/free-photo-sjgei.
Citation
For attribution in academic contexts or books, please cite this work as
Geirhos, R., Jacobsen, J.-H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., & Wichmann, F. A. (2020). Shortcut Learning in Deep Neural Networks. arXiv preprint arXiv:2004.07780.
Jörn-Henrik Jacobsen et al., "Shortcuts: Neural Networks Love to Cheat", The Gradient, 2020.
BibTeX citation:
@article{jacobsen2020shortcuts,
author = {Jacobsen, Jörn-Henrik and Geirhos, Robert and Michaelis, Claudio},
title = {Shortcuts: Neural Networks Love To Cheat},
journal = {The Gradient},
year = {2020},
howpublished = {\url{https://thegradient.pub/shortcuts-neural-networks-love-to-cheat/ } },
}
If you enjoyed this piece and want to hear more, subscribe to the Gradient and follow us on Twitter.-



{kind=link}
{kind=link}
{kind=link}
{kind=link}